Как парсить сайт: 20+ инструментов на все случаи жизни
Содержание:
- Зачем это нужно?
- Вред имуществу и убытки
- Как используют полученные данные
- Что такое парсинг сайтов: польза и вред
- Виды парсеров по используемой технологии
- Особенности парсинга веб-сайтов
- Виды парсеров по сферам применения
- Автоматически следовать редиректам с cURL
- Виды парсеров по технологии
- Что такое парсер аудиторий?
- Парсите HTML теги
- Парсить — что это обозначает простыми словами?
- Посмотрите, что делают конкуренты
- Основа работы парсера
- Для чего нужен парсинг сайтов? Парсер заголовков страниц, аудитории, товаров, цен
- Что такое парсинг
- Парсинг – что это значит и как парсить сайты?
Зачем это нужно?
Анализ и сбор информации о трендах на рынке и конкурентах необходим для развития бизнеса. и, если в небольших объемах такой сбор данных можно провести вручную, то, когда речь идет об огромных массивах данных, к примеру, об анализе ассортимента и ценообразования в нескольких онлайн-магазинах конкурентах, сделать это без применения определенного автоматического алгоритма очень сложно.
Для примера, провести ручной анализ пяти правил ценообразования магазинов-конкурентов и внести необходимые данные в таблицу для последующего анализа, действительно, не составит труда. Говоря же о пятидесяти магазинах, проще приобрести программу и провести тот же анализ автоматически.
Вред имуществу и убытки
Начнём с нетипичных и неочевидных вариантов. Казалось бы, при чём здесь вред имуществу, когда речь о программах, делающих что-то в интернете? На самом деле такой подход к вопросу нельзя исключать. Да, информация, сайты, программы — это нематериальные объекты, но серверы, на которых всё работает — вполне себе материальные. Если из-за парсинга что-то случится с сервером, то вполне можно говорить о вреде имуществу. Грубо говоря, если кто-то станет парсить сайт так активно, что сервер задымится и сломается, то можно будет поставить вопрос о возмещении вреда, причинённого имуществу.
нужно как-то оценить вред и доказать, что его размер не взяли с потолка, а посчитали правильно;
нужно доказать, почему парсинг действительно является правонарушением (тут тоже всё не так просто, но некоторые возможные обоснования будут в следующих разделах статьи);
нужно доказать, что вред возник именно из-за парсинга (а не из-за кривой конфигурации сервера и плохой защиты от ботов);
наконец, нужно доказать, что даже если нарушитель и не хотел ничего плохого (то есть не было умысла), но всё равно по-хорошему он мог бы предвидеть последствия, если бы подумал хотя бы в рамках «здравого смысла» (юридически это будет называться «лёгкая неосторожность»).
Кроме того, нарушителя ещё нужно найти, а это тоже та ещё задачка: «я тебя по IP вычислю» — не более чем мем, а в реальности нужно будет в исковом заявлении указать почтовый адрес, причём полиция не подскажет: они розыском по гражданским делам не занимаются. Словом, хотя в теории привлечь к ответственности можно, на практике это один из самых трудных вариантов.
Когда серверы были слабее, вариант с причинением вреда смотрелся чуть реалистичнее. В частности, в конце 1990-х одна американская компания парсила Ebay. Ebay обратился в суд. Основание — парсер делал 100 тысяч запросов в сутки, что составляло 1,5% от общего трафика на сайт. Это привело к дополнительным расходам на обслуживание серверов — следовательно, финансовые потери должны быть возмещены, а парсинг прекращён. Дело в итоге закончилось мировым соглашением (пример я взял из книги «Web Scraping with Python»). Сейчас серверы намного мощнее, так что вряд ли парсинг реально «положит» сайт или как-то ещё приведёт к убыткам для владельца.
Как используют полученные данные
У веб-скрапинга/парсинга очень широкий спектр применений. Например:
1. Отслеживание цен
Собирая информацию о товарах и их ценах, например, на Amazon или других платформах, вы сможете корректировать цены, чтобы опередить конкурентов.
2. Рыночная и конкурентная разведка
Если вы хотите поработать на новом рынке, то сначала нужно оценить свои шансы, а принять взвешенное решение поможет как раз сбор и анализ данных.
3. Модернизация сайтов
Когда компании переносят устаревшие сайты на современные платформы, они используют скрапинг сайта для быстрой и легкой выгрузки данных.
5. Анализ эффективности контента
Блогеры и контентмейкеры используют скрапинг для извлечения статистики о своих постах, видео, твитах в таблицу. Например, в этом видео автор статьи получает данные из его профиля на сайте Medium, используя веб-скрапер:
Данные в таком формате:
- легко сортируются и редактируются;
- всегда доступны для повторного использования;
- можно преобразовать в графики.

Что такое парсинг сайтов: польза и вред
Открыто говорить о том, что «парсят» конкурентов, люди обычно стесняются. При том, что далеко не каждый имеет четкое представление о том, что такое парсинг, в обществе он считается занятием несколько стыдным, и публично порицается. И однако, парсингом занимаются все.
А если и не все поголовно, то все крупные акулы рынка точно.
В веб-программировании процесс обработки и представления данных зовется красивым словом – парсинг. Что это такое простыми словами? По сути – автоматизированный сбор разрозненной информации с сайтов, ее сортировка и выдача в форме структуры (например, таблицы). Сбор данных с сайтов ведет специальная программа – парсер.
Виды парсеров по используемой технологии
Браузерные расширения
Данный вариант следует использовать в том случае. Если требуется собрать достаточно небольшие объемы данных, а среди наиболее популярных парсеров для Google Chrome можно выделить Parsers, Data Scraper, Kimono.
Надстройки для Excel
В данном случае используются макросы, а результаты парсинга, выполненного, например, при помощи ParserOK, выгружаются в XLS или CSV.
Google таблицы
Данные с XML-фидов, равно как и других источников, можно собирать при помощи формулы IMPORTXML, причем тратить время на изучение XPath-запросов не потребуется, в то время как инструмент позволяет собирать с html-страниц практически любые данные. Еще одна формула, а именно IMPORTHTML, обладает не столь широким функционалом, позволяя получить данные из таблиц, равно как и списков на странице.
Особенности парсинга веб-сайтов
Одной из особенностей парсинга веб-сайтов является то, что как правило мы работаем с исходным кодом страницы, т.е. HTML кодом, а не тем текстом, который показывается пользователю. Т.е. при создании регулярного выражения grep нужно основываться на исходном коде, а не на результатах рендеринга. Хотя имеются инструменты и для работы с текстом, получающимся в результате рендеринга веб-страницы – об этом также будет рассказано ниже.
В этом разделе основной упор сделан на парсинг из командной строки Linux, поскольку это самая обычная (и привычная) среда работы для тестера на проникновение веб-приложений. Будут показаны примеры использования разных инструментов, доступных из консоли Linux. Тем не менее, описанные здесь приёмы можно использовать в других операционных системах (например, cURL доступна и в Windows), а также в качестве библиотеки для использования в разных языках программирования.
Подразумевается, что вы понимаете принципы работы командной строки Linux. Если это не так, то рекомендуется ознакомиться с циклом:
- Азы работы в командной строке Linux (часть 1)
- Азы работы в командной строке Linux (часть 2)
- Азы работы в командной строке Linux (часть 3)
Виды парсеров по сферам применения
Для организаторов СП (совместных покупок)
Есть специализированные парсеры для организаторов совместных покупок (СП). Их устанавливают на свои сайты производители товаров (например, одежды). И любой желающий может прямо на сайте воспользоваться парсером и выгрузить весь ассортимент.
Чем удобны эти парсеры:
- интуитивно понятный интерфейс;
- возможность выгружать отдельные товары, разделы или весь каталог;
- можно выгружать данные в удобном формате. Например, в Облачном парсере доступно большое количество форматов выгрузки, кроме стандартных XLSX и CSV: адаптированный прайс для Tiu.ru, выгрузка для Яндекс.Маркета и т. д.
Популярные парсеры для СП:
- SPparser.ru,
- Облачный парсер,
- Турбо.Парсер,
- PARSER.PLUS,
- Q-Parser.
Вот три таких инструмента:
- Marketparser,
- Xmldatafeed,
- ALL RIVAL.
Парсеры для быстрого наполнения сайтов
Такие сервисы собирают названия товаров, описания, цены, изображения и другие данные с сайтов-доноров. Затем выгружают их в файл или сразу загружают на ваш сайт. Это существенно ускоряет работу по наполнению сайта и экономят массу времени, которое вы потратили бы на ручное наполнение.
В подобных парсерах можно автоматически добавлять свою наценку (например, если вы парсите данные с сайта поставщика с оптовыми ценами). Также можно настраивать автоматический сбор или обновление данных по расписания.
Примеры таких парсеров:
- Catalogloader,
- Xmldatafeed,
- Диггернаут.
Автоматически следовать редиректам с cURL
Вы можете дать указание cURL следовать редиректам, т.е. открывать страницу, на которую делает редирект (перенаправление) та страница, которую мы в данный момент пытаемся открыть.
Например, если я попытаюсь открыть сайт следующим образом (обратите внимание на HTTP вместо HTTPS):
curl http://hackware.ru/
То я получу:
<!DOCTYPE HTML PUBLIC "-//IETF//DTD HTML 2.0//EN"> <html><head> <title>302 Found</title> </head><body> <h1>Found</h1> <p>The document has moved <a href="https://hackware.ru/">here</a>.</p> </body></html>
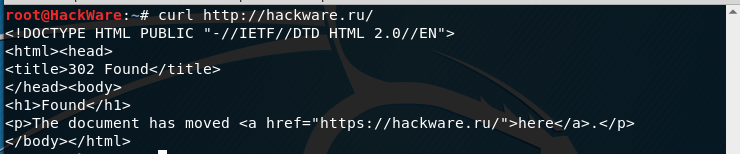
Чтобы curl переходила по перенаправлением используется опция -L:
curl -L http://hackware.ru/
Виды парсеров по технологии
Браузерные расширения
Для парсинга данных есть много браузерных расширений, которые собирают нужные данные из исходного кода страниц и позволяют сохранять в удобном формате (например, в XML или XLSX).
Парсеры-расширения — хороший вариант, если вам нужно собирать небольшие объемы данных (с одной или парочки страниц). Вот популярные парсеры для Google Chrome:
- Parsers;
- Scraper;
- Data Scraper;
- Kimono.
Надстройки для Excel
Программное обеспечение в виде надстройки для Microsoft Excel. Например, ParserOK. В подобных парсерах используются макросы — результаты парсинга сразу выгружаются в XLS или CSV.
Google Таблицы
С помощью двух несложных формул и Google Таблицы можно собирать любые данные с сайтов бесплатно.
Эти формулы: IMPORTXML и IMPORTHTML.
IMPORTXML
Функция использует язык запросов XPath и позволяет парсить данные с XML-фидов, HTML-страниц и других источников.
Вот так выглядит функция:
Функция принимает два значения:
- ссылку на страницу или фид, из которого нужно получить данные;
- второе значение — XPath-запрос (специальный запрос, который указывает, какой именно элемент с данными нужно спарсить).
Хорошая новость в том, что вам не обязательно изучать синтаксис XPath-запросов. Чтобы получить XPath-запрос для элемента с данными, нужно открыть инструменты разработчика в браузере, кликнуть правой кнопкой мыши по нужному элементу и выбрать: Копировать → Копировать XPath.

С помощью IMPORTXML можно собирать практически любые данные с html-страниц: заголовки, описания, мета-теги, цены и т.д.
IMPORTHTML
У этой функции меньше возможностей — с ее помощью можно собрать данные из таблиц или списков на странице. Вот пример функции IMPORTHTML:
Она принимает три значения:
- Ссылку на страницу, с которой необходимо собрать данные.
- Параметр элемента, который содержит нужные данные. Если хотите собрать информацию из таблицы, укажите «table». Для парсинга списков — параметр «list».
- Число — порядковый номер элемента в коде страницы.
Что такое парсер аудиторий?
Если вручную искать всех людей из целевой аудитории с копированием их контактов в специальные таблицы, то это займёт слишком много времени. Часто такие списки состоят из десятков тысяч людей, численность в 2000-3000 человек для многих сегментов является минимальной. Чтобы автоматизировать парсинг, создаются специальные программы – парсеры.
Парсер аудиторий находит пользователей, собирает информацию о них, анализирует, а если человек подходит по указанным заранее параметрам, то его контакты и другие данные записываются в таблицы или списки. Готовый результат парсинга можно скачать в файле.
Кроме того, парсеры могут находить не конкретных людей целевой аудитории, а группы и сообщества в инстаграм, instagram, facebook, где общаются потенциальные клиенты.
Критериями для выбора группы являются:
- ключевые слова в сообщениях пользователей;
- географическое положение аудитории;
- присутствие различных меток;
- интересы аудитории.
Для поиска отдельных клиентов можно анализировать гораздо больший спектр информации:
- имена, фамилии;
- пол, возраст;
- родственные связи, наличие престарелых родителей, а также количество детей (их пол);
- место жительства, место работы;
- должность, профессия, образование;
- подписки на различные группы;
- любимые книги, музыка, фильмы, другие увлечения;
- статус (в браке, в поиске, учёба, карьера и прочее);
- некоторые парсеры могут анализировать фотографии, аудио, видео.
Парсите HTML теги
Если случилось чудо и у сайта нет ни официального API, ни вкусных XHR запросов, ни жирного JSON внизу HTML, если рендеринг браузерами вам тоже не помог, то остается последний, самый нудный и неблагодарный метод. Да, это взять и начать парсить HTML разметку страницы. То есть, например, из достать ссылку. Это можно делать как простыми регулярными выражениями, так и через более умные инструменты (в питоне это BeautifulSoup4 и Scrapy) и фильтры (XPath, CSS-selectors).
Мой единственный совет: постараться минимизировать число фильтров и условий, чтобы меньше переобучаться на текущей структуре HTML страницы, которая может измениться в следующем A/B тесте.

Парсить — что это обозначает простыми словами?
С появлением новых технологий в нашем обиходе появляются новые слова, значения которых многие не знают и не могут понять, что они означают. Много терминов приходит с других языков. В основном в последние десятилетия они приходят в русский язык из англоязычных стран. Одним из таких является слово «парсить«. Так что же это такое?
Определение
Термин «парсить» пришло в русский из английского языка и означает – разбирать, проводить анализ. Это слово употребляют в своей терминологии разработчики Интернет ресурсов, программисты и т. д. В их среде в большинстве случаев означает поиск и копирование чужого контента на свой сайт, а также процедура разбора, проведения анализа статьи. Ещё в информатике это означает – проведение анализа, при котором разрабатываются математические модели сравнения.
Также означает сбор информации в Интернете, используя для этого специально разработанные программы – «парсеры«, которые позволяют сравнивать предложенные сегменты в разработанной базе с теми, что есть в Интернете. Они часто используются аналитиками, экономистами и бизнесменами в разных сегментах экономики.
Для чего применяются
Сбор сведений для исследования рынка
Такая программный продукт может отследить необходимую информацию, что даст специалисту определить, в каком направлении будет развиваться та или иная компания или отрасль в целом, например, в ближайшие полгода. Таким образом, утилита даёт фундамент, базу специалисту для проведения глубокого анализа, что даст компании поднять свой уровень продаж в своём рыночном секторе услуг или производства.
Подобная утилита способна получать информацию от многих источников, которые специализируются на проведении аналитики и компаний по исследованию рынка. И только потом можно будет объединять все полученные сведения для сравнения и проведения глубокого анализа.
Отбор сотрудников или поиск работы
Для работодателя, который динамично разыскивает претендентов в интересах принятия на работу в свою фирму, либо для соискателя, который подыскивает себе работу с определённой должностью, подобная разработка также будет востребована. С её помощью проводится настройка и подборка исходных данных в базе разных применяемых фильтров и результативно извлекать нужное, без обыденного поиска вручную.
Получение сведений
- Так же их применяют, для того чтобы составлять и классифицировать информацию:
- почтовые или электронные адреса,
- контакты с разных веб-сайтов и соцсетей.
Это даёт возможность создавать простые списки контактов и целой сопутствующих данных в интересах бизнеса – о покупателях, посредниках либо изготовителях.
- Изучение стоимости товара в различных онлайн магазинах
- Такие ресурсы могут быть полезны и тем, кто оживлённо пользуется предложениями онлайн магазинов, следит за ценами на продукты питания, разыскивает товары на многих сайтах одновременно.
Самые известные парсеры
https://youtube.com/watch?v=6Anf5nIhuCI
Самые крупные и известные системы, которые занимаются парсером – это, конечно же, Яндекс и Google. Их программы, когда юзер хочет что-то найти во Всемирной паутине и вводит в поисковик, что именно необходимо ему найти, начинают искать из десятков миллионов веб-ресурсов именно то, что нужно юзеру. Выдают ему несколько сотен сайтов на выбранную тему, из которых он ищет необходимую ему информацию.
А перечисленные выше возможности программ для того чтобы «парсить» являются более узкоспециализированными, и их программисты разрабатывают для различных крупных фирм, которые с их помощью определяют свои возможности и конкурентов. Всё это облегчает проведение необходимых мероприятий, так как происходит всё в автоматическом режиме, и специалист может получить всё нужное в виде таблиц или графиков, что упрощает его дальнейшую работу. Ему не нужно тратит драгоценное время на поиск.
Посмотрите, что делают конкуренты
Конкуренты – золотая жила информации. Данные, которые получите в результате парсинга крупных конкурентов, можно использовать в своих интересах. Но и у мелких конкурентов есть чему поучиться.
Чему вы научитесь у крупных конкурентов?
У крупных игроков часто большая аудитория и прочные отношения в отрасли. Данные о работе конкурента помогут понять, что он делает правильно, а что нет.
С помощью парсинга можно узнать:
- посты, которые хорошо работают сейчас;
- посты, которые хорошо работали раньше, а теперь не очень;
- хештеги для бизнеса;
- активных подписчиков конкурента.
Вы можете спарсить подписчиков конкурента и найти похожие аудитории в соцсети. Это поможет расширить базу потенциальных покупателей.
Чему вы научитесь у мелких конкурентов?
Мелких конкурентов часто игнорируют, так как они не представляют угрозы. Нередко у них такая же или меньшая доля рынка по сравнению с вашим бизнесом. Но, возможно, именно эти конкуренты:
- инновационные на своем рынке;
- реализуют инновации с помощью своих продуктов и услуг;
- увеличивают долю рынка.
Продвигать что-то новое с небольшим бюджетом – не самое легкое дело. Полезно увидеть, где и как эти мелкие конкуренты набирают свою аудиторию. Возможно, они используют методы для увеличения охвата и продаж, которые пригодились бы и вам.
Конкуренты всегда делают за вас часть работы методом проб и ошибок. Спарсите и проанализируйте данные, чтобы лучше понять, как можете улучшить свой продукт, маркетинг и взаимодействие с пользователями.
Основа работы парсера
Конечно же, парсеры не читают текста, они всего лишь сравнивают предложенный набор слов с тем, что обнаружили в интернете и действуют по заданной программе. То, как поисковый робот должен поступить с найденным контентом, написано в командной строке, содержащей набор букв, слов, выражений и знаков программного синтаксиса. Такая командная строка называется «регулярное выражение». Русские программисты используют жаргонные слова «маска» и «шаблон».
Чтобы парсер понимал регулярные выражения, он должен быть написан на языке, поддерживающем их в работе со строками. Такая возможность есть в РНР, Perl. Регулярные выражения описываются синтаксисом Unix, который хотя и считается устаревшим, но широко применяется благодаря свойству обратной совместимости.
Синтаксис Unix позволяет регулировать активность парсинга, делая его «ленивым», «жадным» и даже «сверхжадным». От этого параметра зависит длина строки, которую парсер копирует с веб-ресурса. Сверхжадный парсинг получает весь контент страницы, её HTML-код и внешнюю таблицу CSS.
Для чего нужен парсинг сайтов? Парсер заголовков страниц, аудитории, товаров, цен
Для чего нужен парсинг сайтов? Рассмотрим несколько примеров:
- Помогает собирать информацию о конкурентах. К примеру, с помощью парсинга вы сможете быстро узнать, какие цены и товары есть в магазине. Затем название товаров и цен можно применить для своего магазина.
- Парсинг структуры статей и сайта. Эта деятельность развивает такое направление, как копирайтинг или блоггинг. То есть, человек может подсмотреть, например, структуру статьи у конкурентов и ее улучшить. Если, например, у вас нет структуры сайта, то ее так же можно спарсить с сайтов-конкурентов.
- Парсинг аудитории. В этом случае, вы сможете выявить информацию о покупателях, которые будут покупать ваши товары или услуги. Таким образом, узнаете потребности клиентов, спрос на товар.
Еще есть технический парсинг, который направлен на выявление ошибок сайта, блога и их устранение.
Что такое парсинг
Парсинг (parsing) – это буквально с английского «разбор», «анализ». Под парсингом обычно имеют ввиду нахождение, вычленение определённой информации.
Парсинг сайтов может использоваться при создании сервиса, а также при тестировании на проникновение. Для пентестера веб-сайтов, навык парсинга сайтов является базовыми, т.е. аудитор безопасности (хакер) должен это уметь.
Умение правильно выделить информацию зависит от мастерства владения регулярными выражениями и командой grep (очень рекомендую это освоить – потрясающее испытание для мозга!). В этой же статье будут рассмотрены проблемные моменты получения данных, поскольку все сайты разные и вас могут ждать необычные ситуации, которые при первом взгляде могут поставить в тупик.
В качестве примера парсинга сайтов, вот одна единственная команда, которая получает заголовки последних десяти статей, опубликованных на HackWare.ru:
curl -s https://hackware.ru/ | grep -E -o '<h3 class=ftitle>.*</h3>' | sed 's/<h3 class=ftitle>//' | sed 's/<\/h3>//'

Подобным образом можно автоматизировать получение и извлечение любой информации с любого сайта.
Парсинг – что это значит и как парсить сайты?
Привет, ребят. Опережая события, хочу предупредить, что для того, чтобы парсить сайты необходимо владеть хотя бы php. У меня есть интересная статья о том, как стать php программистом. И все же, что такое парсинг?
Начнем с определения. В этой статье речь пойдет о парсинге сайтов. Попробую объяснить как можно проще и доходчивее.
Парсинг, что это значит: слово понятное дело пришло от английского parse -по факту это означает разбор содержимого страницы на отдельные составляющие. Этот процесс происходит автоматически благодаря специальным программам (парсеров).
В пример парсера можно привести поисковые системы. Их роботы буквально считывают информацию с сайтов, хранят данные об их содержимом в своих базах и когда вы вбиваете поисковой запрос они выдают самые подходящие и актуальные сайты.
Парсинг? Зачем он нужен?
Представьте себе, что вы создали сайт, не одностраничный продающий сайт, а крупный портал с множеством страниц. У Вас есть красивый дизайн, панель управления и возможно даже разделы, которые вы хотите видеть, но где взять информацию для наполнения сайта?
В интернете – где ж еще. Однако не все так просто.
Приведу в пример лишь 2 проблемы при наполнении сайта контентом:
- Серьезный объём информации. Если Вы хотите обойти конкурентов, хотите чтобы Ваш ресурс был популярен и успешен, Вам просто необходимо публиковать огромное количество информации на своем ресурсе. Сегодняшняя тенденция показывает, что контента нужно больше чем возможно заполнить вручную.
- Постоянные обновления. Информацию которая все время меняется и которой как мы уже сказали большие объемы, невозможно обновлять вовремя и обслуживать. Некоторые типы информации меняются ежеминутно и обновлять её руками невозможно и не имеет смысла.
И тут нам приходит на помощь старый добрый парсинг! Та-дааааам!Это самое оптимальное решение, чтобы автоматизировать процесс изменения и сбора контента.
- быстроизучит тысячи сайтов;
- аккуратно отделит нужную информацию от программного кода;
- безошибочновыберет самые сливки и выкинет ненужное;
- эффективносохранит конечный результат в нужном виде.
Тут я буду краток, скажу лишь, что для этого можно использовать практически любой язык программированию, который мы используем при разработке сайтов. Это и php, и C++, и python и т.д.
Поскольку наиболее распространенным среди веб-разработчиков является php, хочу поделиться с Вами сайтом, на котором очень доступно объясняется как парсить сайты при помощи php скрипта http://agubtor.autoorder.biz/l/m2
Поскольку мой проект тоже совсем молодой, я хочу попробовать этот метод.
Ах да, чуть не забыл. Как всегда, для тех кто хочет разобраться в теме до уровня мастерства, вот ссылка на описание видеокурса http://agubtor.autoorder.biz/l/m3
А что Вы думаете об автоматизации сбора информации? Действительно ли без этого не обойтись или лучше наполнять сайт настоящим эксклюзивным контентом?
