Xml httprequest: описание, применение, частые проблемы
Содержание:
§Uploading Data with XHR
Uploading data via XHR is just as simple and efficient for all data
types. In fact, the code is effectively the same, with the only
difference that we also pass in a data object when calling
send() on the XHR request. The rest is handled by the browser:
var xhr = new XMLHttpRequest();
xhr.open('POST','/upload');
xhr.onload = function() { ... };
xhr.send("text string");
var formData = new FormData();
formData.append('id', 123456);
formData.append('topic', 'performance');
var xhr = new XMLHttpRequest();
xhr.open('POST', '/upload');
xhr.onload = function() { ... };
xhr.send(formData);
var xhr = new XMLHttpRequest();
xhr.open('POST', '/upload');
xhr.onload = function() { ... };
var uInt8Array = new Uint8Array();
xhr.send(uInt8Array.buffer);
-
Upload a simple text string to the server
-
Create a dynamic form via FormData API
-
Upload multipart/form-data object to the server
-
Create a typed array (ArrayBuffer) of unsigned, 8-bit integers
-
Upload chunk of bytes to the server
The XHR send() method accepts one of ,
, , ,
, or objects, automatically
performs the appropriate encoding, sets the appropriate HTTP
content-type, and dispatches the request. Need to send a binary blob or
upload a file provided by the user? Simple: grab a reference to the
object and pass it to XHR. In fact, with a little extra work, we can also
split a large file into smaller chunks:
var blob = ...;
const BYTES_PER_CHUNK = 1024 * 1024;
const SIZE = blob.size;
var start = 0;
var end = BYTES_PER_CHUNK;
while(start < SIZE) {
var xhr = new XMLHttpRequest();
xhr.open('POST', '/upload');
xhr.onload = function() { ... };
xhr.setRequestHeader('Content-Range', start+'-'+end+'/'+SIZE);
xhr.send(blob.slice(start, end));
start = end;
end = start + BYTES_PER_CHUNK;
}
-
An arbitrary blob of data (binary or text)
-
Set chunk size to 1 MB
-
Iterate over provided data in 1MB increments
-
Advertise the uploaded range of data (start-end/total)
-
Upload 1 MB slice of data via XHR
XHR does not support request streaming, which means that we must
provide the full payload when calling send(). However, this
example illustrates a simple application workaround: the file is split
and uploaded in chunks via multiple XHR requests. This implementation
pattern is by no means a replacement for a true request streaming API,
but it is nonetheless a viable solution for some applications.
Response Type
We can use property to set the response format:
- (default) – get as string,
- – get as string,
- – get as (for binary data, see chapter ArrayBuffer, binary arrays),
- – get as (for binary data, see chapter Blob),
- – get as XML document (can use XPath and other XML methods) or HTML document (based on the MIME type of the received data),
- – get as JSON (parsed automatically).
For example, let’s get the response as JSON:
Please note:
In the old scripts you may also find and even properties.
They exist for historical reasons, to get either a string or XML document. Nowadays, we should set the format in and get as demonstrated above.
Асинхронные запросы
Если вы используете асинхронный режим , то после того, как данные будут получены, будет вызвана функция обработчик. Это позволяет браузеру работать нормально пока ваш запрос будет обрабатываться.
.
2 строка. 3 параметр метода установлен как для того, чтобы явно указать, что этот запрос будет обрабатываться асинхронно.
3 строка. Создаётся функция обработчик события . Этот обработчик следить за параметром , для того, чтобы определить завершена ли передача данных и если это так и HTTP статус 200, то полученные данные выводятся в консоль. А если в результате передачи данных возникла ошибка, то сообщение об ошибки будет выведено в консоль.
15 строка. Происходит инициализация отправки запроса. Функция обработчик будет вызываться каждый раз, как будет происходить изменения состояния данного запроса.
В разных сценариях существует необходимость принимать внешние файлы (ответ от сервера, к примеру, json файл). Это стандартная функция, которая использует объект асинхронно, чтобы передать прочитанный контент в специальную функцию обработчик.
Использование:
Сигнатура вспомогательной функции следующая: 1 аргумент — URL адрес для запроса (через HTTP GET), 2 аргумент — функция, которая будет вызвана после успешного выполнения ajax запроса и 3 аргумент — список аргументов, которые будут передаваться через XHR объект в функцию, которая была указана во 2 аргументе.
Строка 1 определяет функцию, которая будет вызвана, когда ajax запрос завершиться успешно. В свою очередь это вызовет функции callback, которая была указана в вызове функции (то есть функция ) которая была обозначена как свойство объекта (строка 11). Дополнительные аргументы, которые были указаны при вызове функции , подставляются в вызов callback функции.
Строка 5 определяет функцию, которая будет вызвана в случаи, если ajax запрос не сможет завершиться успешно.
Строка 11 сохраняет в объекте функцию, которая будет вызвана после успешного завершения ajax запроса. (эта функция передаётся 2 аргументов в вызове функции ).
12 строка срезает псевдомассив аргументов, который был передан при вызове функции . Начиная с 3 аргумента все аргументы будут хранится в массиве arguments объекта , который передаётся в функцию и в конечном итоге будут использованы при вызове функции , которая будет вызвана функцией .
Строка 15 устанавливает для 3 параметра, что явно указывает на то, что запрос будет выполняться асинхронно.
Строка 16 инициализирует запрос.
При использовании асинхронных запросов, можно установить максимальное время ожидания ответа от сервера. Это делается путём установки значения свойства объекта, как показано ниже:
Отметим, что в код была добавлена функция обработчик события .
Использование:
2 аргумент функции устанавливает время ожидание равное 2000ms.
Внимание: Поддержка была добавлена начиная с Gecko 12.0
Использование XMLHTTPRequest
Различают два использования XmlHttpRequest. Первое — самое простое, синхронное.
Синхронный XMLHttpRequest
В этом примере через XMLHTTPRequest с сервера запрашивается страница http://example.org/, и текст ответа сервера показывается через alert().
var xmlhttp = getXmlHttp()
xmlhttp.open('GET', '/xhr/test.html', false);
xmlhttp.send(null);
if(xmlhttp.status == 200) {
alert(xmlhttp.responseText);
}
Здесь сначала создается запрос, задается открытие () синхронного соединение с адресом /xhr/test.html и запрос отсылается с null,
т.е без данных.
При синхронном запросе браузер «подвисает» и ждет на строчке 3, пока сервер не ответит на запрос. Когда ответ получен — выполняется строка 4, код ответа сравнивается с 200 (ОК), и при помощи alert
печатается текст ответа сервера. Все максимально просто.
Свойство responseText получит такой же текст страницы, как браузер, если бы Вы в перешли на /xhr/test.html. Для сервера
GET-запрос через XmlHttpRequest ничем не отличается от обычного перехода на страницу.
Асинхронный XMLHttpRequest
Этот пример делает то же самое, но асинхронно, т.е браузер не ждет выполнения запроса для продолжения скрипта. Вместо этого к свойству onreadystatechange подвешивается
функция, которую запрос вызовет сам, когда получит ответ с сервера.
var xmlhttp = getXmlHttp()
xmlhttp.open('GET', '/xhr/test.html', true);
xmlhttp.onreadystatechange = function() {
if (xmlhttp.readyState == 4) {
if(xmlhttp.status == 200) {
alert(xmlhttp.responseText);
}
}
};
xmlhttp.send(null);
Асинхронность включается третьим параметром функции open. В отличие от синхронного запроса, функция send() не останавливает
выполнение скрипта, а просто отправляет запрос.
Запрос xmlhttp регулярно отчитывается о своем состоянии через вызов функции xmlhttp.onreadystatechange. Состояние под номером 4 означает конец выполнения, поэтому функция-обработчик
при каждом вызове проверяет — не настало ли это состояние.
Вообще, список состояний readyState такой:
- 0 — Unitialized
- 1 —
- 2 — Loaded
- 3 — Interactive
- 4 — Complete
Состояния 0-2 вообще не используются.
Вызов функции с состоянием Interactive в теории должен происходить каждый раз при получении очередной порции данных от сервера.
Это могло бы быть удобным для обработки ответа по частям, но Internet Explorer не дает доступа к уже полученной части ответа.
Firefox дает такой доступ, но для обработки запроса по частям состояние Interactive все равно неудобно из-за сложностей обнаружения ошибок соединения.
Поэтому Interactive тоже не используется.
На практике используется только последнее, Complete.
Если хотите углубиться в тонкости багов браузеров c readyState, отличными от 4, то многие из них рассмотрены в статье на.
Не используйте синхронные запросы
Синхронные запросы применяются только в крайнем случае, когда кровь из носу необходимо дождаться ответа сервера до продолжения скрипта. В 999 случаях из 1000
можно использовать асинхронные запросы. При этом общий алгоритм такой:
- Делаем асинхронный запрос
- Рисуем анимированную картинку или просто запись типа «Loading…»
- В onreadystatechange при достижении состояния 4 убираем Loading и, в зависимости от status вызываем обработку ответа или ошибки.
Кроме того, иногда полезно ставить ограничение на время запроса. Например, хочется генерировать ошибку, если запрос висит более 10 секунд.
Для этого сразу после send() через setTimeout ставится вызов обработчика ошибки, который очищается при получении ответа и обрывает запрос с генерацией ошибки,
если истекли 10 секунд.
Таймаут на синхронный запрос ставить нельзя, браузер может висеть долго-долго.. А вот на асинхронный — пожалуйста.
Этот пример демонстрирует такой таймаут.
var xmlhttp = getXmlHttp()
xmlhttp.open("POST", "/someurl", true);
xmlhttp.onreadystatechange=function(){
if (xmlhttp.readyState != 4) return
clearTimeout(timeout) // очистить таймаут при наступлении readyState 4
if (xmlhttp.status == 200) {
// Все ок
...
alert(xmlhttp.responseText);
...
} else {
handleError(xmlhttp.statusText) // вызвать обработчик ошибки с текстом ответа
}
}
xmlhttp.send("a=5&b=4");
// Таймаут 10 секунд
var timeout = setTimeout( function(){ xmlhttp.abort(); handleError("Time over") }, 10000);
function handleError(message) {
// обработчик ошибки
...
alert("Ошибка: "+message)
...
}
§Monitoring Download and Upload Progress
Network connectivity can be intermittent, and latency and bandwidth
are highly variable. So how do we know if an XHR request has succeeded,
timed out, or failed? The XHR object provides a convenient API for
listening to progress events (), which indicate the current status
of the request.
| Event type | Description |
Times fired |
|---|---|---|
| loadstart | Transfer has begun |
once |
| progress | Transfer is in progress |
zero or more |
| error | Transfer has failed |
zero or once |
| abort | Transfer is terminated |
zero or once |
| load | Transfer is successful |
zero or once |
| loadend | Transfer has finished | once |
Table 15-1. XHR progress events
Each XHR transfer begins with a loadstart and finishes with a
loadend event, and in between, one or more additional events are
fired to indicate the status of the transfer. Hence, to monitor progress
the application can register a set of JavaScript event listeners on the
XHR object:
var xhr = new XMLHttpRequest();
xhr.open('GET','/resource');
xhr.timeout = 5000;
xhr.addEventListener('load', function() { ... });
xhr.addEventListener('error', function() { ... });
var onProgressHandler = function(event) {
if(event.lengthComputable) {
var progress = (event.loaded / event.total) * 100;
...
}
}
xhr.upload.addEventListener('progress', onProgressHandler);
xhr.addEventListener('progress', onProgressHandler);
xhr.send();
-
Set request timeout to 5,000 ms (default: no timeout)
-
Register callback for successful request
-
Register callback for failed request
-
Compute transfer progress
-
Register callback for upload progress events
-
Register callback for download progress events
Either the load or error event will fire once to
indicate the final status of the XHR transfer, whereas the
progress event can fire any number of times and provides a
convenient API for tracking transfer status: we can compare the
loaded attribute against total to estimate the amount
of transferred data.
Создание XML с использованием JavaScript
Существует несколько различных способов, как вызвать функцию loadXMLDoc. Например, берется ссылка на форму в качестве первого параметра, а затем две дополнительные переменные.
Успешный вызов loadXMLDoc возвращает значение «верно». OnSubmit обработчик будет возвращать «ложь». Отменяя действие по умолчанию, он представит событие, которое в противном случае вызвало бы форму. Дальнейшее выполнение происходит с помощью Ajax, поэтому браузеру не нужно загружать новую страницу. Неудачный вызов loadXMLDoc возвращает значение «ложь». OnSubmit обработчик будет возвращать «верно», в результате чего форма будет представлена в обычном режиме. Дальнейшее выполнение проходит с помощью nonAjaxTarget.html.

Выполняется функция предотвращения кэширования значений ответа Javascript xmlhttprequest cookie. Некоторые браузеры будут кэшировать GET-запросы, выполненные с использованием XHR, чтобы после первого вызова последующие из одного и того же сценария просто перезагружали первый ответ. Чтобы обойти это, нужно добавить случайную строку или временную метку к запросу, как показано на фото ниже:

Если сценарий всегда возвращает один и тот же ответ для заданных параметров, то не нужно беспокоиться об этом, так как используется кеширование для ускорения приложения.
Подводя итог тому, насколько просто работать с Ajax с использованием этой структуры, нужно только выполнить следующие действия:
- Настроить сценарий на стороне сервера, чтобы принять параметры GET или POST или COOKIE и вернуть действительный XML-файл.
- Указать файл xmlhttp.js JS на странице.
- Использовать JavaScript для вызова.
Обратные вызовы Ajax могут быть выполнены путем создания экземпляра объекта XHR в клиентском JScript. Javascript XMLHttpRequest get может использоваться для прямого вызова серверных объектов, таких как страницы и веб-службы. Они будут сохранять или возвращать данные.
Ajax первоначально был аббревиатурой для асинхронного JS и XML. «Асинхронный» означает, что несколько событий происходят совершенно независимо друг от друга. Как только клиент инициализирует обратный вызов Ajax для сервера, ему не нужно ждать ответа, так как он может продолжать использовать веб-приложение во время обработки запроса. После этого сервер отправит ответ клиенту, а тот обработает его по мере необходимости.
Просмотры:
17
GET и POST-запросы. Кодировка.
Во время обычного submit’а формы браузер сам кодирует значения полей и составляет тело GET/POST-запроса для посылки на сервер. При работе через XmlHttpRequest, это нужно делать самим, в javascript-коде. Большинство проблем и вопросов здесь связано с непониманием, где и какое кодирование нужно осуществлять.
Вначале рассмотрим общее кодирование запросов, ниже — правильную работу с русским языком для windows-1251.
Существуют два вида кодирования HTTP-запроса. Основной — urlencoded, он же — стандартное кодирование URL. Пробел представляется как %20, русские буквы и большинство спецсимволов кодируются, английские буквы и дефис оставляются как есть.
Способ, которым следует кодировать данные формы при submit’е, задается в ее HTML-таге:
<form method="get"> // метод GET с кодировкой по умолчанию <form method="post" enctype="application/x-www-form-urlencoded"> // enctype явно задает кодировку <form method="post"> // метод POST с кодировкой по умолчанию (urlencoded, как и предыдущая форма)
Если форма submit’ится обычным образом, то браузер сам кодирует (urlencode) название и значение каждого поля данных ( и т.п.) и отсылает форму на сервер в закодированном виде.
Формируя XmlHttpRequest, мы должны формировать запрос «руками», кодируя поля функцией .
Конечно, пропускать через encodeURIComponent стоит только те переменные, в которых могут быть спецсимволы или не английские буквы, т.е которые и будут как раз закодированы.
Например, для посылки GET-запроса с произвольными параметрами name и surname, их необходимо закодировать вот так:
// Пример с GET
...
var params = 'name=' + encodeURIComponent(name) + '&surname=' + encodeURIComponent(surname)
xmlhttp.open("GET", '/script.html?'+params, true)
...
xmlhttp.send(null)
В методе POST параметры передаются не в URL, а в теле, посылаемом через . Поэтому нужно указывать не в адресе, а при вызове
Кроме того, при POST обязателен заголовок Content-Type, содержащий кодировку. Это указание для сервера — как обрабатывать (раскодировать) пришедший запрос.
// Пример с POST
...
var params = 'name=' + encodeURIComponent(name) + '&surname=' + encodeURIComponent(surname)
xmlhttp.open("POST", '/script.html', true)
xmlhttp.setRequestHeader('Content-Type', 'application/x-www-form-urlencoded')
...
xmlhttp.send(params)
Заголовки Content-Length, Connection в POST-запросах, хотя их и содержат некоторые «руководства», обычно не нужны. Используйте их, только если Вы действительно знаете, что делаете.
Запросы multipart/form-data
Второй способ кодирования — это отсутствие кодирования. Например, кодировать не нужно для пересылки файлов. Он указывается в форме (только для POST) так:
<form method="post" enctype="multipart/form-data">
В этом случае при отправке данных на сервер ничего не кодируется. А сервер, со своей стороны, посмотрев на Content-Type(=multipart/form-data), поймет, что пришло.
Возможности XmlHttpRequest позволяют создать запрос с любым телом. Например, можно вручную сделать POST-запрос, загружающий на сервер файл. Функционал создания
таких запросов есть, в частности, во фреймворке . Но можно реализовать его и самому, прочитав о нужном формате тела POST и заголовках.
Кодировка (языковая)
Если Вы используете только UTF-8 — пропустите эту секцию.
Все идущие на сервер параметры GET/POST, кроме случая multipart/form-data, кодируются в UTF-8. Не в кодировке страницы, а именно в UTF-8. Поэтому, например, в PHP их нужно при необходимости перекодировать функцией iconv.
<?php
// ajax.php
$name = iconv('UTF8','CP1251',$_GET);
?>
С другой стороны, ответ с сервера браузер воспринимает именно в той кодировке, которая указана в заголовке ответа Content-Type. Т.е, опять же, в PHP, чтобы браузер воспринял ответ в windows-1251 и нормально отобразил данные на странице в windows-1251,
нужно послать заголовок с кодировкой в php-коде, например так:
<?php
// ajax.php
header('Content-Type: text/plain; charset=utf-8');
?>
Или же, такой заголовок должен добавить сервер. Например, в apache автоматически добавляется кодировка опцией:
# в конфиге апача AddDefaultCharset windows-1251
Кодировка urlencoded
Основной способ кодировки запросов – это urlencoded, то есть – стандартное кодирование URL.
Например, форма:
Здесь есть два поля: и .
Браузер перечисляет такие пары «имя=значение» через символ амперсанда и, так как метод GET, итоговый запрос выглядит как .
Все символы, кроме английских букв, цифр и заменяются на их цифровой код в UTF-8 со знаком %.
Например, пробел заменяется на , символ на , русские буквы кодируются двумя байтами в UTF-8, поэтому, к примеру, заменится на .
Например, форма:
Будет отправлена так: .
в JavaScript есть функция encodeURIComponent для получения такой кодировки «вручную»:
Эта кодировка используется в основном для метода GET, то есть для передачи параметра в строке запроса. По стандарту строка запроса не может содержать произвольные Unicode-символы, поэтому они кодируются как показано выше.
Частые проблемы¶
Кеширование
Многие браузеры поддерживают кеширование ответов на XmlHttpRequest запросы. При этом реализации кеширования немного разные.
Например, при повторном XmlHttpRequest на тот же URL, Firefox посылает запрос с заголовком «» со значением, указанным в заголовке «» предыдущего ответа.
А Internet Explorer делает так, только когда кешированный ответ устарел, т. е. после времени из заголовка «Expires» предыдущего ответа. Поэтому, кстати, многие думают, что Internet Explorer вообще не очищает кеш ответов.
Самое простое решение проблемы — просто убрать кеширование. Например, при помощи заголовков, или добавлением случайного параметра в URL типа:
Есть, однако, ряд случаев, когда кеширование XMLHttpRequest браузером полезно, улучшает время ответа и экономит трафик.
Пример демонстрирует универсальный код работы с кешем для Internet Explorer и Firefox.
В Internet Explorer, если запрос возвращается из кеша без перепроверки, заголовок — пустая строка. Поэтому нужно сделать дополнительный запрос, который на самом деле никакой не дополнительный, т. к. текущий возвращен из кеша.
Ссылку на кешированый запрос сохраняем, т. к. если код ответа дополнительного запроса — «», то его тело станет пустой строкой («»), и нужно будет вернуться к кешированному объекту. Более эффективным, впрочем, будет не создавать новый объект , а сохранить данные из существующего и использовать заново его же.
Пример выше опирается на то, что сервер всегда выдает заголовок «», что верно для большинства конфигураций. В нем делается синхронный запрос. В асинхронном случае, проверка на Date и т. д. нужно делать после получения ответа в функции-обработчике .
Повторное использование объекта XmlHttpRequest
В Internet Explorer, если вызван после установки , может быть проблема с повторным использованием этого XmlHttpRequest.
Чтобы использовать заново XmlHttpRequest, сначала вызывайте метод , а затем — присваивайте . Это нужно потому, что IE неявно очищает объект XmlHttpRequest в методе , если его статус «».
Вызывать для перенаправления запроса на другой URL не нужно, даже если текущий запрос еще не завершился.
Утечки памяти
В Internet Explorer объект XmlHttpRequest принадлежит миру DOM/COM, а Javascript-функция — миру Javascript. Вызов r неявную круговую связь: ссылается на функцию через , а функция, через область видимости — видит (ссылается на) .
Невозможность обнаружить и оборвать такую связь во многих (до IE 6,7 редакции июня 2007?) версиях Internet Explorer приводит к тому, что XmlHttpRequest вместе с ответом сервера, функция-обработчик, и всё замыкание прочно оседают в памяти до перезагрузки браузера.
Чтобы этого избежать, ряд фреймворков (YUI, dojo…) вообще не ставят , а вместо этого через проверяют его каждые 10 миллисекунд. Это разрывает круговую связку <-> , и утечка памяти не грозит даже в самых глючных браузерах.
«Непростые» запросы
В кросс-доменном можно указать не только , но и любой другой метод, например , .
Когда-то никто и не думал, что страница сможет сделать такие запросы. Поэтому ряд веб-сервисов написаны в предположении, что «если метод – нестандартный, то это не браузер». Некоторые веб-сервисы даже учитывают это при проверке прав доступа.
Чтобы пресечь любые недопонимания, браузер использует предзапрос в случаях, когда:
- Если метод – не GET / POST / HEAD.
- Если заголовок имеет значение отличное от , или , например .
- Если устанавливаются другие HTTP-заголовки, кроме , , .
…Любое из условий выше ведёт к тому, что браузер сделает два HTTP-запроса.
Первый запрос называется «предзапрос» (английский термин «preflight»). Браузер делает его целиком по своей инициативе, из JavaScript мы о нём ничего не знаем, хотя можем увидеть в инструментах разработчика.
Этот запрос использует метод . Он не содержит тела и содержит название желаемого метода в заголовке , а если добавлены особые заголовки, то и их тоже – в .
Его задача – спросить сервер, разрешает ли он использовать выбранный метод и заголовки.
На этот запрос сервер должен ответить статусом 200, без тела ответа, указав заголовки и, при необходимости, .
Дополнительно он может указать , где – количество секунд, на которые нужно закэшировать разрешение. Тогда при последующих вызовах метода браузер уже не будет делать предзапрос.
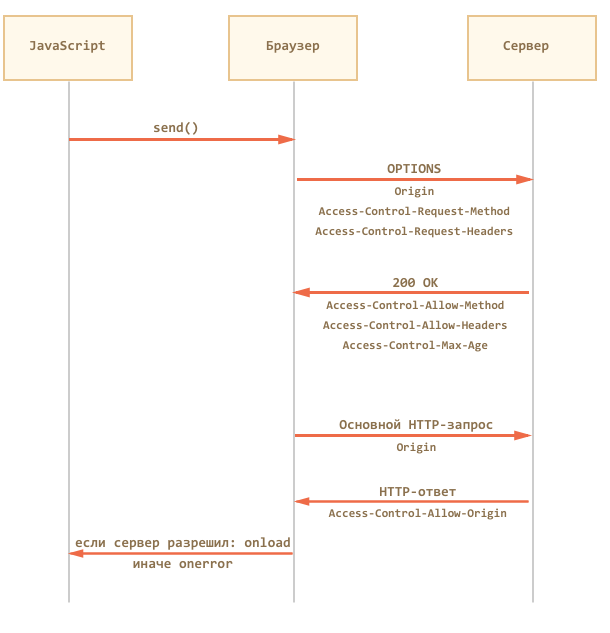
Давайте рассмотрим предзапрос на конкретном примере.
Рассмотрим запрос , который используется в протоколе WebDAV для управления файлами через HTTP:
Этот запрос «непростой» по двум причинам (достаточно было бы одной из них):
- Метод .
- Заголовок .
Поэтому браузер, по своей инициативе, шлёт предварительный запрос :
Обратим внимание на детали:
- Адрес – тот же, что и у основного запроса: .
- Стандартные заголовки запроса , , присутствуют.
- Кросс-доменные специальные заголовки запроса:
- – домен, с которого сделан запрос.
- – желаемый метод.
- – желаемый «непростой» заголовок.
На этот запрос сервер должен ответить статусом 200, указав заголовки и .
Но в протоколе WebDav разрешены многие методы и заголовки, которые имеет смысл сразу перечислить в ответе:
Ответ должен быть без тела, то есть только заголовки.
Браузер видит, что метод – в числе разрешённых и заголовок – тоже, и дальше он шлёт уже основной запрос.
При этом ответ на предзапрос он закэширует на 86400 сек (сутки), так что последующие аналогичные вызовы сразу отправят основной запрос, без .
Основной запрос браузер выполняет уже в «обычном» кросс-доменном режиме:
Ответ сервера, согласно спецификации , может быть примерно таким:
Так как содержит правильный домен, то браузер вызовет и запрос будет завершён.
Объект XMLHttpRequest
Краеугольным камнем Ajax является объект XMLHttpRequest. Этот объект чрезвычайно полезен и обманчиво прост. По сути, он позволяет асинхронно отправлять запросы серверу и получать результаты в виде текста. А решение о том, что запрашивать, как обрабатывать запрос на стороне сервера и что возвращать клиенту, возлагается на разработчика.
Хотя современные браузеры предоставляют широкую поддержку объекта XMLHttpRequest, существуют тонкие различия в способе получения к нему доступа. В некоторых браузерах, включая Internet Explorer 7, Firefox, Safari и Opera, объект XMLHttpRequest реализован в виде собственного объекта JavaScript. В версиях, предшествующих Internet Explorer 7, он реализован как объект ActiveX. Вследствие этих различий код JavaScript должен быть достаточно интеллектуальным, чтобы использовать правильный подход при создании экземпляра XMLHttpRequest. Ниже приведен клиентский код JavaScript, который Microsoft применяет при решении этой задачи для клиентской функции обратного вызова:
Отправка запроса
Для отправки запроса с помощью объекта XMLHttpRequest будут использоваться два метода: open() и send().
Метод open() устанавливает вызов — он определяет запрос, который требуется отправить серверу. У него есть два обязательных параметра — тип команды HTTP (GET, POST или PUT) и URL-адрес. Например:
Дополнительно можно предоставить третий параметр, который указывает, должен ли запрос выполняться асинхронно, и еще два параметра, чтобы предоставить информацию об имени пользователя и пароле для аутентификации. Однако применение параметров имени пользователя и пароля маловероятно, поскольку эта информация не может быть безопасно жестко закодирована в коде JavaScript. Клиентский код никогда не может служить подходящим местом для реализации функций обеспечения безопасности.
По умолчанию все запросы, выполняемые с помощью объекта XMLHttpRequest, являются асинхронными, И в основном нет причин изменять это поведение. Если решите выполнять вызов синхронно, с тем же успехом можно инициировать обратную отправку — в конце концов, пользователь будет неспособен сделать что-либо, пока страница заморожена и ожидает ответа. Отсутствие асинхронности означает отсутствие Ajax.
Метод send() отправляет запрос. Если запрос является асинхронным, он выполняет возврат немедленно:
Метод send() принимает единственный необязательный строковый параметр. Его можно применять для предоставления дополнительной информации, отправляемой с запросом, такой как значения, которые отправляются с запросом POST.
Обработка ответа
Очевидно, что был упущен один нюанс. Мы выяснили, как отправить запрос, но как обработать ответ? Секрет в том, чтобы присоединить обработчик события, используя свойство onreadystatechange. Это свойство указывает на клиентскую функцию JavaScript, которая вызывается, когда запрос завершен и данные доступны:
Конечно, обработчик события должен быть присоединен до вызова метода send() для запуска запроса.
Когда ответ возвращен с сервера и функция инициирована, необходимую информацию можно извлечь из объекта xmlRequest через свойства responseText и responseXML. Свойство responseText предоставляет все содержимое как одну длинную строку. Свойство responseXML возвращает содержимое в виде дерева узловых объектов.
Несмотря на то что название Ajax подразумевает XML-содержимое, из сервера можно также вернуть что-нибудь другое, в том числе простой текст. Например, если сервер возвращает единственный фрагмент данных, нет никакого смысла помещать его в полный XML-документ.
