Уравнение нелинейной регрессии
Содержание:
- Сохранение шаблона диаграммы в Excel
- Линейная регрессия в Excel
- Основные задачи и виды регрессии
- Пример 1
- Расчет коэффициента корреляции
- Разбор результатов анализа
- Линейная регрессия в программе Excel
- Проверка общего качества уравнения множественной регрессии
- Что такое коэффициент корреляции?
- Что объясняет регрессия?
- Матрица парных коэффициентов корреляции в Excel
Сохранение шаблона диаграммы в Excel
Если созданный график действительно Вам нравится, то можно сохранить его в качестве шаблона (.crtx файла), а затем применять этот шаблон для создания других диаграмм в Excel.
Как создать шаблон диаграммы
В Excel 2013 и 2016, чтобы сохранить график в качестве шаблона, щелкните правой кнопкой мыши по диаграмме и в выпадающем меню выберите Сохранить как шаблон (Save as Template):
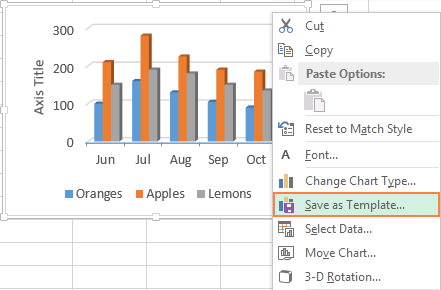
В Excel 2010 и более ранних версиях, функция Сохранить как шаблон (Save as Template) находится на Ленте меню на вкладке Конструктор (Design) в разделе Тип (Type).
После нажатия Сохранить как шаблон (Save as Template) появится диалоговое окно Сохранение шаблона диаграммы (Save Chart Template), где нужно ввести имя шаблона и нажать кнопку Сохранить (Save).
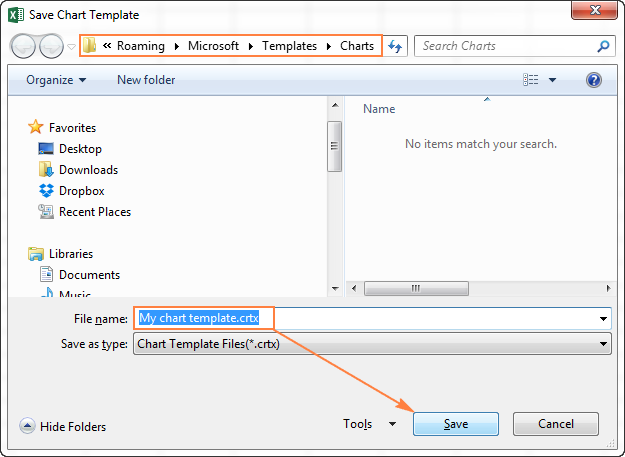
По умолчанию вновь созданный шаблон диаграммы сохраняется в специальную папку Charts. Все шаблоны диаграмм автоматически добавляются в раздел Шаблоны (Templates), который появляется в диалоговых окнах Вставка диаграммы (Insert Chart) и Изменение типа диаграммы (Change Chart Type) в Excel.
Имейте ввиду, что только те шаблоны, которые были сохранены в папке Charts будут доступны в разделе Шаблоны (Templates). Убедитесь, что не изменили папку по умолчанию при сохранении шаблона.
Совет: Если Вы загрузили шаблоны диаграмм из Интернета и хотите, чтобы они были доступны в Excel при создании графика, сохраните загруженный шаблон как .crtx файл в папке Charts:
Как использовать шаблон диаграммы
Чтобы создать диаграмму в Excel из шаблона, откройте диалоговое окно Вставка диаграммы (Insert Chart), нажав на кнопку Просмотр всех диаграмм (See All Charts) в правом нижнем углу раздела Диаграммы (Charts). На вкладке Все диаграммы (All Charts) перейдите в раздел Шаблоны (Templates) и среди доступных шаблонов выберите нужный.
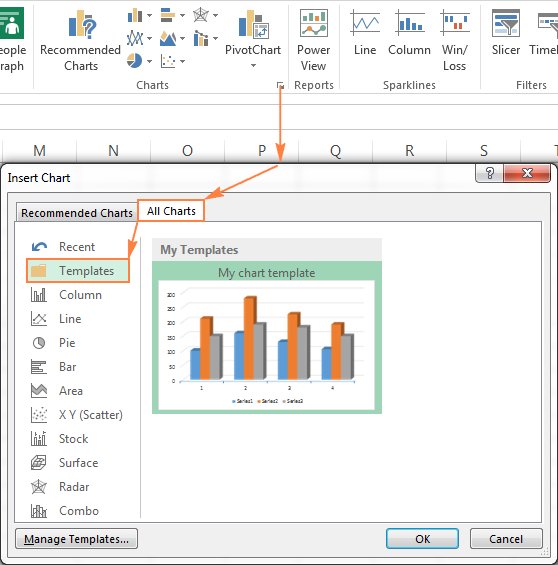
Чтобы применить шаблон диаграммы к уже созданной диаграмме, щелкните правой кнопкой мыши по диаграмме и в контекстном меню выберите Изменить тип диаграммы (Change Chart Type). Или перейдите на вкладку Конструктор (Design) и нажмите кнопку Изменить тип диаграммы (Change Chart Type) в разделе Тип (Type).
В обоих случаях откроется диалоговое окно Изменение типа диаграммы (Change Chart Type), где в разделе Шаблоны (Templates) можно выбрать нужный шаблон.
Как удалить шаблон диаграммы в Excel
Чтобы удалить шаблон диаграммы, откройте диалоговое окно Вставка диаграммы (Insert Chart), перейдите в раздел Шаблоны (Templates) и нажмите кнопку Управление шаблонами (Manage Templates) в левом нижнем углу.
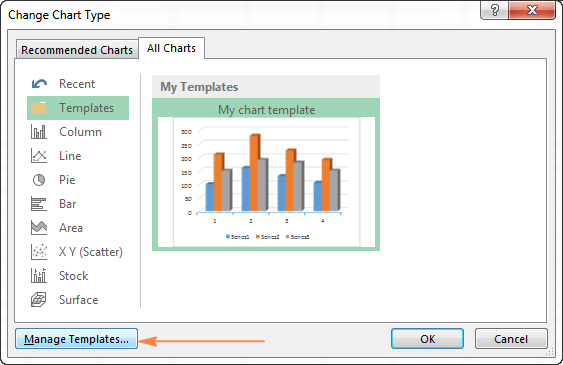
Нажатие кнопки Управление шаблонами (Manage Templates) откроет папку Charts, в которой содержатся все существующие шаблоны. Щелкните правой кнопкой мыши на шаблоне, который нужно удалить, и выберите Удалить (Delete) в контекстном меню.
Линейная регрессия в Excel
Теперь, когда под рукой есть все необходимые виртуальные инструменты для осуществления эконометрических расчетов, можем приступить к решению нашей задачи. Для этого:
- щелкаем по кнопке «Анализ данных»;
- в открывшемся окне нажимаем на кнопку «Регрессия»;
- в появившуюся вкладку вводим диапазон значений для Y (количество уволившихся работников) и для X (их зарплаты);
- подтверждаем свои действия нажатием кнопки «Ok».
В результате программа автоматически заполнит новый лист табличного процессора данными анализа регрессии
Обратите внимание! В Excel есть возможность самостоятельно задать место, которое вы предпочитаете для этой цели. Например, это может быть тот же лист, где находятся значения Y и X, или даже новая книга, специально предназначенная для хранения подобных данных
Основные задачи и виды регрессии
Регрессия представляет собой зависимость между заданными переменными, за счет чего можно определить прогноз будущего поведения данных переменных. Переменные — это различные периодические явления, включая и поведение человека. Такой анализ программы Excel применяется для того, чтобы проанализировать воздействие на конкретную зависимую переменную значений одной или некоторым количеством переменных. К примеру, на продажи в магазине влияет несколько факторов, включая ассортимент, цены и место локализации магазина. Благодаря регрессии в Excel можно определять степень влияния каждого из указанных факторов по результатам имеющихся продаж, а после применить полученные данные для прогнозирования продаж на другой месяц или для другого магазина, расположенного рядом.
Обычно регрессия представлена в виде простого уравнения, раскрывающего зависимости и силу связи между двумя группами переменных, где одна группа является зависимой или эндогенной, а другая — независимой или экзогенной. При наличии группы взаимосвязанных показателей зависимая переменная Y определяется исходя из логики рассуждений, а остальные выступают в роли независимых Х-переменных.
Основные задачи построения регрессионной модели заключаются в следующем:
- Отбор значимых независимых переменных (Х1, Х2, …, Xk).
- Выбор вида функции.
- Построение оценок для коэффициентов.
- Построение доверительных интервалов и функции регрессии.
- Проверка значимости вычисленных оценок и построенного уравнения регрессии.
Регрессионный анализ бывает нескольких видов:
- парный (1 зависимая и 1 независимая переменные);
- множественный (несколько независимых переменных).
Уравнения регрессии бывает двух видов:
- Линейные, иллюстрирующие строгую линейную связь между переменными.
- Нелинейные — уравнения, которые могут включать степени, дроби и тригонометрические функции.
Инструкция построения модели
Чтобы выполнить заданное построение в Excel, необходимо следовать указаниям:

Для дальнейшего вычисления следует использоваться функцию «Линейн ()», указывая Значения Y, Значения Х, Конст и статистику. После этого определите множество точек на линии регрессии с помощью функции «Тенденция» — Значения Y, Значения Х, Новые значения, Конст. При помощи заданных параметров вычислите неизвестное значение коэффициентов, опираясь на заданные условия поставленной задачи.
КОРРЕЛЯЦИОННО-РЕГРЕССИОННЫЙ АНАЛИЗ В MS EXCEL
1. Создайте файл исходных данных в MS Excel (например, таблица 2)
2. Построение корреляционного поля
Для построения корреляционного поля в командной строке выбираем меню Вставка/ Диаграмма . В появившемся диалоговом окне выберите тип диаграммы: Точечная ; вид: Точечная диаграмма , позволяющая сравнить пары значений (Рис. 22).
Рисунок 22 – Выбор типа диаграммы
Рисунок 23– Вид окна при выборе диапазона и рядов Рисунок 25 – Вид окна, шаг 4
2. В контекстном меню выбираем команду Добавить линию тренда.
3. В появившемся диалоговом окне выбираем тип графика (в нашем примере линейная) и параметры уравнения, как показано на рисунке 26.
Нажимаем ОК. Результат представлен на рисунке 27.
Рисунок 27 – Корреляционное поле зависимости производительности труда от фондовооруженности
Аналогично строим корреляционное поле зависимости производительности труда от коэффициента сменности оборудования. (рисунок 28).

от коэффициента сменности оборудования
3. Построение корреляционной матрицы.
Для построения корреляционной матрицы в меню Сервис выбираем Анализ данных.
С помощью инструмента анализа данных Регрессия , помимо результатов регрессионной статистики, дисперсионного анализа и доверительных интервалов, можно получить остатки и графики подбора линии регрессии, остатков и нормальной вероятности. Для этого необходимо проверить доступ к пакету анализа. В главном меню последовательно выберите Сервис/ Надстройки . Установите флажок Пакет анализа (Рисунок 29)
Рисунок 30 – Диалоговое окно Анализ данных
После нажатия ОК в появившемся диалоговом окне указываем входной интервал (в нашем примере А2:D26), группирование (в нашем случае по столбцам) и параметры вывода, как показано на рисунке 31.

Результат расчетов представлен в таблице 4.
Пример 1
Рассмотрим задачу определения зависимости количества уволившихся членов коллектива от средней зарплаты на 6 промышленных предприятиях.
Задача. На шести предприятиях проанализировали среднемесячную заработную плату и количество сотрудников, которые уволились по собственному желанию. В табличной форме имеем:
Для задачи определения зависимости количества уволившихся работников от средней зарплаты на 6 предприятиях модель регрессии имеет вид уравнения Y = а + а1x1 +…+аkxk, где хi — влияющие переменные, ai — коэффициенты регрессии, a k — число факторов.
Для данной задачи Y — это показатель уволившихся сотрудников, а влияющий фактор — зарплата, которую обозначаем X.
Расчет коэффициента корреляции
Теперь давайте попробуем посчитать коэффициент корреляции на конкретном примере. Имеем таблицу, в которой помесячно расписана в отдельных колонках затрата на рекламу и величина продаж. Нам предстоит выяснить степень зависимости количества продаж от суммы денежных средств, которая была потрачена на рекламу.
Способ 1: определение корреляции через Мастер функций
Одним из способов, с помощью которого можно провести корреляционный анализ, является использование функции КОРРЕЛ. Сама функция имеет общий вид КОРРЕЛ(массив1;массив2).
- Выделяем ячейку, в которой должен выводиться результат расчета. Кликаем по кнопке «Вставить функцию», которая размещается слева от строки формул.
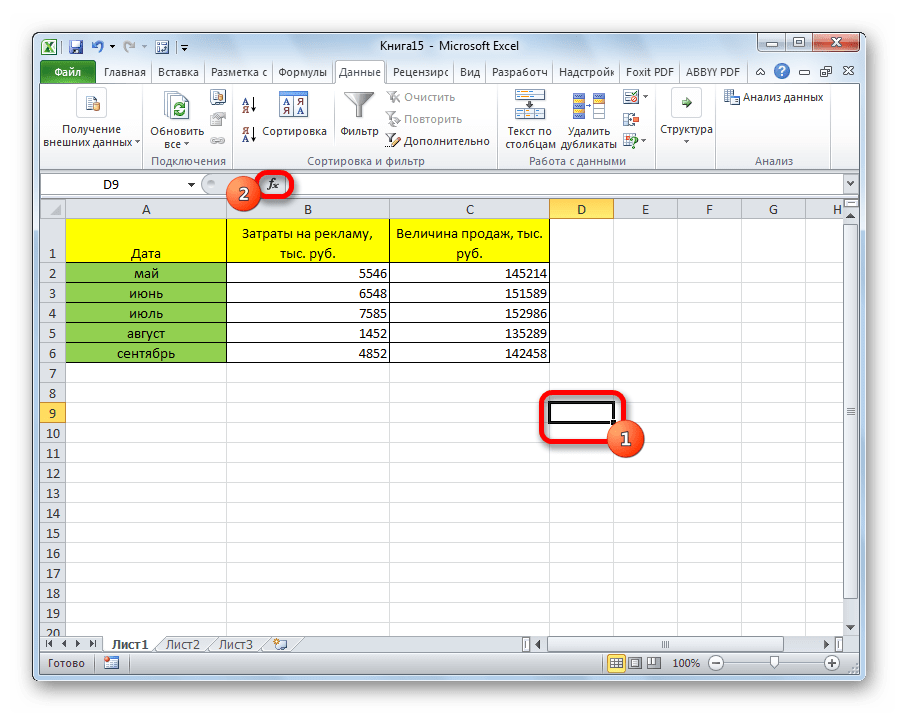
В списке, который представлен в окне Мастера функций, ищем и выделяем функцию КОРРЕЛ. Жмем на кнопку «OK».
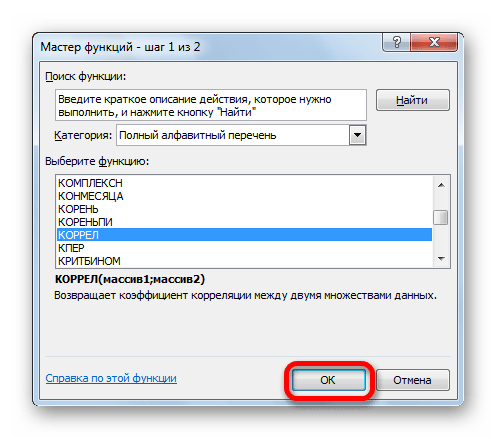
Открывается окно аргументов функции. В поле «Массив1» вводим координаты диапазона ячеек одного из значений, зависимость которого следует определить. В нашем случае это будут значения в колонке «Величина продаж». Для того, чтобы внести адрес массива в поле, просто выделяем все ячейки с данными в вышеуказанном столбце.
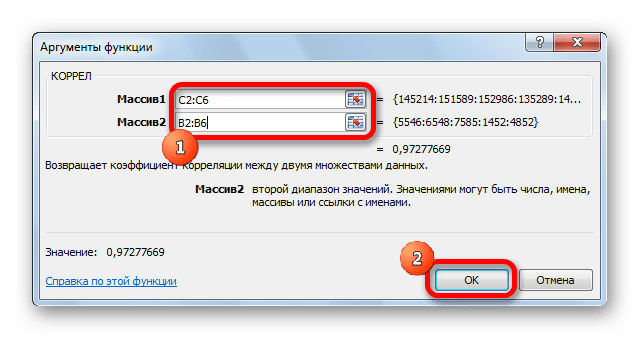
В поле «Массив2» нужно внести координаты второго столбца. У нас это затраты на рекламу. Точно так же, как и в предыдущем случае, заносим данные в поле.
Жмем на кнопку «OK».
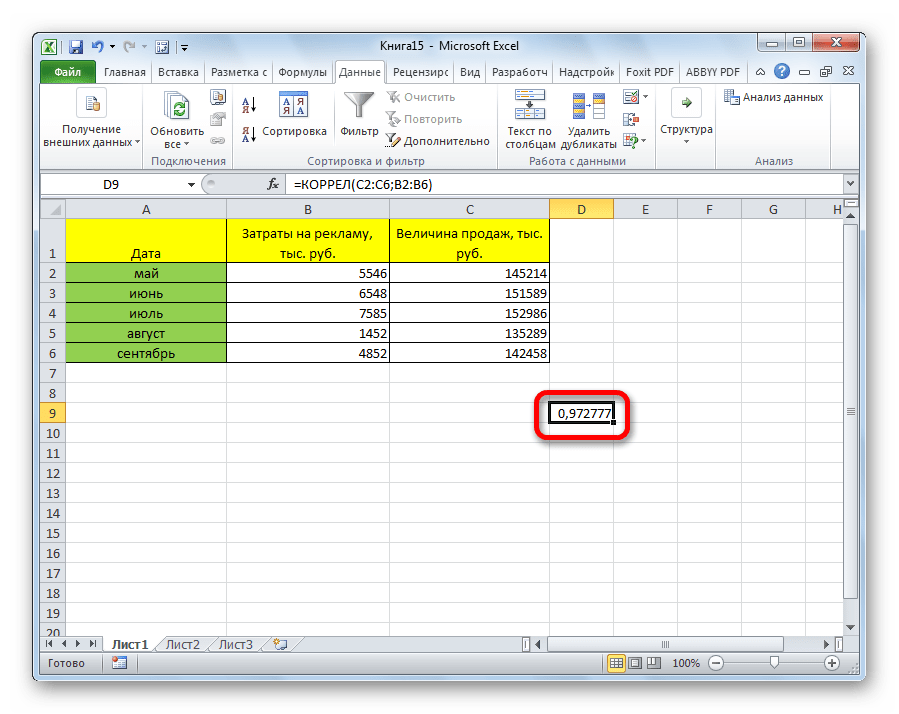
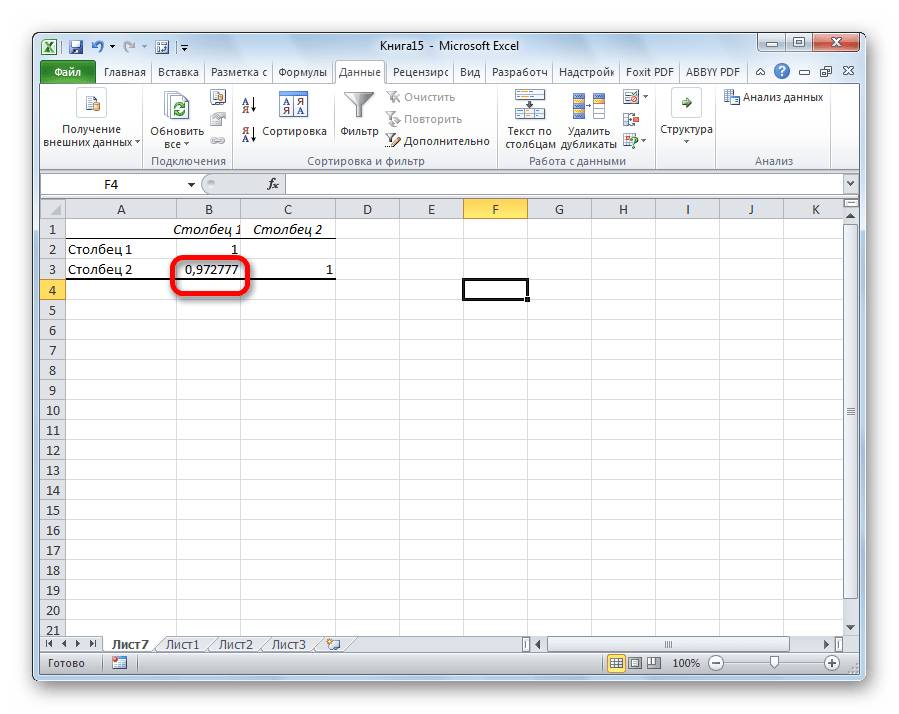
Как видим, коэффициент корреляции в виде числа появляется в заранее выбранной нами ячейке. В данном случае он равен 0,97, что является очень высоким признаком зависимости одной величины от другой.
Способ 2: вычисление корреляции с помощью пакета анализа
Кроме того, корреляцию можно вычислить с помощью одного из инструментов, который представлен в пакете анализа. Но прежде нам нужно этот инструмент активировать.
- Переходим во вкладку «Файл».
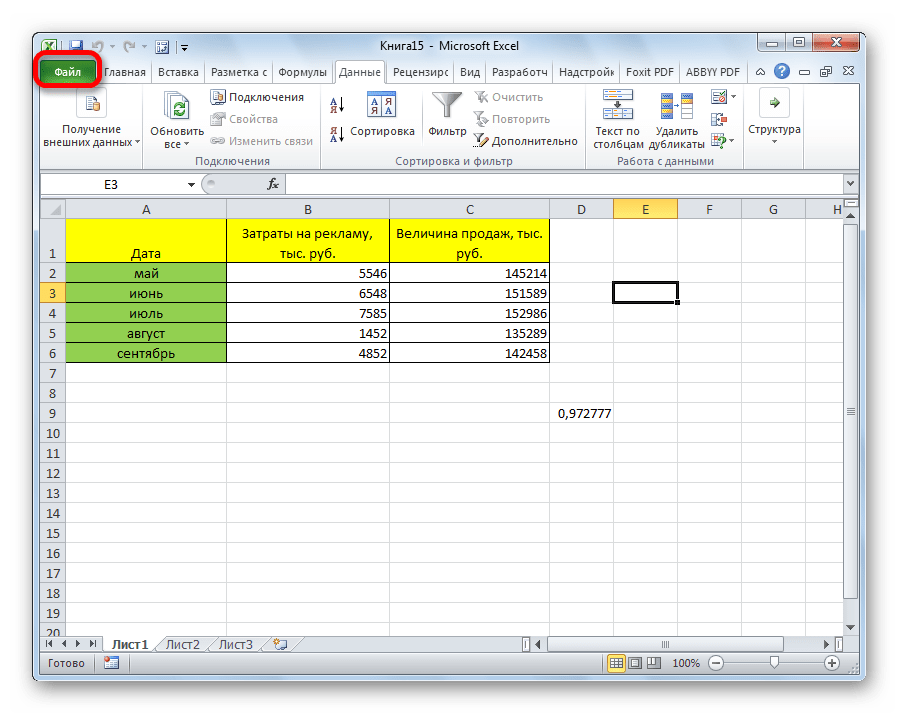
В открывшемся окне перемещаемся в раздел «Параметры».
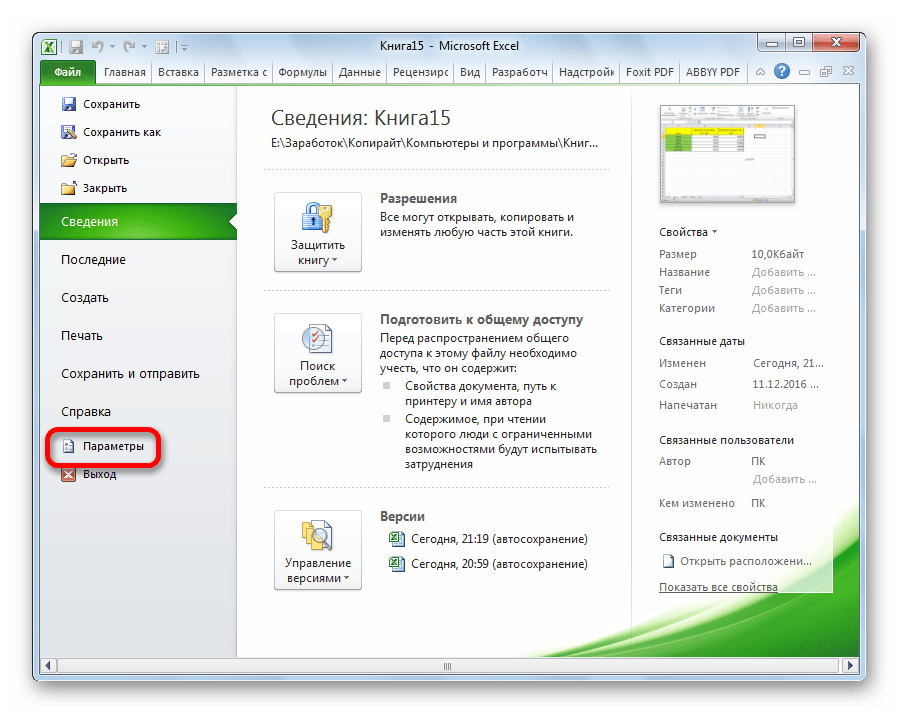
Далее переходим в пункт «Надстройки».
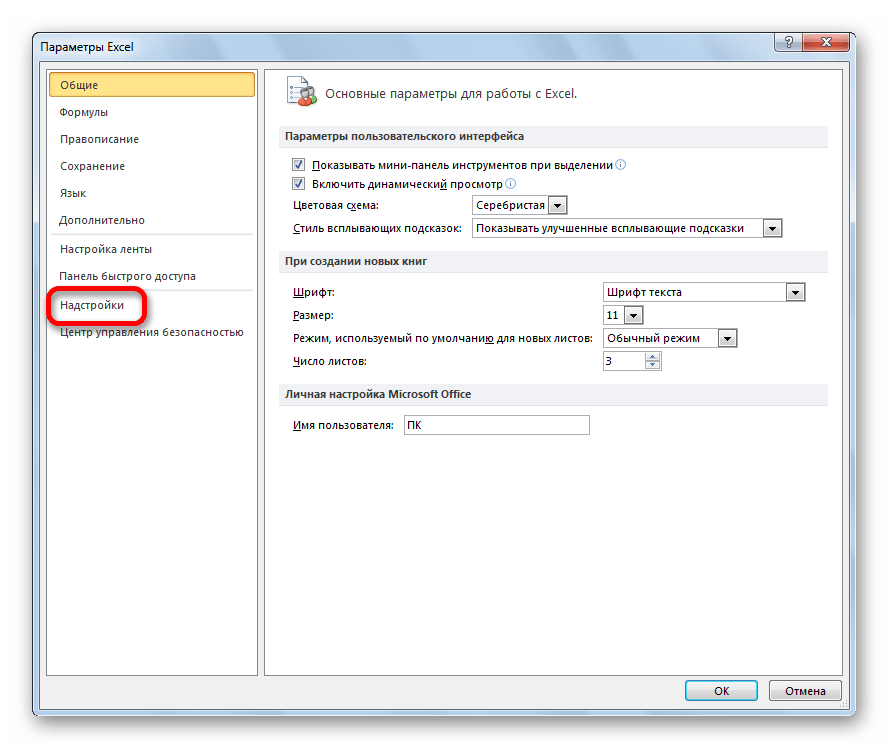
В нижней части следующего окна в разделе «Управление» переставляем переключатель в позицию «Надстройки Excel», если он находится в другом положении. Жмем на кнопку «OK».
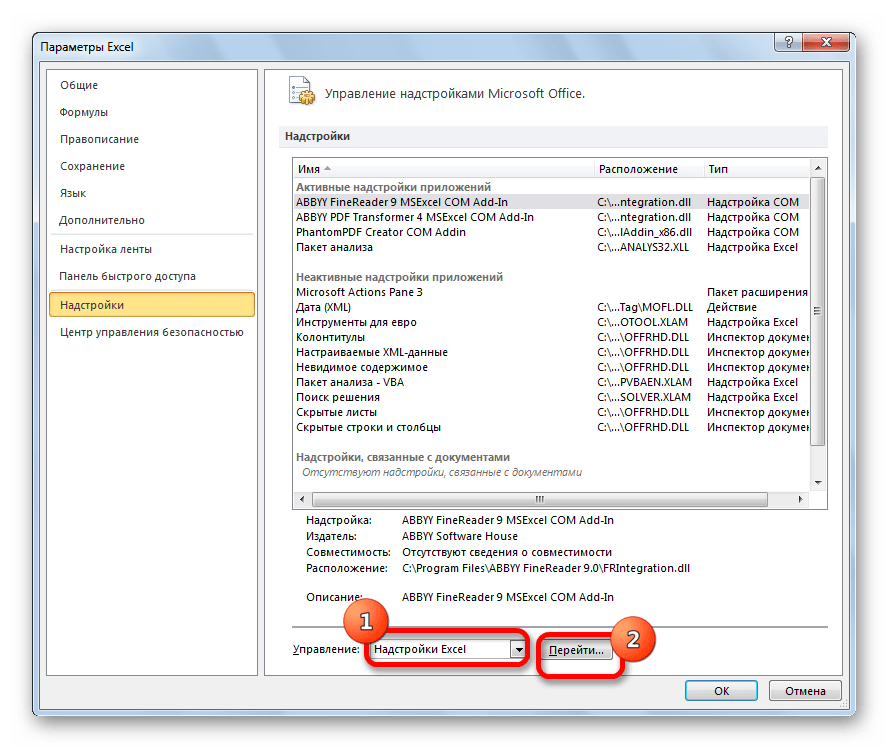
В окне надстроек устанавливаем галочку около пункта «Пакет анализа». Жмем на кнопку «OK».
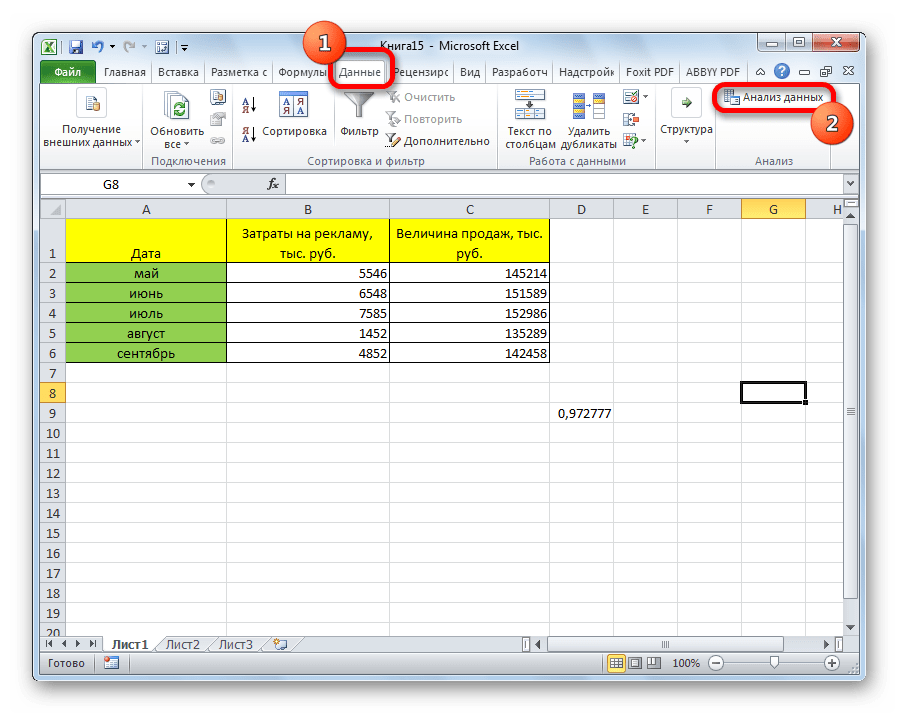
После этого пакет анализа активирован. Переходим во вкладку «Данные». Как видим, тут на ленте появляется новый блок инструментов – «Анализ». Жмем на кнопку «Анализ данных», которая расположена в нем.
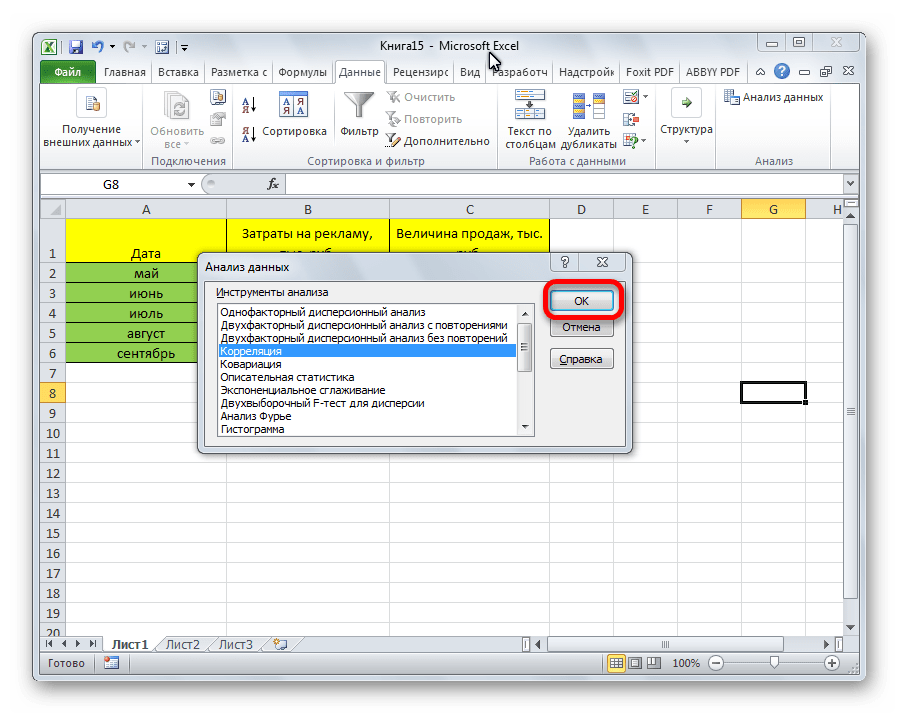
Открывается список с различными вариантами анализа данных. Выбираем пункт «Корреляция». Кликаем по кнопке «OK».
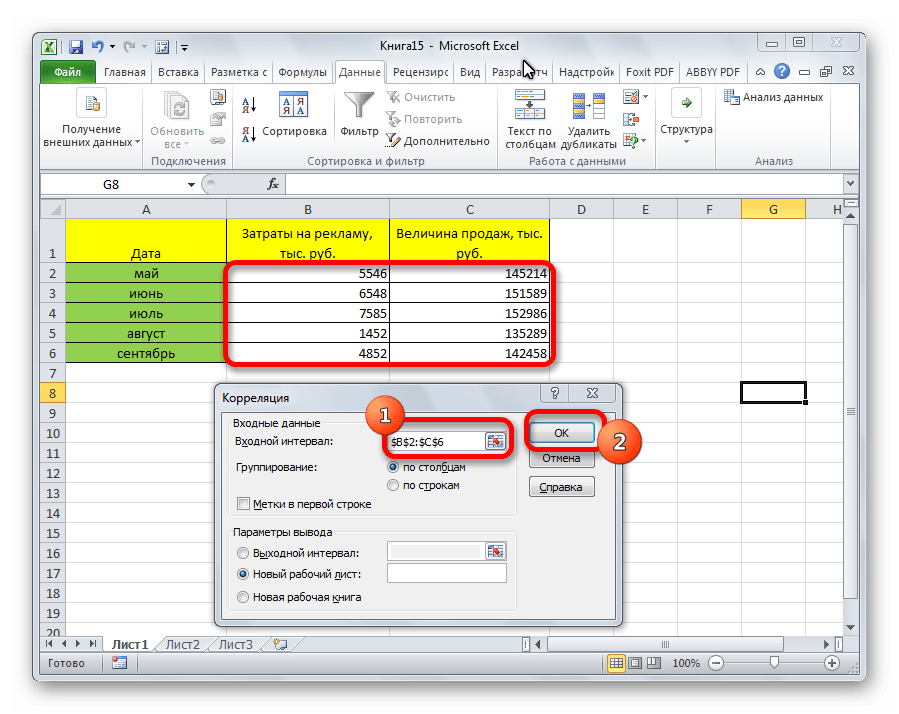
Открывается окно с параметрами корреляционного анализа. В отличие от предыдущего способа, в поле «Входной интервал» мы вводим интервал не каждого столбца отдельно, а всех столбцов, которые участвуют в анализе. В нашем случае это данные в столбцах «Затраты на рекламу» и «Величина продаж».
Параметр «Группирование» оставляем без изменений – «По столбцам», так как у нас группы данных разбиты именно на два столбца. Если бы они были разбиты построчно, то тогда следовало бы переставить переключатель в позицию «По строкам».
В параметрах вывода по умолчанию установлен пункт «Новый рабочий лист», то есть, данные будут выводиться на другом листе. Можно изменить место, переставив переключатель. Это может быть текущий лист (тогда вы должны будете указать координаты ячеек вывода информации) или новая рабочая книга (файл).
Когда все настройки установлены, жмем на кнопку «OK».
Так как место вывода результатов анализа было оставлено по умолчанию, мы перемещаемся на новый лист. Как видим, тут указан коэффициент корреляции. Естественно, он тот же, что и при использовании первого способа – 0,97. Это объясняется тем, что оба варианта выполняют одни и те же вычисления, просто произвести их можно разными способами.
Как видим, приложение Эксель предлагает сразу два способа корреляционного анализа. Результат вычислений, если вы все сделаете правильно, будет полностью идентичным. Но, каждый пользователь может выбрать более удобный для него вариант осуществления расчета.
Опишите, что у вас не получилось.
Наши специалисты постараются ответить максимально быстро.
Разбор результатов анализа
Результаты регрессионного анализа выводятся в виде таблицы в том месте, которое указано в настройках.
Одним из основных показателей является R-квадрат. В нем указывается качество модели. В нашем случае данный коэффициент равен 0,705 или около 70,5%. Это приемлемый уровень качества. Зависимость менее 0,5 является плохой.
Ещё один важный показатель расположен в ячейке на пересечении строки «Y-пересечение» и столбца «Коэффициенты». Тут указывается какое значение будет у Y, а в нашем случае, это количество покупателей, при всех остальных факторах равных нулю. В этой таблице данное значение равно 58,04.
Значение на пересечении граф «Переменная X1» и «Коэффициенты» показывает уровень зависимости Y от X. В нашем случае — это уровень зависимости количества клиентов магазина от температуры. Коэффициент 1,31 считается довольно высоким показателем влияния.
Как видим, с помощью программы Microsoft Excel довольно просто составить таблицу регрессионного анализа. Но, работать с полученными на выходе данными, и понимать их суть, сможет только подготовленный человек.
Мы рады, что смогли помочь Вам в решении проблемы.
Помогла ли вам эта статья?
Да Нет
Метод линейной регрессии позволяет нам описывать прямую линию, максимально соответствующую ряду упорядоченных пар (x, y). Уравнение для прямой линии, известное как линейное уравнение, представлено ниже:
ŷ = a + bx
где:
ŷ — ожидаемое значение у при заданном значении х,
x — независимая переменная,
a — отрезок на оси y для прямой линии,
b — наклон прямой линии.
На рисунке ниже это понятие представлено графически:
На рисунке выше показана линия, описанная уравнением ŷ =2+0.5х. Отрезок на оси у — это точка пересечения линией оси у; в нашем случае а = 2. Наклон линии, b, отношение подъема линии к длине линии, имеет значение 0.5. Положительный наклон означает, что линия поднимается слева направо. Если b = 0, линия горизонтальна, а это значит, что между зависимой и независимой переменными нет никакой связи. Иными словами, изменение значения x не влияет на значение y.
Часто путают ŷ и у. На графике показаны 6 упорядоченных пар точек и линия, в соответствии с данным уравнением
ŷ = 2 + 0.5x
На этом рисунке показана точка, соответствующая упорядоченной паре х = 2 и у = 4
Обратите внимание, что ожидаемое значение у в соответствии с линией при х = 2 является ŷ. Мы можем подтвердить это с помощью следующего уравнения:
ŷ = 2 + 0.5х =2 +0.5(2) =3.
Значение у представляет собой фактическую точку, а значение ŷ — это ожидаемое значение у с использованием линейного уравнения при заданном значении х.
Следующий шаг — определить линейное уравнение, максимально соответствующее набору упорядоченных пар, об этом мы говорили в предыдущей статье, где определяли вид уравнения по методу наименьших квадратов.
Линейная регрессия в программе Excel
Внизу, в качестве примера, представлена таблица, в которой указана среднесуточная температура воздуха на улице, и количество покупателей магазина за соответствующий рабочий день. Давайте выясним при помощи регрессионного анализа, как именно погодные условия в виде температуры воздуха могут повлиять на посещаемость торгового заведения.
Общее уравнение регрессии линейного вида выглядит следующим образом: У = а0 + а1х1 +…+акхк . В этой формуле Y означает переменную, влияние факторов на которую мы пытаемся изучить. В нашем случае, это количество покупателей. Значение x – это различные факторы, влияющие на переменную. Параметры a являются коэффициентами регрессии. То есть, именно они определяют значимость того или иного фактора. Индекс k обозначает общее количество этих самых факторов.
- Кликаем по кнопке «Анализ данных». Она размещена во вкладке «Главная» в блоке инструментов «Анализ».

Открывается небольшое окошко. В нём выбираем пункт «Регрессия». Жмем на кнопку «OK».

Открывается окно настроек регрессии. В нём обязательными для заполнения полями являются «Входной интервал Y» и «Входной интервал X». Все остальные настройки можно оставить по умолчанию.
В поле «Входной интервал Y» указываем адрес диапазона ячеек, где расположены переменные данные, влияние факторов на которые мы пытаемся установить. В нашем случае это будут ячейки столбца «Количество покупателей». Адрес можно вписать вручную с клавиатуры, а можно, просто выделить требуемый столбец. Последний вариант намного проще и удобнее.
В поле «Входной интервал X» вводим адрес диапазона ячеек, где находятся данные того фактора, влияние которого на переменную мы хотим установить. Как говорилось выше, нам нужно установить влияние температуры на количество покупателей магазина, а поэтому вводим адрес ячеек в столбце «Температура». Это можно сделать теми же способами, что и в поле «Количество покупателей».

С помощью других настроек можно установить метки, уровень надёжности, константу-ноль, отобразить график нормальной вероятности, и выполнить другие действия. Но, в большинстве случаев, эти настройки изменять не нужно
Единственное на что следует обратить внимание, так это на параметры вывода. По умолчанию вывод результатов анализа осуществляется на другом листе, но переставив переключатель, вы можете установить вывод в указанном диапазоне на том же листе, где расположена таблица с исходными данными, или в отдельной книге, то есть в новом файле

После того, как все настройки установлены, жмем на кнопку «OK».

Проверка общего качества уравнения множественной регрессии
Для этой цели, как и в случае множественной регрессии, используется коэффициентдетерминации R2:Справедливо соотношение 0 < =R2 < = 1. Чем ближе этот коэффициент к единице, тем больше уравнение множественной регрессии объясняет поведение Y.Для множественной регрессии коэффициент детерминации является неубывающей функцией числа объясняющих переменных. Добавление новой объясняющей переменной никогда не уменьшает значение R2, так как каждая последующая переменная может лишь дополнить, но никак не сократить информацию, объясняющую поведениезависимой переменной.Иногда при расчете коэффициента детерминации для получения несмещенных оценок в числителе и знаменателе вычитаемой из единицы дроби делается поправка на число степеней свободы, т.е. вводится так называемый скорректированный (исправленный) коэффициент детерминации:Соотношение может быть представлено в следующем виде: для m>1. С ростом значения mскорректированный коэффициент детерминации растет медленнее, чем обычный.Очевидно, что только при R2 = 1. может принимать отрицательные значения. Доказано, что увеличивается при добавлении новой объясняющей переменной тогда и только тогда, когда t-статистика для этой переменной по модулю больше единицы. Поэтому добавление в модель новых объясняющих переменных осуществляется до тех пор, пока растет скорректированный коэффициент детерминации.Рекомендуется после проверки общего качества уравнения регрессии провести анализ его статистической значимости. Для этого используется F-статистика:
Показатели F и R2 равны или не равен нулю одновременно. Если F=0, то R2=0, следовательно, величина Y линейно не зависит от X1,X2,…,Xm.Расчетное значение F сравнивается с критическим Fкр. Fкр, исходя из требуемого уровня значимости α и чисел степеней свободы v1 = m и v2 = n — m — 1, определяется на основе распределения Фишера. Если F > Fкр, то R2 статистически значим.
Что такое коэффициент корреляции?
Различные признаки могут быть связаны между собой.Выделяют 2 вида связи между ними:
- функциональная;
- корреляционная.
Корреляция в переводе на русский язык – не что иное, как связь. В случае корреляционной связи прослеживается соответствие нескольких значений одного признака нескольким значениям другого признака. В качестве примеров можно рассмотреть установленные корреляционные связи между:
- длиной лап, шеи, клюва у таких птиц как цапли, журавли, аисты;
- показателями температуры тела и частоты сердечных сокращений.
Для большинства медико-биологических процессов статистически доказано присутствие этого типа связи.
Статистические методы позволяют установить факт существования взаимозависимости признаков. Использование для этого специальных расчетов приводит к установлению коэффициентов корреляции (меры связанности).
Такие расчеты получили название корреляционного анализа. Он проводится для подтверждения зависимости друг от друга 2-х переменных (случайных величин), которая выражается коэффициентом корреляции.
Использование корреляционного метода позволяет решить несколько задач:
- выявить наличие взаимосвязи между анализируемыми параметрами;
- знание о наличии корреляционной связи позволяет решать проблемы прогнозирования. Так, существует реальная возможность предсказывать поведение параметра на основе анализа поведения другого коррелирующего параметра;
- проведение классификации на основе подбора независимых друг от друга признаков.
Для переменных величин:
- относящихся к порядковой шкале, рассчитывается коэффициент Спирмена;
- относящихся к интервальной шкале – коэффициент Пирсона.
Это наиболее часто используемые параметры, кроме них есть и другие.
Значение коэффициента может выражаться как положительным, так и отрицательными.
В первом случае при увеличении значения одной переменной наблюдается увеличение второй. При отрицательном коэффициенте – закономерность обратная.
Что объясняет регрессия?
Прежде, чем мы приступим к рассмотрению функций MS Excel, позволяющих, решать данные задачи, хотелось бы вам на пальцах объяснить, что, в сущности, предполагает регрессионный анализ. Так вам проще будет сдавать экзамен, а самое главное, интересней изучать предмет.
Будем надеяться, вы знакомы с понятием функции из математики. Функция – это взаимосвязь двух переменных. При изменении одной переменной что-то происходит с другой. Изменяем X, меняется и Y, соответственно. Функциями описываются различные законы. Зная функцию, мы можем подставлять произвольные значения X и смотреть на то, как при этом изменится Y.
Это имеет большое значение, поскольку регрессия – это попытка объяснить с помощью определённой функции на первый взгляд бессистемные и хаотичные процессы. Так, например, можно выявить взаимосвязь курса доллара и безработицы в России.
Если данную закономерность обнаружить удастся, то по полученной нами в ходе расчетов функции, мы сможем составить прогноз, какой будет уровень безработицы при N-ом курсе доллара по отношению к рублю. Данная взаимосвязь будет называться корреляцией. Регрессионный анализ предполагает расчет коэффициента корреляции, который объяснит тесноту связи между рассматриваемыми нами переменными (курсом доллара и числом рабочих мест).
Данный коэффициент может быть положительным и отрицательным. Его значения находятся в пределах от -1 до 1. Соответственно, мы может наблюдать высокую отрицательную или положительную корреляцию. Если она положительная, то за увеличением курса доллара последует и появление новых рабочих мест. Если она отрицательная, значит, за увеличением курса, последует уменьшение рабочих мест.
Регрессия бывает нескольких видов. Она может быть линейной, параболической, степенной, экспоненциальной и т.д. Выбор модели мы делаем в зависимости от того, какая регрессия будет соответствовать конкретно нашему случаю, какая модель будет максимально близка к нашей корреляции. Рассмотрим это на примере задачи и решим её в MS Excel.
Матрица парных коэффициентов корреляции в Excel
Корреляционная матрица представляет собой таблицу, на пересечении строк и столбцов которой находятся коэффициенты корреляции между соответствующими значениями. Имеет смысл ее строить для нескольких переменных.
Матрица коэффициентов корреляции в Excel строится с помощью инструмента «Корреляция» из пакета «Анализ данных».
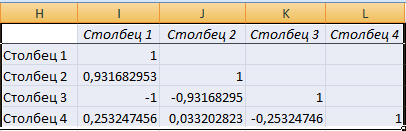
Между значениями y и х1 обнаружена сильная прямая взаимосвязь. Между х1 и х2 имеется сильная обратная связь. Связь со значениями в столбце х3 практически отсутствует.
Где x·y , x , y — средние значения выборок; σ(x), σ(y) — среднеквадратические отклонения.
Кроме того, коэффициент линейной парной корреляции может быть определен через коэффициент регрессии b: , где σ(x)=S(x), σ(y)=S(y) — среднеквадратические отклонения, b — коэффициент перед x в уравнении регрессии y=a+bx .
Другие варианты формул:
или К xy — корреляционный момент (коэффициент ковариации)
Линейный коэффициент корреляции принимает значения от –1 до +1 (см. шкалу Чеддока). Например, при анализе тесноты линейной корреляционной связи между двумя переменными получен коэффициент парной линейной корреляции, равный –1 . Это означает, что между переменными существует точная обратная линейная зависимость.
Геометрический смысл коэффициента корреляции
Свойства коэффициента корреляции
- |r xy | ≤ 1;
- если X и Y независимы, то r xy =0, обратное не всегда верно;
- если |r xy |=1, то Y=aX+b, |r xy (X,aX+b)|=1, где a и b постоянные, а ≠ 0;
- |r xy (X,Y)|=|r xy (a 1 X+b 1 , a 2 X+b 2)|, где a 1 , a 2 , b 1 , b 2 – постоянные.
Инструкция
. Укажите количество исходных данных. Полученное решение сохраняется в файле Word
(см. Пример нахождения уравнения регрессии). Также автоматически создается шаблон решения в Excel
. .
1.Открыть программу Excel
2.Создать столбцы с данными. В нашем примере мы будем считать взаимосвязь, или корреляцию, между агрессивностью и неуверенностью в себе у детей-первоклассников. В эксперименте участвовали 30 детей, данные представлены в таблице эксель:
1 столбик — № испытуемого
2 столбик — агрессивность в баллах
3 столбик — неуверенность в себе в баллах
3.Затем необходимо выбрать пустую ячейку рядом с таблицей и нажать на значок f(x) в панели Excel
4.Откроется меню функций, среди категорий необходимо выбрать Статистические, а затем среди списка функций по алфавиту найти КОРРЕЛи нажать ОК
5.Затем откроется меню аргументов функции, которое позволит выбрать нужные нам столбики с данными. Для выбора первого столбика Агрессивность нужно нажать на синюю кнопочку у строки Массив1
6.Выберем данные для Массива1из столбика Агрессивность и нажмем на синюю кнопочку в диалоговом окне
7. Затем аналогично Массиву 1 нажмём на синюю кнопочку у строки Массив2
8.Выберем данные для Массива2 — столбик Неуверенность в себеи опять нажмем синюю кнопку, затем ОК
9.Вот, коэффициент корреляции r-Пирсона посчитан и записан в выбранной ячейке.В нашем случае он положительный и приблизительно равен 0,225. Это говорит об умеренной положительной связи между агрессивностью и неуверенностью в себе у детей-первоклассников
Таким образом, статистическим выводом эксперимента будет: r = 0,225, выявлена умеренная положительная взаимосвязь между переменными агрессивность и неуверенность в себе.
В некоторых исследованиях требуется указывать р-уровень значимости коэффициента корреляции, однако программа Excel, в отличие от SPSS, не предоставляет такой возможности. Ничего страшного, есть (А.Д. Наследов).
Также Вы можете и приложить её к результатам исследования.
