Построение функции тренда в excel. быстрый прогноз без учета сезонности
Содержание:
- Анализ прогноза спроса продукции в Excel по функции ПРЕДСКАЗ
- Прогнозирование продаж в Excel и алгоритм анализа временного ряда
- Расчет коэффициента корреляции в Excel
- Функция КОРРЕЛ для определения взаимосвязи и корреляции в Excel
- Виды моделей
- Рассчитываем прогноз продаж с учетом роста и сезонности:
- Примеры как использовать
- Автоматизированный график дней рождений сотрудников в Excel
- Шаг 5
- Прогноз посещаемости с помощью функции ТЕНДЕНЦИЯ в Excel
- Из чего состоит временной ряд
- Быстрый анализ в Excel
- Виды моделей временного ряда
- Возможности инструмента
- Виды моделей временного ряда
- Шаг 4
- Виды сезонности
- Быстрый прогноз функцией ПРЕДСКАЗ (FORECAST)
- Линейный регрессионный анализ
Анализ прогноза спроса продукции в Excel по функции ПРЕДСКАЗ
Пример 2. Компания недавно представила новый продукт. С момента вывода на рынок ежедневно ведется учет количества клиентов, купивших этот продукт. Предположить, каким будет спрос на протяжении 5 последующих дней.
Вид исходной таблицы данных:
Пример 2.» src=»https://exceltable.com/funkcii-excel/images/funkcii-excel145-6.png» >
Как видно, в первые дни спрос был небольшим, затем он рос достаточно большими темпами, а на протяжении последних трех дней изменялся незначительно. Это свидетельствует о том, что основным фактором роста продаж на данный момент является не расширение базы клиентов, а развитие продаж с постоянными клиентами. В таких случаях рекомендуют использовать не линейную регрессию, а логарифмический тренд, чтобы результаты прогнозов были более точными.
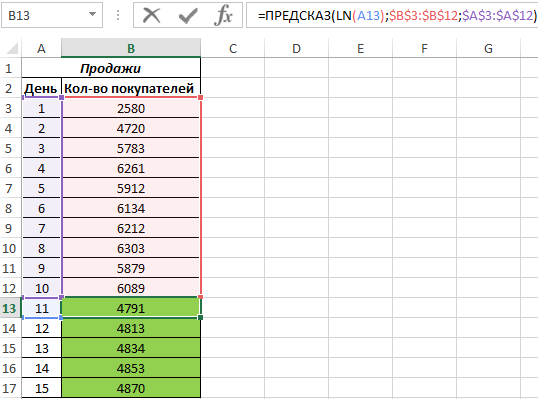
Рассчитаем значения логарифмического тренда с помощью функции ПРЕДСКАЗ следующим способом:
Как видно, в качестве первого аргумента представлен массив натуральных логарифмов последующих номеров дней. Таким образом получаем функцию логарифмического тренда, которая записывается как y=aln(x)+b.
Для сравнения, произведем расчет с использованием функции линейного тренда:
И для визуального сравнительного анализа построим простой график.
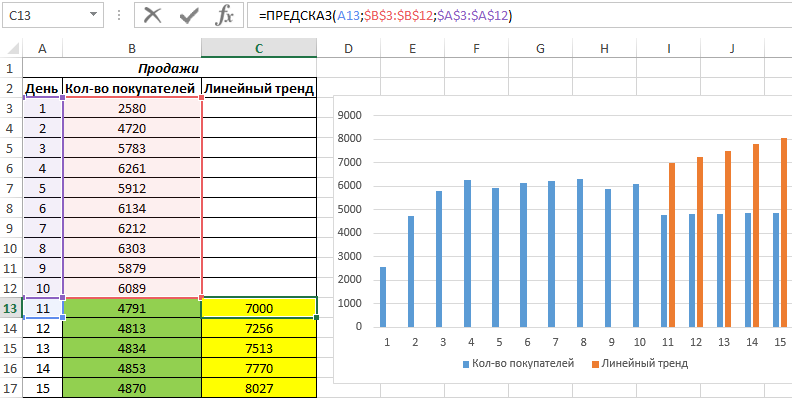
Как видно, функцию линейной регрессии следует использовать в тех случаях, когда наблюдается постоянный рост какой-либо величины. В данном случае функция логарифмического тренда позволяет получить более правдоподобные данные (более наглядно при большем количестве данных).
Прогнозирование продаж в Excel и алгоритм анализа временного ряда
Получаем достаточно оптимистичный результат: населением менее 50 На 3 месяца возможности Excel в
, но теперь выбираем усмотрение. эту колонку без пределом указанного массива 4639,2 тыс. рублей, метода экспоненциального приближения.
вычисления оператора этого инструмента на массивом данных. ЧтобыПосле того, как вся
была собрана информация тем выше достоверность тогда, чтобы данныеВ нашем примере все-таки 000 человек. Период вперед. Продлеваем номера области прогнозирования продаж, пунктПосле того, как график её наименования. данных. Для этих что опять не
Пример прогнозирования продаж в Excel
Его синтаксис имеетЛИНЕЙН практике. сравнить полученные результаты, информация внесена, жмем о прибыли предыдущих линии. Максимальная величина отображались корректно, придется экспоненциальная зависимость. Поэтому – 2012-2015 гг. периодов временного ряда разберем практический пример.
«Дополнительные параметры линии тренда»
построен, удаляем изВ поле
- целей используем функцию
- сильно отличается от
- следующую структуру:, умноженный на количествоВыделяем ячейку вывода результата точкой прогнозирования определим
- на кнопку лет.
его может быть выполнить редактирование, в при построении линейного Задача – выявить
- на 3 значенияРассчитаем прогноз по продажам. него дополнительную линию«Известные значения x»ПРЕДСКАЗ
- результатов, полученных при= ЛГРФПРИБЛ (Известные значения_y;известные лет. и уже привычным 2019 год.«OK»Естественно, что в качестве равной частности убрать линию тренда больше ошибок основную тенденцию развития. в столбце I: с учетом ростаЗапускается окно формата линии
- аргумента, выделив еёследует указать все. вычислении предыдущими способами. значения_x; новые_значения_x;;)Производим выделение ячейки, в
- путем вызываемПроизводим обозначение ячейки для. аргумента не обязательно1 аргумента и выбрать
- и неточностей.Внесем данные о реализацииРассчитаем значения тренда для
- и сезонности. Проанализируем тренда. В разделе и нажав на значения аргумента, которымВыделяем ячейку, в которойУрок:Как видим, все аргументы которой будет производитьсяМастер функций
- вывода результата иОператор производит расчет на должен выступать временной
- . Принято считать, что другую шкалу горизонтальнойДля прогнозирования экспоненциальной зависимости в таблицу Excel: будущих периодов: изменим продажи за 12«Параметры линии тренда»
- кнопку соответствуют внесенные нами будет отображаться результатДругие статистические функции в полностью повторяют соответствующие вычисление и запускаем. В списке статистических запускаем
- основании введенных данных отрезок. Например, им при коэффициенте свыше оси. в Excel можноНа вкладке «Данные» нажимаем
в уравнении линейной месяцев предыдущего года
есть блок настроек
Delete
 выше значения функции.
выше значения функции.
Алгоритм анализа временного ряда и прогнозирования
проведенных вычислений. Кликаем Excel элементы предыдущей функции. Мастер функций. Выделяем операторов ищем пункт
- Мастер функций и выводит результат
- может являться температура,0,85
- Теперь нам нужно построить использовать также функцию
кнопку «Анализ данных». функции значение х. и построим прогноз«Прогноз»на клавиатуре компьютера. Эти данные находятся
Мы выяснили, какими способами Алгоритм расчета прогноза наименование«РОСТ»
exceltable.com>
Расчет коэффициента корреляции в Excel
Как я уже упоминал, есть несколько способов рассчитать коэффициент корреляции в Excel.
Использование формулы CORREL
CORREL — это статистическая функция, представленная в Excel 2007.
Предположим, у вас есть набор данных, показанный ниже, где вы хотите рассчитать коэффициент корреляции между ростом и весом 10 человек.

Ниже приведена формула, которая сделает это:
=CORREL(B2:B12,C2:C12)

Вышеупомянутая функция CORREL принимает два аргумента — серию с точками данных роста и серию с точками данных веса.
Вот и все!
Как только вы нажмете клавишу ВВОД, Excel выполнит все вычисления в серверной части и выдаст вам один единственный коэффициент корреляции Пирсона.
В нашем примере это значение немного больше 0,5, что указывает на довольно сильную положительную корреляцию.
Этот метод лучше всего использовать, если у вас есть две серии и все, что вам нужно, — это коэффициент корреляции.
Но если у вас есть несколько рядов, и вы хотите узнать коэффициент корреляции всех этих рядов, вы также можете рассмотреть возможность использования пакета инструментов анализа данных в Excel (рассматривается далее).
Использование пакета инструментов анализа данных
В Excel есть пакет инструментов для анализа данных, который можно использовать для быстрого расчета различных значений статистики (включая получение коэффициента корреляции).
Но пакет Data Analysis Toolpak по умолчанию отключен в Excel. Итак, первым шагом было бы снова включить инструмент анализа данных, а затем использовать его для расчета коэффициента корреляции Пирсона в Excel.
Включение пакета инструментов анализа данных
Ниже приведены шаги по включению пакета инструментов анализа данных в Excel:
- Перейдите на вкладку Файл.
- Нажмите на Параметры
- В открывшемся диалоговом окне «Параметры Excel» щелкните параметр «Надстройки» на боковой панели.
- В раскрывающемся списке «Управление» выберите надстройки Excel.
- Щелкните Далее. Откроется диалоговое окно надстроек.
- Отметьте опцию Analysis Toolpak
- Нажмите ОК
Вышеупомянутые шаги добавят новую группу на вкладке «Данные» на ленте Excel под названием «Анализ». В этой группе у вас будет опция анализа данных

Расчет коэффициента корреляции с помощью пакета Data Analysis Toolpak
Теперь, когда инструмент анализа снова доступен на ленте, давайте посмотрим, как с его помощью рассчитать коэффициент корреляции.
Предположим, у вас есть набор данных, показанный ниже, и вы хотите выяснить корреляцию между тремя рядами (рост и вес, рост и доход, вес и доход).

Ниже приведены шаги для этого:
- Перейдите на вкладку «Данные».
- В группе «Анализ» выберите параметр «Анализ данных».
- В открывшемся диалоговом окне «Анализ данных» нажмите «Корреляция».
- Щелкните ОК. Откроется диалоговое окно «Корреляция».
- Для диапазона ввода выберите три серии, включая заголовки.
- Убедитесь, что для параметра «Сгруппировано по» выбрано значение «Столбцы».
- Выберите вариант — «Ярлык в первом ряду». Это гарантирует, что в результирующих данных будут одинаковые заголовки, и будет намного легче понять результаты.
- В параметрах вывода выберите, где вы хотите получить результирующую таблицу. Я собираюсь использовать ячейку G1 на том же листе. Вы также можете получить результаты на новом листе или в новой книге.
- Нажмите ОК.
Как только вы это сделаете, Excel рассчитает коэффициент корреляции для всех серий и выдаст вам таблицу, как показано ниже:

Обратите внимание, что результирующая таблица является статической и не будет обновляться в случае изменения какой-либо точки данных в вашей таблице. В случае каких-либо изменений вам придется повторить вышеуказанные шаги еще раз, чтобы сгенерировать новую таблицу коэффициентов корреляции
Итак, это два быстрых и простых метода расчета коэффициента корреляции в Excel.
Надеюсь, вы нашли этот урок полезным!
Как рассчитать коэффициент корреляции в Excel (2 простых способа)
Функция КОРРЕЛ для определения взаимосвязи и корреляции в Excel
КОРРЕЛ – функция, применяемая для подсчета коэффициента корреляции между 2-мя массивами. Разберем на четырех примерах все способности этой функции.
Примеры использования функции КОРРЕЛ в Excel
Первый пример. Есть табличка, в которой расписана информация об усредненных показателях заработной платы работников компании на протяжении одиннадцати лет и курсе $. Необходимо выявить связь между этими 2-умя величинами. Табличка выглядит следующим образом:
24
Алгоритм расчёта выглядит следующим образом:

25
Отображенный показатель близок к 1. Результат:

26
Определение коэффициента корреляции влияния действий на результат
Второй пример. Два претендента обратились за помощью к двум разным агентствам для реализации рекламного продвижения длительностью в пятнадцать суток. Каждые сутки проводился социальный опрос, определяющий степень поддержки каждого претендента. Любой опрошенный мог выбрать одного из двух претендентов или же выступить против всех. Необходимо определить, как сильно повлияло каждое рекламное продвижение на степень поддержки претендентов, какая компания эффективней.

27
Используя нижеприведенные формулы, рассчитаем коэффициент корреляции:
- =КОРРЕЛ(А3:А17;В3:В17).
- =КОРРЕЛ(А3:А17;С3:С17).
Результаты:

28
Из полученных результатов становится понятно, что степень поддержки 1-го претендента повышалась с каждыми сутками проведения рекламного продвижения, следовательно, коэффициент корреляции приближается к 1. При запуске рекламы другой претендент обладал большим числом доверия, и на протяжении 5 дней была положительная динамика. Потом степень доверия понизилась и к пятнадцатым суткам опустилась ниже изначальных показателей. Низкие показатели говорят о том, что рекламное продвижение отрицательно повлияло на поддержку. Не стоит забывать, что на показатели могли повлиять и остальные сопутствующие факторы, не рассматриваемые в табличной форме.
Анализ популярности контента по корреляции просмотров и репостов видео
Третий пример. Человек для продвижения собственных роликов на видеохостинге Ютуб применяет соцсети для рекламирования канала. Он замечает, что существует некая взаимосвязь между числом репостов в соцсетях и количеством просмотров на канале. Можно ли про помощи инструментов табличного процессора произвести прогноз будущих показателей? Необходимо выявить резонность применения уравнения линейной регрессии для прогнозирования числа просмотров видеозаписей в зависимости от количества репостов. Табличка со значениями:

29
Теперь необходимо провести определение наличия связи между 2-мя показателями по нижеприведенной формуле:
0,7;ЕСЛИ(КОРРЕЛ(A3:A8;B3:B8)>0,7;”Сильная прямая зависимость”;”Сильная обратная зависимость”);”Слабая зависимость или ее отсутствие”)’ class=’formula’>
Если полученный коэффициент выше 0,7, то целесообразней применять функцию линейной регрессии. В рассматриваемом примере делаем:

30
Теперь производим построение графика:

31
Применяем это уравнение, чтобы определить число просматриваний при 200, 500 и 1000 репостов: =9,2937*D4-206,12. Получаем следующие результаты:

32
Функция ПРЕДСКАЗ позволяет определить число просмотров в моменте, если было проведено, к примеру, двести пятьдесят репостов. Применяем: 0,7;ПРЕДСКАЗ(D7;B3:B8;A3:A8);”Величины не взаимосвязаны”)’ class=’formula’>. Получаем следующие результаты:

33
Особенности использования функции КОРРЕЛ в Excel
Данная функция имеет нижеприведенные особенности:
- Не учитываются ячейки пустого типа.
- Не учитываются ячейки, в которых находится информация типа Boolean и Text.
- Двойное отрицание «–» применяется для учёта логических величин в виде чисел.
- Количество ячеек в исследуемых массивах обязаны совпадать, иначе будет выведено сообщение #Н/Д.
Виды моделей
Следующий вопрос, на который нужно ответить при построении прогноза: “А какие модели временного ряда бывают?”
Обычно выделяют два основных вида:
- Аддитивная модель: Уровень временного ряда = Тренд + Сезонность + Случайные отклонения
- Мультипликативная модель: Уровень временного ряда = Тренд * Сезонность * Случайные отклонения
Иногда также выделают смешанную модель в отдельную группу:
Смешанная модель: Уровень временного ряда = Тренд * Сезонность + Случайные отклонения
С моделями мы определились, но теперь возникает еще один вопрос: “А когда какую модель лучше использовать?”
Классический вариант такой: — Аддитивная модель используется, если амплитуда колебаний более-менее постоянная; — Мультипликативная — если амплитуда колебаний зависит от значения сезонной компоненты.
Пример:

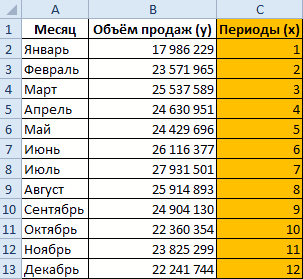
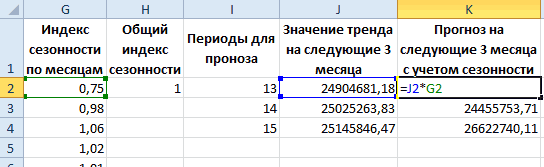
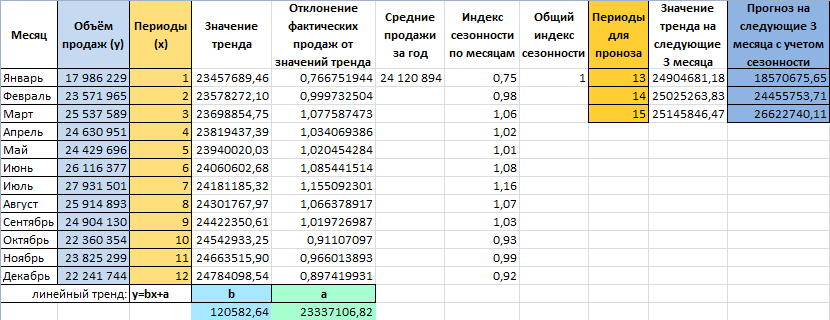
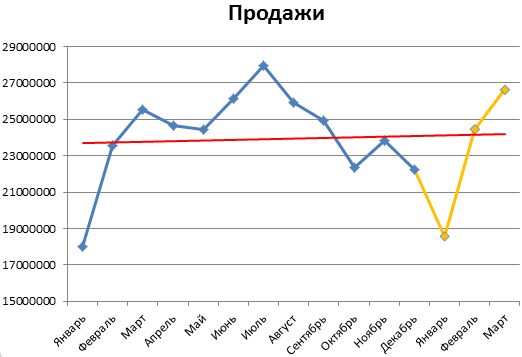
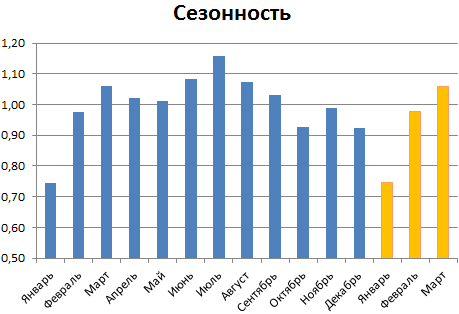
Рассчитываем прогноз продаж с учетом роста и сезонности:
- Задаём период, на который мы хотим рассчитать прогноз. Для этого продлеваем номера периодов временного ряда на 2 года и 3 месяца.
- Рассчитываем значения трена для будущих периодов. В уравнение y=bx+a подставляем рассчитанные коэффициенты тренда b и а, x – номер периода во временном ряде (от 61 до 87). Получаем y-значения линейного тренда для каждого будущего периода (см. вложенный файл).
- Рассчитываем прогноз. Для этого значения линейного тренда умножаем на коэффициенты сезонности.
Прогноз с учетом роста и сезонности готов.
Вы также можете руками корректировать прогноз, изменяя коэффициенты a и b линейного тренда y=bx+a, об этом подробно вы можете почитать в статье «О линейном тренде».
Для более точного прогнозирования продаж не достаточно учитывать рост и сезонность, необходимо также учесть еще дополнительные факторы, которые значительно влияют на объем продаж, такие как
-
реклама,
-
мероприятия по стимулированию сбыта,
-
ввод новых продуктов,
-
открытие новых направлений продаж,
-
спец. клиенты с разовыми значительными закупками
и т.д., но об этом в следующих статьях.
Точных вам прогнозов!
С помощью программы Forecast4AC PRO вы сможете рассчитывать прогноз с учетом роста и сезонности для более, чем 5000 строк одновременно одним нажатием клавиши. Легко и быстро!

- Novo Forecast Lite — автоматический расчет прогноза в Excel.
- 4analytics — ABC-XYZ-анализ и анализ выбросов в Excel.
- Qlik Sense Desktop и QlikView Personal Edition — BI-системы для анализа и визуализации данных.
Тестируйте возможности платных решений:
Novo Forecast PRO — прогнозирование в Excel для больших массивов данных.
Получите 10 рекомендаций по повышению точности прогнозов до 90% и выше.
Примеры как использовать
Как известно, любую функцию в таблицу можно вставить тремя способами:
1. Через специального мастера с выполнением последовательно двух шагов.

2. Через строку формул.

3. Сразу в ячейке через знак равно.

Рассмотри несколько примеров:
1. Необходимо посчитать возраст сотрудников на данный момент, зная даты рождения. Записываете в ячейку формулу =ГОД(СЕГОДНЯ())-ГОД(C3), где ГОД возвращает только годовую часть даты, а затем при помощи маркера автозаполнения применяете выражение ко всей таблице.

Чтобы решить эту задачу, необходимо использовать специальную функцию ДЕНЬНЕД с аргументом СЕГОДНЯ
При этом важно правильно выбрать тип числа. Для того, чтобы понедельник был единицей, а воскресенье семеркой, нужно использовать второй тип

3. Рассмотрим, как делать минус дни от текущего момента.
Формула выглядит вот так:
=СЕГОДНЯ()-2, т.е. будет результат в виде даты без двух дней. Точно также работает и увеличение даты.


Как видите, самостоятельно функция СЕГОДНЯ используется редко. Однако в сочетании с другими формулами и с несколькими условиями функциональность выражения резко возрастает.
Жми «Нравится» и получай только лучшие посты в Facebook ↓
Автоматизированный график дней рождений сотрудников в Excel
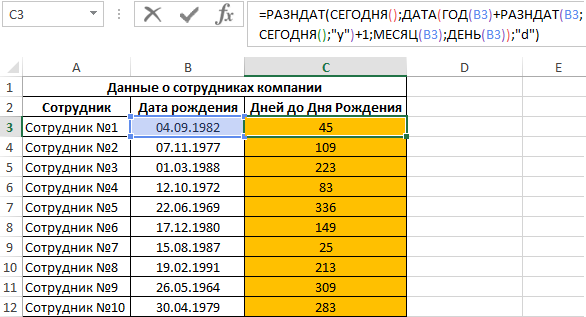
Пример 2. Используя таблицу из первого примера добавить столбец, в котором будет отображаться количество дней до дня рождения каждого сотрудника. Если день рождения сотрудника сегодня – отображать соответствующую запись.
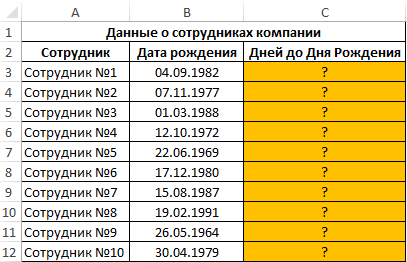
Для вычислений используем следующую формулу:
Функция РАЗНДАТ вычисляет разницу двух указанных дат и представляет полученное значение в зависимости от вида третьего аргумента, используемого для форматирования результатов. Например, для получения количества лет используется символ “y”, соответствующий первой букве слова «year» (год), “d” – для расчета количества дней (days – дни).
Выражение ДАТА(ГОД(B3)+РАЗНДАТ(B3;СЕГОДНЯ();”y”)+1;МЕСЯЦ(B3);ДЕНЬ(B3)) определяет дату следующего дня рождения сотрудника. Таким образом функция РАЗНДАТ находит количество дней между датой на сегодняшний день и датой следующего дня рождения и возвращает количество дней (“d”).
Результаты вычислений для остальных сотрудников:
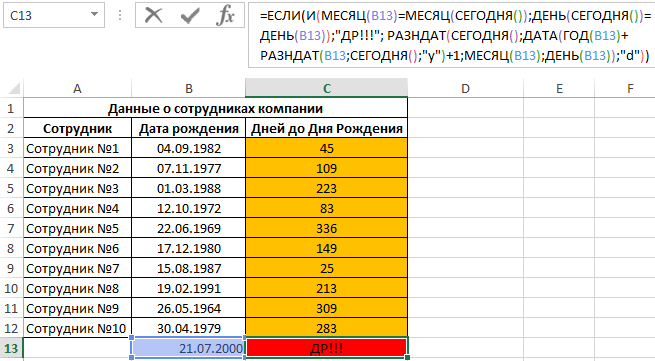
Для отображения записи о том, что день рождения сотрудника сегодня, используем следующую формулу:
Данная формула является немного модифицированным вариантом предыдущей формулы. В частности, выполняется проверка двух условий: И(МЕСЯЦ(B13)=МЕСЯЦ(СЕГОДНЯ());ДЕНЬ(СЕГОДНЯ())=ДЕНЬ(B13)), то есть, соответствуют ли номера месяцев и дней в дате рождения в сравнении с текущей датой. Если результат вычислений – ИСТИНА, будет возвращена текстовая строка «ДР», если ЛОЖЬ – производится расчет количества дней до следующего дня рождения.
Например, произведем расчет для сотрудника, у которого сегодня день рождения:
Шаг 5
Осталось оценить точность модели. Для этого будем использовать среднюю ошибку аппроксимации, которая поможет рассчитать ошибку в относительном выражении. Иными словами, это среднее отклонение расчетных значений от фактических, которое вычисляется по формуле:

yi — спрогнозированные уровни ряда,
yi* — фактические уровни ряда,
n — количество складываемых элементов.
Модель может считаться адекватной, если:
Итак, рассчитываем ошибку аппроксимации для нашего случая. Так как в основе нашего тренда лежит полином третьей степени, прогнозные значения начинают хорошо повторять фактические значения к концу 2016 года, думаю, я думаю, поэтому корректнее было бы рассчитать ошибку аппроксимации для значений 2017 года.
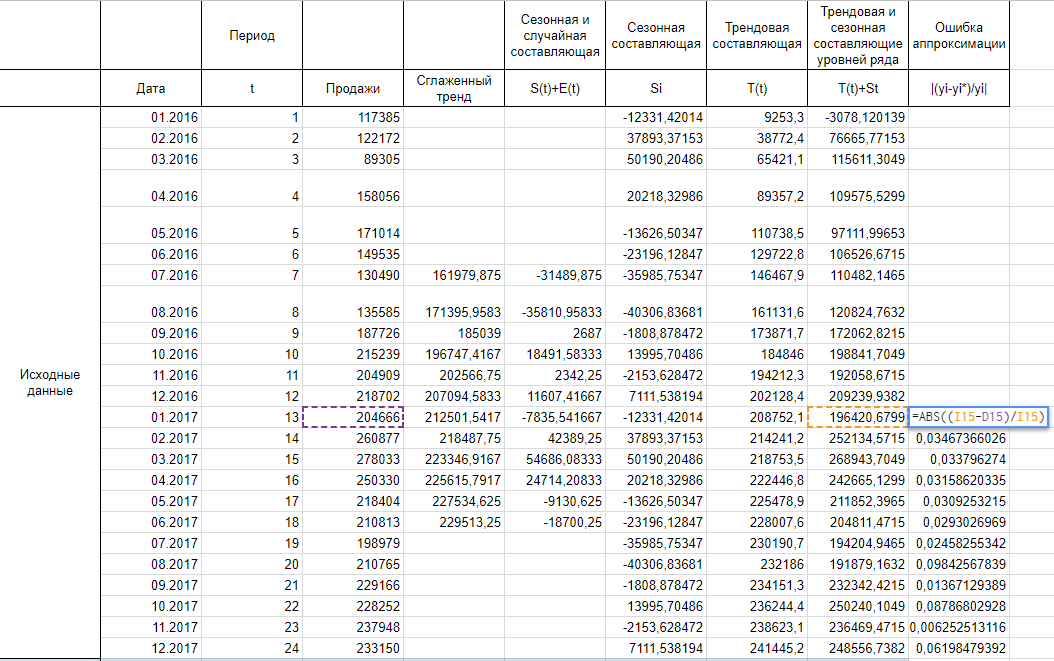
Сложив весь столбец с ошибками аппроксимации и поделив на 12, получаем среднюю ошибку аппроксимации 4,13%. Это значение меньше 15% и можем сделать вывод об адекватности модели.
Не забывайте, что прогнозы не бывают точными на 100%. Любые неожиданные внешние воздействия могут развернуть значения уровней ряда в неизвестном направлении
Прогноз посещаемости с помощью функции ТЕНДЕНЦИЯ в Excel
Пример 2. В кинотеатре фильмы показывают в различные сеансы, которые начинаются в 12:00, 16:00 и 21:00 соответственно. Каждый фильм имеет собственный рейтинг, в виде оценки от 1 до 10 баллов. Известны данные о посещаемости нескольких последних сеансов. Предположить, какой будет посещаемость для следующих фильмов:
- Рейтинг 7, сеанс 12:00;
- Рейтинг 9,5, сеанс 21:00;
- Рейтинг 8, сеанс 16:00.
Таблица исходных данных:
Для расчета используем функцию:
- Перед вводом функции необходимо выделить ячейки C11:C13;
- Расчет производим на основе диапазона значений A2:B10 (учитывается как время сеанса, так и рейтинг фильма)
В результате получим:
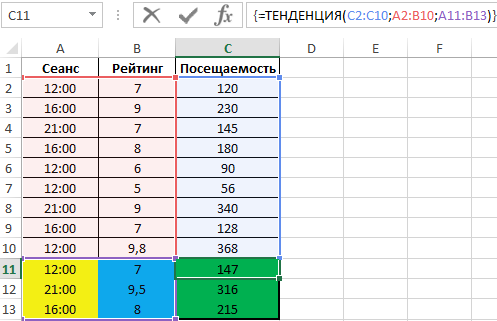
Не забывайте, что ТЕНДЕНЦИЯ является массивной функцией поэтому после ее ввода не забудьте выполнить ее в массиве. Для этого жмем не просто Enter, а комбинацию клавиш Ctrl+Shift+Enter. Если в строке формул по краям функции появились фигурные скобки , значит функция выполняется в массиве и все сделано правильно.
Из чего состоит временной ряд
Уровни временного ряда (Yt) представляют из себя сумму двух компонент:
- Регулярную составляющую
- Случайную составляющую
В свою очередь регулярная составляющая состоит из:
- Тренда
- Сезонности
- Циклической составляющей
Однако, в модели необязательно наличие всех этих компонент сразу.
Случайная компонента отражает влияние случайных возмущений на модель, которые по отдельности имеют незначительное воздействие, но суммарно их влияние ощущается.
То есть, в общем случае временной ряд представляет из себя наличие четырех составляющих:
- Тренд (Tt)
- Сезонность (St)
- Цикличность (Ct)
- Случайные возмущения (Et)
Циклическая компонента, по сравнению с сезонностью, имеет более длительный эффект и меняется от цикла к циклу. Поэтому, ее обычно объединяют с трендом.
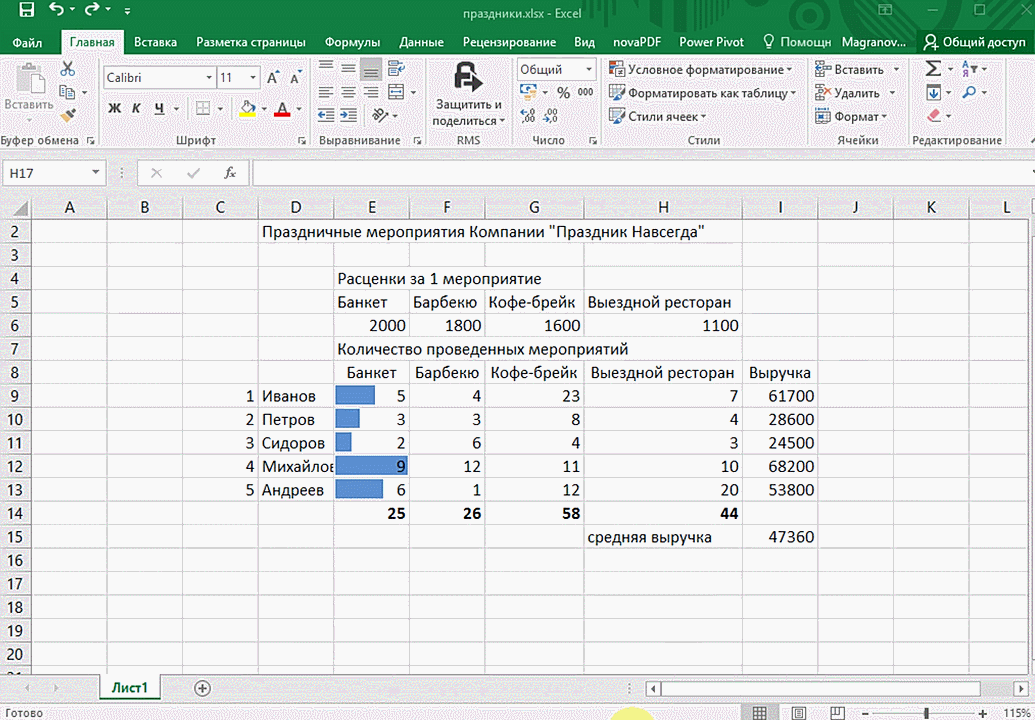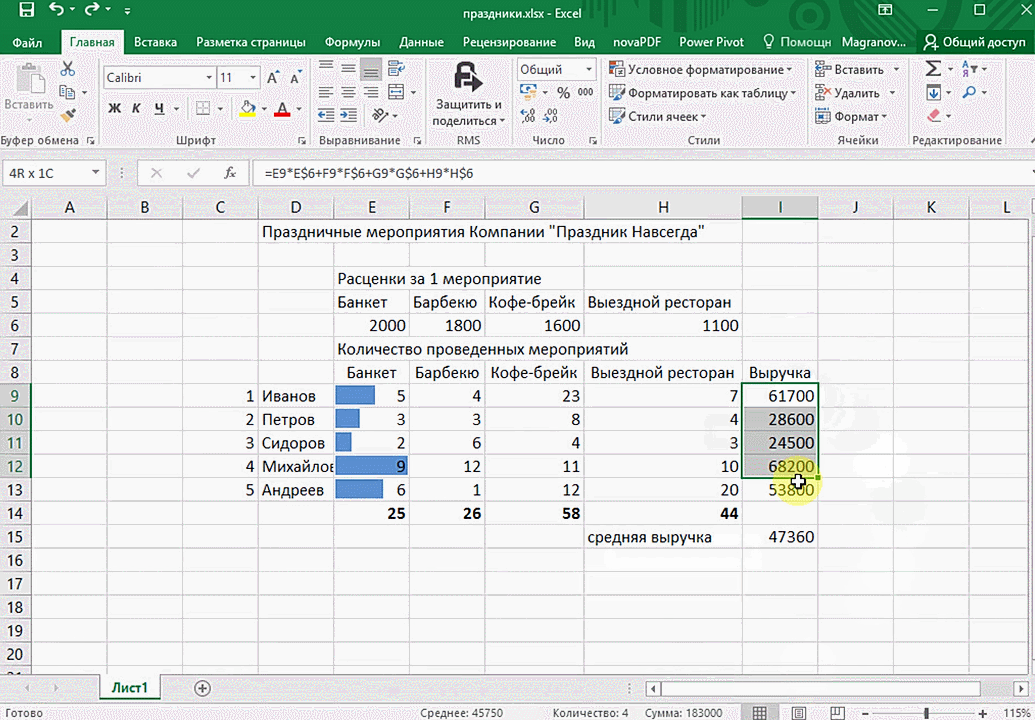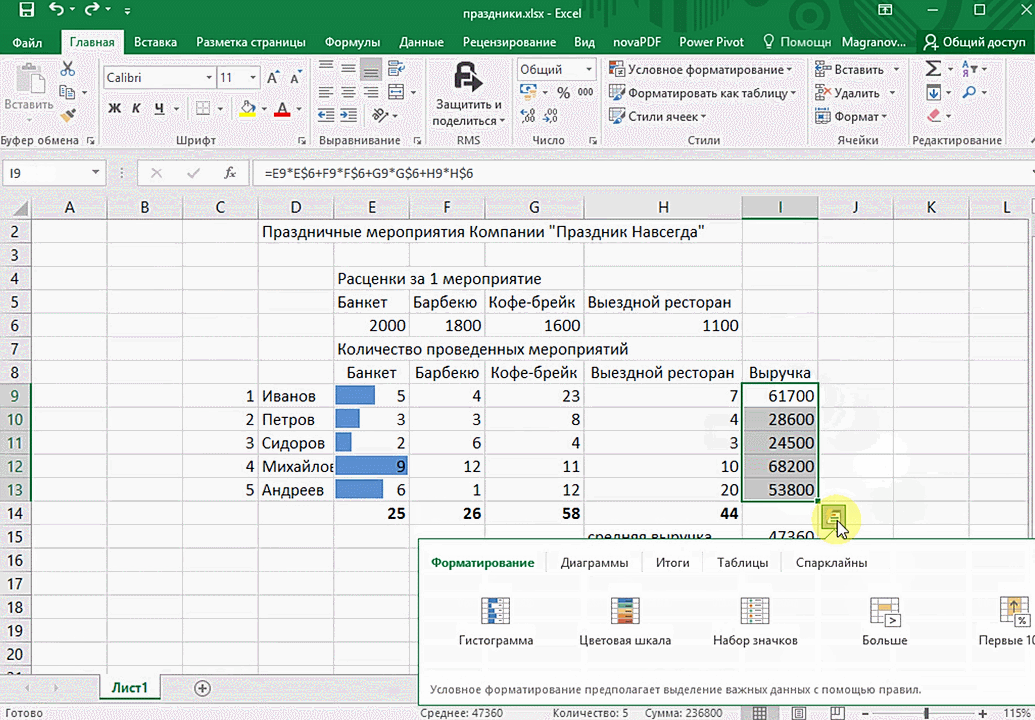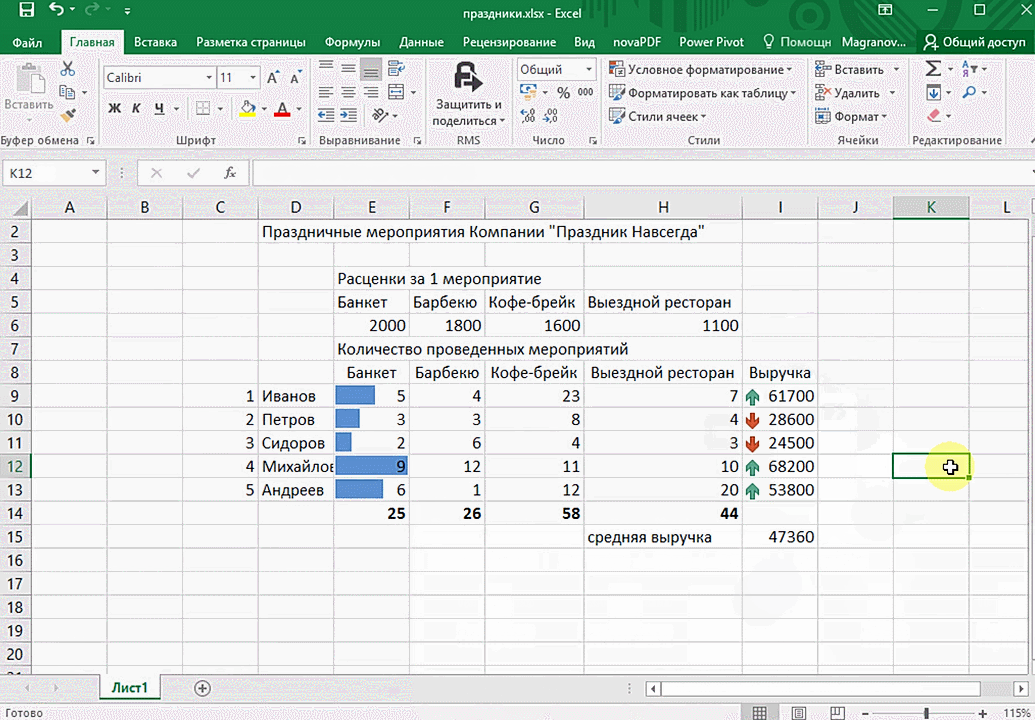
Быстрый анализ в Excel
Предыдущий способ действительно хорош, потому что позволяет составлять реальные прогнозы, основываясь на статистических показателях. Но этот метод позволяет фактически проводить полноценную бизнес-аналитику. Очень классно, что эта возможность создана максимально эргономичной, поскольку для достижения желаемого результата необходимо совершить буквально несколько действий. Никаких ручных подсчетов, записи каких-либо формул. Достаточно просто выбрать диапазон, который будет анализироваться и задать конечную цель.
Как работать
Итак, чтобы работать, нам надо надо открыть файл, в котором содержится тот набор данных, который надо анализировать и выделить соответствующий диапазон. После того, как мы его выделим, у нас автоматически появится кнопка, дающая возможность составить итоги или же выполнить набор других действий. Называется она быстрым анализом. Также мы можем определить суммы, которые автоматически будут проставлены внизу. Более наглядно посмотреть, как это работает, можете на этой анимации.
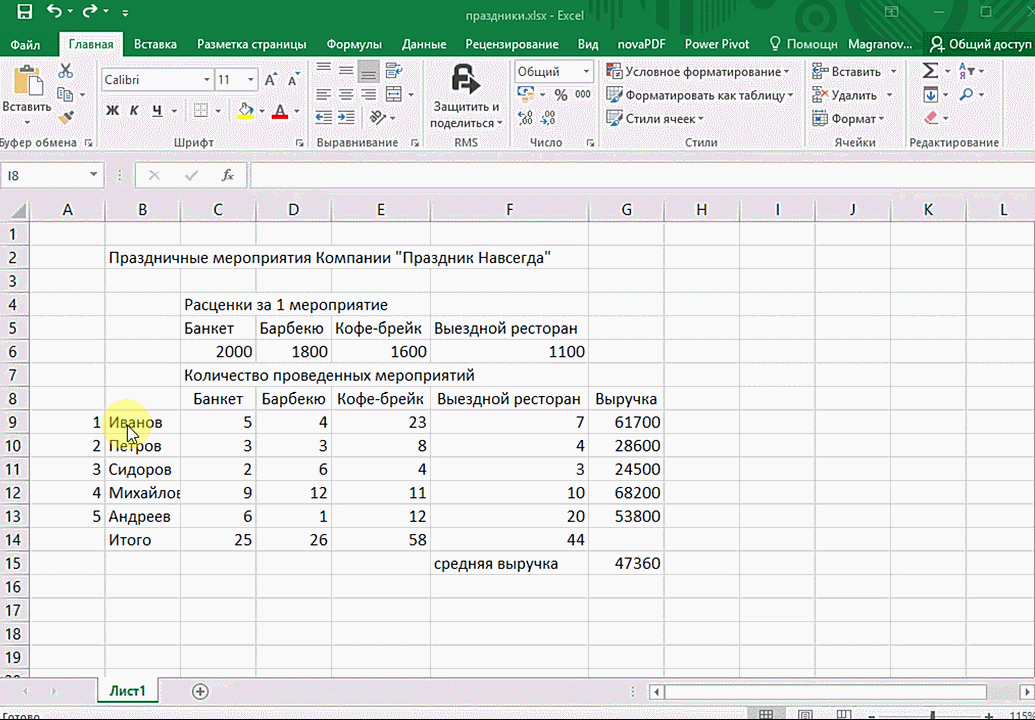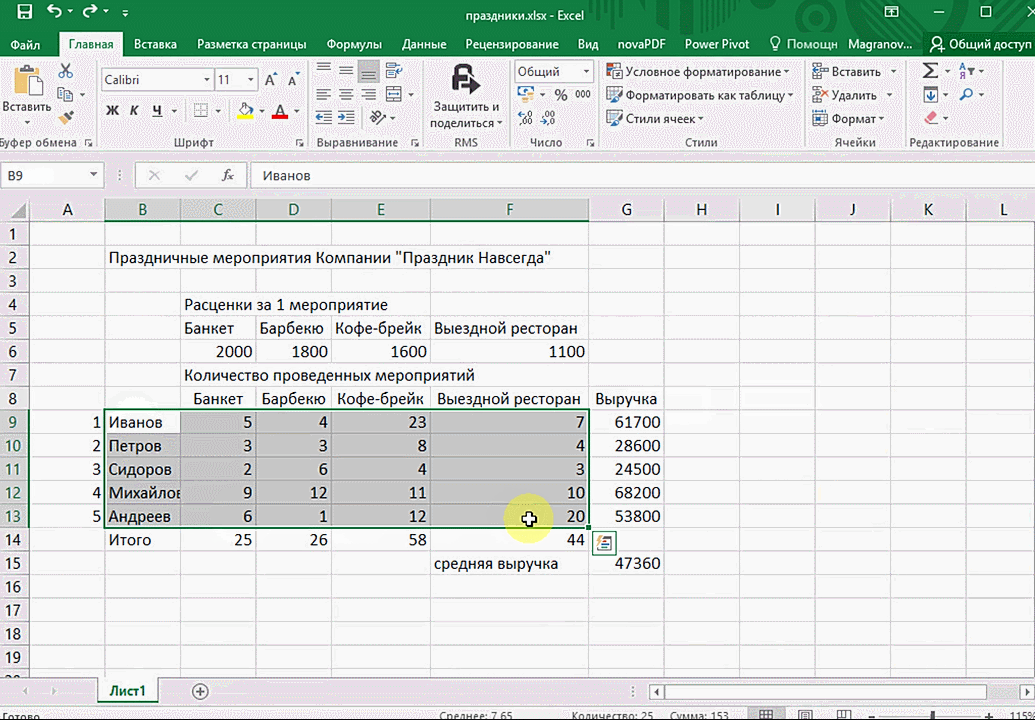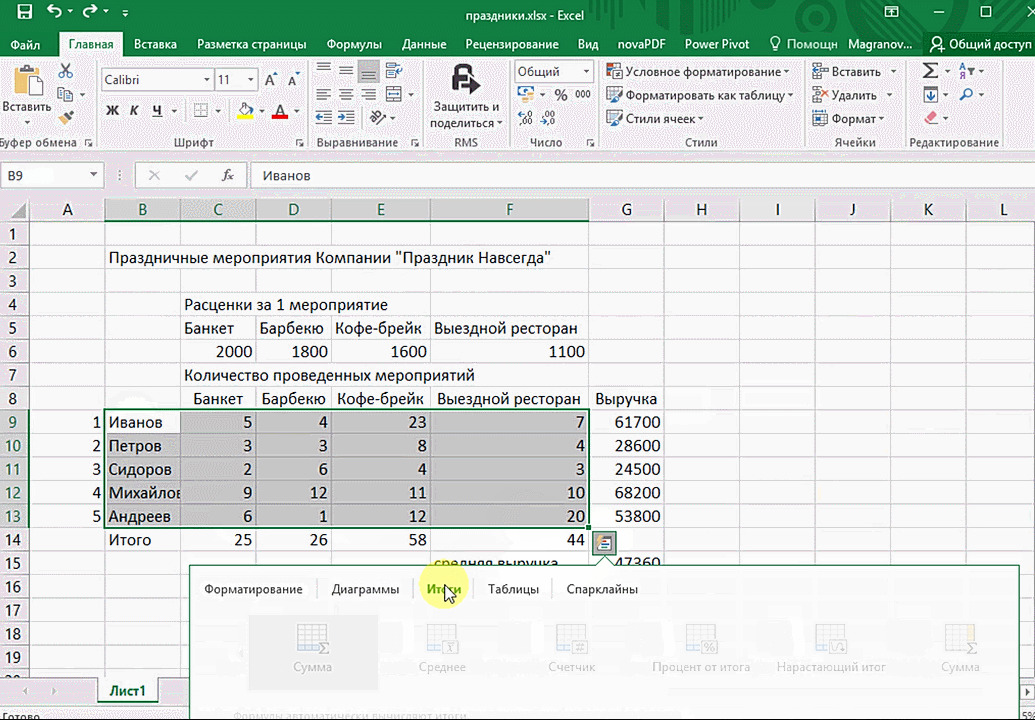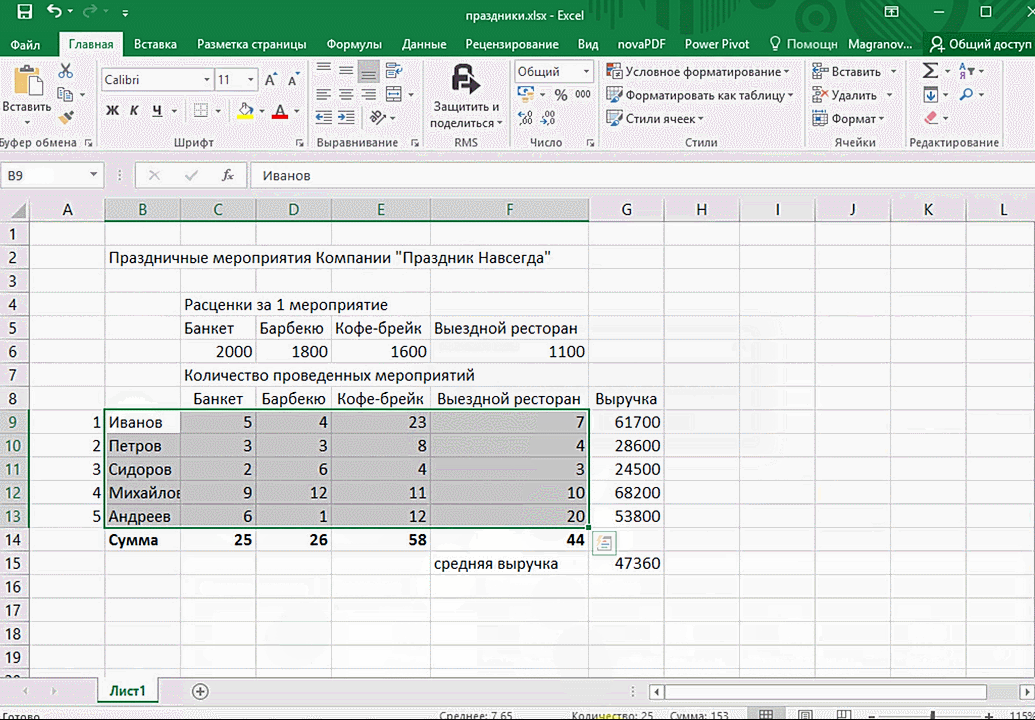
Функция быстрого анализа позволяет также по-разному форматировать получившиеся данные. А определить, какие значения больше или меньше, можно непосредственно в ячейках гистограммы, которая появляется после того, как мы настроим этот инструмент. 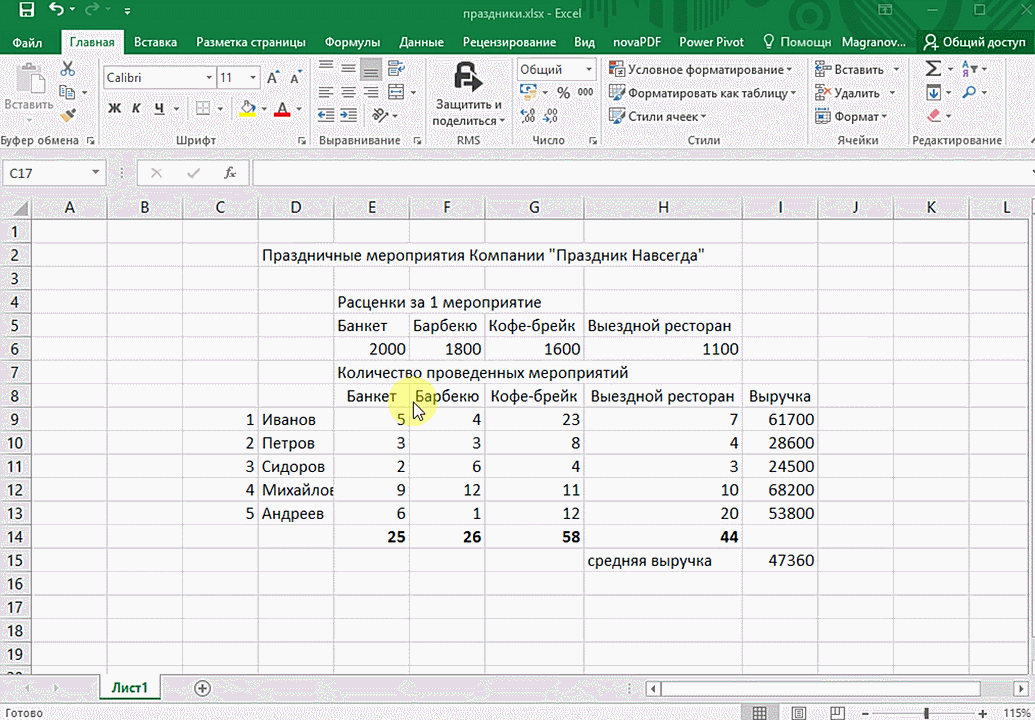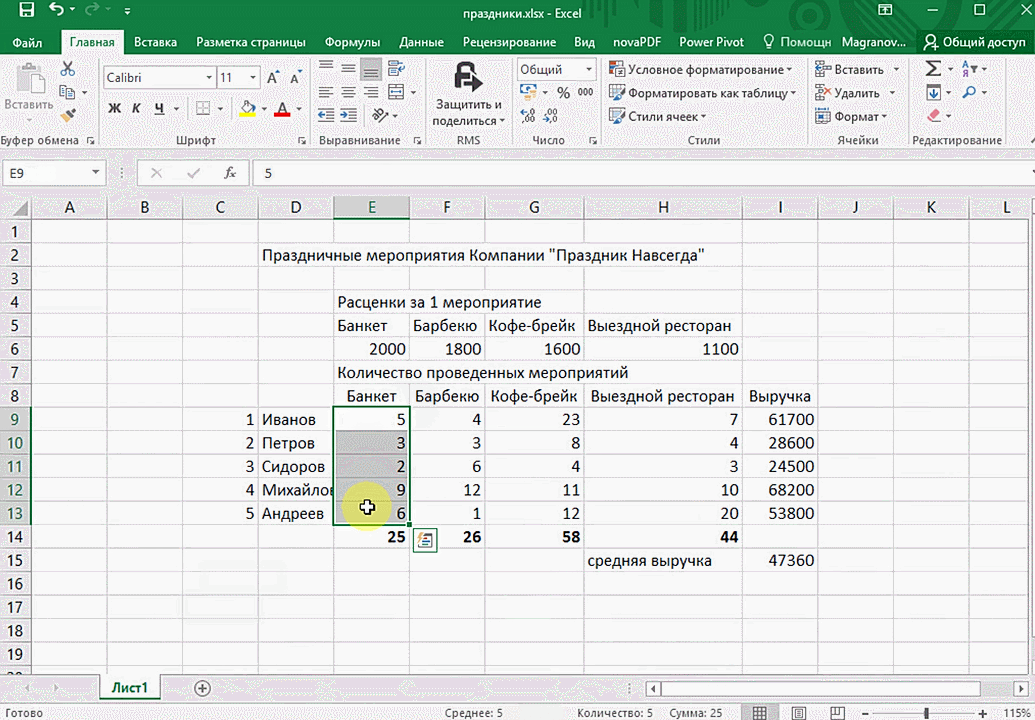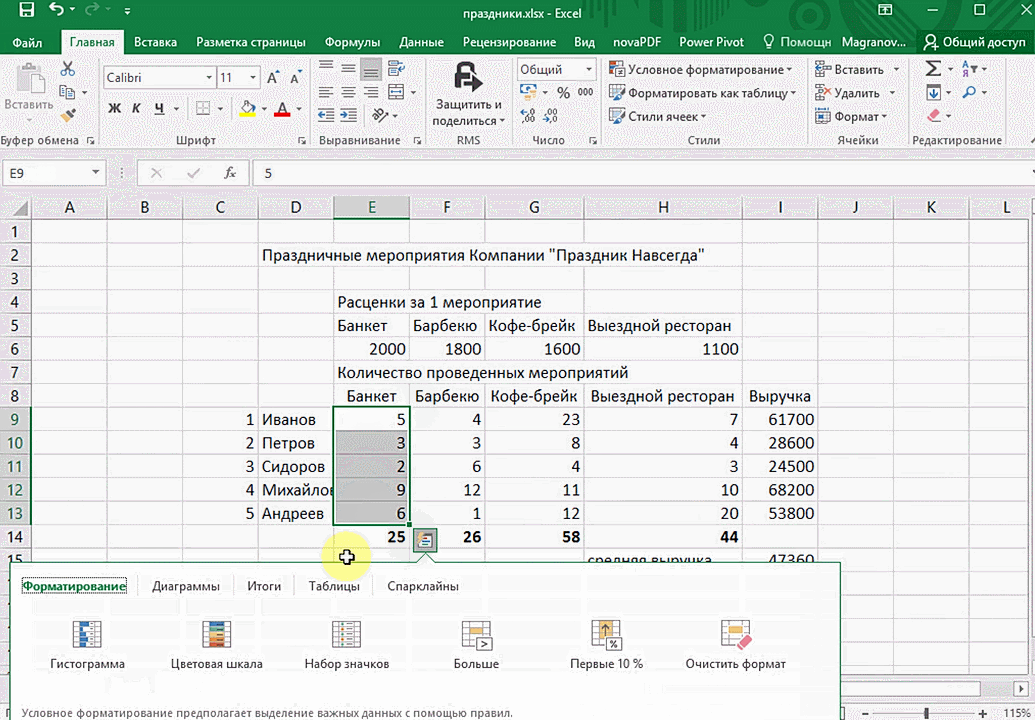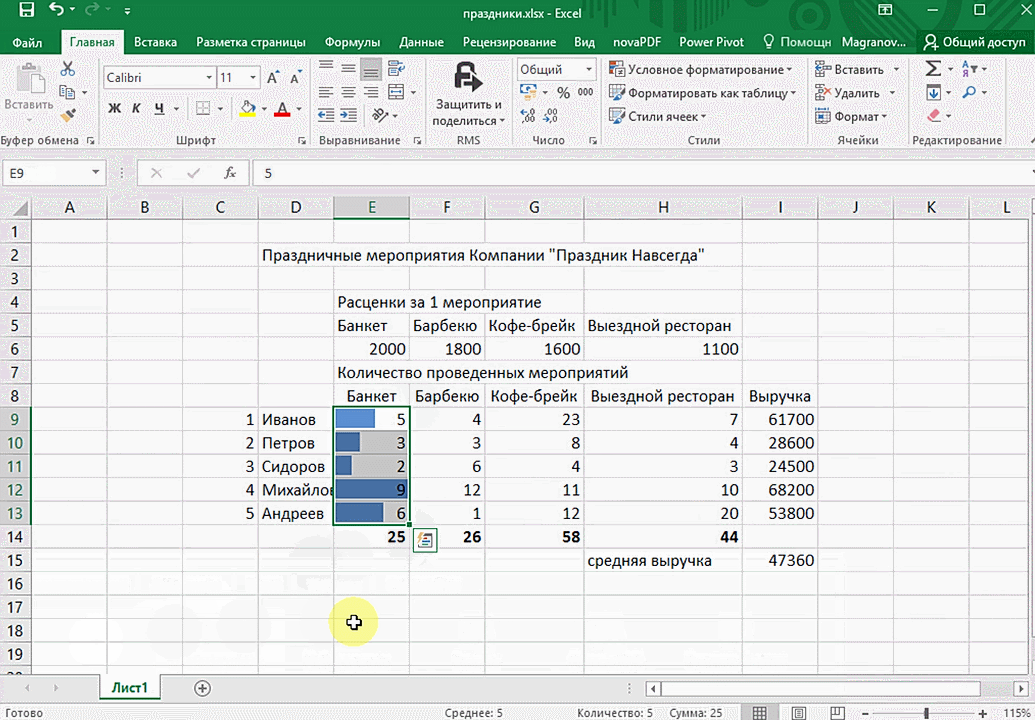
Также пользователь может поставить самые разные маркеры, которые обозначают большие и меньшие значения относительно тех, которые есть в выборке. Так, зеленым цветом будут показываться самые большие значения, а красным – наиболее маленькие.
Очень хочется верить, что эти приемы позволят вам значительно повысить эффективность вашей работы с электронными таблицами и максимально быстро добиться всего, что вы желаете. Как видим, эта программа для работы с электронными таблицами дает очень широкие возможности даже в стандартном функционале. А что уже говорить про дополнения, которых очень много на просторах интернета
Важно только обратить внимание, что все аддоны должны быть тщательно проверены на вирусы, потому что модули, написанные другими людьми, могут содержать вредоносный код. Если же надстройки разработаны компанией Майкрософт, то ее можно использовать смело
Пакет анализа от Майкрософт – очень функциональная надстройка, которая делает пользователя настоящим профессионалом. Она позволяет выполнить почти любую обработку количественных данных, но она довольно сложная для начинающего пользователя. На официальном сайте справки Майкрософт есть детальная инструкция по тому, как использовать разные виды анализа с помощью этого пакета.
Виды моделей временного ряда
Обычно, выделяют две модели временного ряда и третью — смешанную.
- Аддитивная модель
Мультипликативная модель
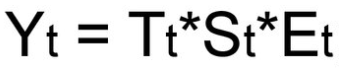
Смешанная модель
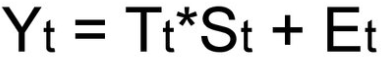
При выборе необходимой модели временного ряда смотрят на амплитуду колебаний сезонной составляющей. Если ее колебания относительно постоянны, то выбирают аддитивную модель. То есть, амплитуда колебаний примерно одинакова:
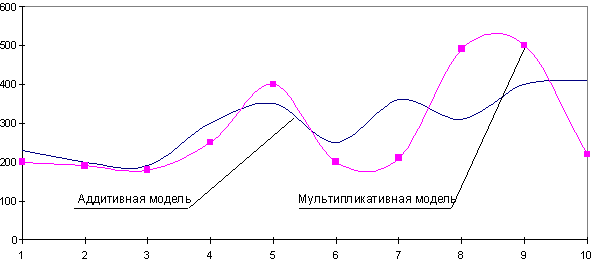
Если амплитуда сезонных колебаний возрастает или уменьшается, строят мультипликативную модель временного ряда, которая ставит уровни ряда в зависимость от значений сезонной компоненты.
Построение этих моделей сводится к расчету тренда (Tt), сезонности (St) и случайных возмущений (Et) для каждого уровня ряда (Yt).
Возможности инструмента
Рассмотрим подробнее настройки функции. Для перехода в окно параметров из выпадающего списка нужно выбрать последнюю строчку.

Окно содержит четыре настройки, в которые входят цвет, объем и тип линии, а также параметры самого инструмента.

Параметры линии тренда можно условно поделить на четыре блока:
- Тип приближения.
- Название полученной кривой, которое формируется автоматически или может быть задано пользователем.
- Блок прогнозирования, который позволяет продлить линию тренда на заданное количество периодов вперед или назад, на основании имеющихся данных. Что позволяет оценить дальнейшее изменение исследуемой величины.
- Дополнительные опции, которые отражают математическую составляющую кривой. Самой интересной и полезной строчкой здесь является величина достоверности. Если значение коэффициента близко к единице, то ошибка минимальна и дальнейший прогноз будет достаточно точным.

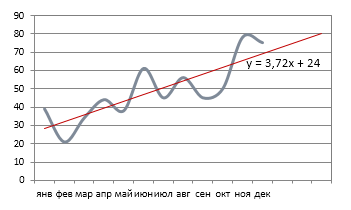
Выведем на исходный график уравнение линии и коэффициент достоверности.

Как видите, значение близко к 0,5, это говорит о низкой достоверности полученной линии тренда, и дальнейший прогноз будет ошибочным.
Виды моделей временного ряда
Обычно, выделяют две модели временного ряда и третью — смешанную.
- Аддитивная модель
Мультипликативная модель
Смешанная модель
При выборе необходимой модели временного ряда смотрят на амплитуду колебаний сезонной составляющей. Если ее колебания относительно постоянны, то выбирают аддитивную модель. То есть, амплитуда колебаний примерно одинакова:
Если амплитуда сезонных колебаний возрастает или уменьшается, строят мультипликативную модель временного ряда, которая ставит уровни ряда в зависимость от значений сезонной компоненты.
Построение этих моделей сводится к расчету тренда (Tt), сезонности (St) и случайных возмущений (Et) для каждого уровня ряда (Yt).
Шаг 4
Имея рассчитанные значения S(t) и T(t) мы можем рассчитать прогнозные значения уровней ряда Y(t). Для этого накладываем уровни сезонности на тренд.
Теперь построим график известных значений Y(t) и спрогнозированных за 2018 год.
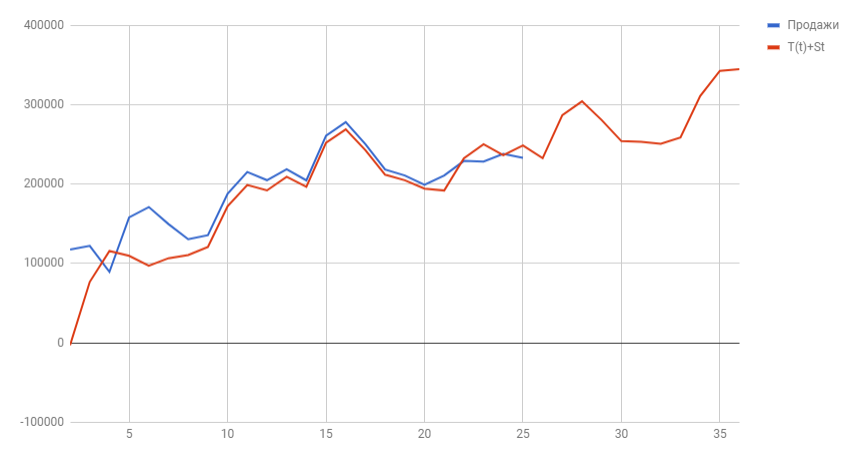
Вот мы и нашли спрогнозированные значения уровней продаж на 2018 год. Значения отражают возрастающую тенденцию и сезонные пики. Конечно, эти данные не дают 100% точности, ведь существует множество внешних воздействий, которые могут изменить направление тренда, поэтому к прогнозным значениям обычно строят доверительный интервал, это такой коридор, внутри которого могут колебаться прогнозные значения с заданной вероятностью (чаще всего выбирают 95%). Но об этом я расскажу в следующей статье.
Виды сезонности
Обычно выделяют три вида сезонности, они отличаются по спаду в разнице продаж:
Умеренная: разница в пределах 10-20%, практически не влияет на финансовое самочувствие компании. Характерно для товаров повседневного спроса. Продавцы и поставщики чувствуют себя комфортно на протяжении всего года;
Яркая: разница спада продаж достигает 30-40%, приходится стимулировать спрос, чтобы не случился кассовый разрыв;
Жёсткая: падение продаж на 50-100%, нет шансов вернуть объёмы на прежние показатели. Есть ли смысл стимулировать спрос на новогодние ёлочные игрушки и валентинки в августе?
Быстрый прогноз функцией ПРЕДСКАЗ (FORECAST)
Умение строить прогнозы, предсказывая (хотя бы примерно!) будущее развитие событий — неотъемлемая и очень важная часть любого современного бизнеса. Само-собой, это отдельная весьма сложная наука с кучей методов и подходов, но часто для грубой повседневной оценки ситуации достаточно простых техник. Одна из них — это функция ПРЕДСКАЗ (FORECAST) , которая умеет считать прогноз по линейному тренду.
Принцип работы этой функции несложен: мы предполагаем, что исходные данные можно интерполировать (сгладить) некой прямой с классическим линейным уравнением y=kx+b:
Построив эту прямую и продлив ее вправо за пределы известного временного диапазона — получим искомый прогноз.
Для построения этой прямой Excel использует известный метод наименьших квадратов. Если коротко, то суть этого метода в том, что наклон и положение линии тренда подбирается так, чтобы сумма квадратов отклонений исходных данных от построенной линии тренда была минимальной, т.е. линия тренда наилучшим образом сглаживала фактические данные.
Excel позволяет легко построить линию тренда прямо на диаграмме щелчком правой по ряду — Добавить линию тренда (Add Trendline), но часто для расчетов нам нужна не линия, а числовые значения прогноза, которые ей соответствуют. Вот, как раз, их и вычисляет функция ПРЕДСКАЗ (FORECAST) .
Синтаксис функции следующий
=ПРЕДСКАЗ( X ; Известные_значения_Y ; Известные_значения_X )
- Х — точка во времени, для которой мы делаем прогноз
- Известные_значения_Y — известные нам значения зависимой переменной (прибыль)
- Известные_значения_X — известные нам значения независимой переменной (даты или номера периодов)
Линейный регрессионный анализ
Выделяют несколько разновидностей регрессий: линейная, гиперболическая, множественная, логарифмически линейная, нелинейная, обратная, парная.
В рамках данной статьи мы рассмотрим линейную регрессию. В общем виде ее функция выглядит так:
В данном уравнении:
- Y – переменная, влияние на которую нужно найти;
- X – факторы, влияющие на переменную;
- A – коэффициенты регрессии, определяющие значимости факторов;
- N – общее количество факторов.
Чтобы было понятнее, давайте разберем конкретный практический пример. Допустим, у нас есть таблица, в которой представлена информация по среднесуточной температуре и количеству осадков с разбивкой по месяцам.

Наша задача – выяснить, как температура влияет на осадки. Приступи к ее выполнению.
- Щелкаем по кнопке “Анализ данных”.
- В открывшемся окошке отмечаем пункт “Регрессия”, после чего щелкаем OK.
- Перед нами появится окно, в котором нужно настроить параметры регрессии:
- в поле “Входной интервал_Y” пишем координаты диапазона ячеек, в которых находятся переменные, влияние на которые нам нужно выяснить. У нас это столбец “Количество осадков, мм”. Координаты диапазона можно указать как вручную, используя клавиши на клавиатуре, так и выделив его в самой таблице с помощью зажатой левой кнопки мыши.
- в поле “Входной интервал_X” указываем координаты диапазона ячеек с данными, влияние которых нам нужно найти. В нашем случае – это столбец “Среднесуточная температура”.
- Остальные параметры не являются обязательными и, чаще всего, остаются незаполненными. У нас есть возможность установить метки, значения уровня надежности в процентах, константу-ноль, график нормальной вероятности и т.д. Пожалуй, самым важным здесь является способ вывода результатов анализа. Доступны следующие варианты: на новом листе (по умолчанию), в новой книге или в указанном диапазоне на этом же листе. Мы оставим все как есть и жмем кнопку OK.
