Файл robots.txt
Содержание:
- Закрыть сайт от индексации в файле .htaccess
- Закрытие контента от индексации при помощи Javacascript
- Директивы файла robots.txt для wordpress
- Поисковики индексируют HTTPS-версию сайта, а браузер потом пугает входящих?! Хватит это терпеть!
- Пример настройки файла robots.txt
- Закрыть от индексации ссылки в WordPress
- Запрет индексации, robots и htaccess. Закрыть от индексации страницы, папки, поддомены, ссылки.
- Зачем необходимо закрывать внешние ссылки от индексации
- Запрещаем индексацию страницы
- Маски к директивам файла robots.txt для wordpress
- Нестандартные Директивы
- Блокировка индексации сайта robots.txt
- Директивы метатега robots и X-Robots-Tag
Закрыть сайт от индексации в файле .htaccess
Способ первый
В файл .htaccess вписываем следующий код:
SetEnvIfNoCase User-Agent "^Googlebot" search_bot SetEnvIfNoCase User-Agent "^Yandex" search_bot SetEnvIfNoCase User-Agent "^Yahoo" search_bot SetEnvIfNoCase User-Agent "^Aport" search_bot SetEnvIfNoCase User-Agent "^msnbot" search_bot SetEnvIfNoCase User-Agent "^spider" search_bot SetEnvIfNoCase User-Agent "^Robot" search_bot SetEnvIfNoCase User-Agent "^php" search_bot SetEnvIfNoCase User-Agent "^Mail" search_bot SetEnvIfNoCase User-Agent "^bot" search_bot SetEnvIfNoCase User-Agent "^igdeSpyder" search_bot SetEnvIfNoCase User-Agent "^Snapbot" search_bot SetEnvIfNoCase User-Agent "^WordPress" search_bot SetEnvIfNoCase User-Agent "^BlogPulseLive" search_bot SetEnvIfNoCase User-Agent "^Parser" search_bot
Каждая строчка для отдельной поисковой системы
Способ второй и третий
Для всех страниц на сайте подойдет любой из вариантов — в файле .htaccess прописываем любой из ответов сервера для страницы, которую нужно закрыть.
- Ответ сервера — 403 Доступ к ресурсу запрещен -код 403 Forbidden
- Ответ сервера — 410 Ресурс недоступен — окончательно удален
Способ четвертый
Запретить индексацию с помощью доступа к сайту только по паролю
В файл .htaccess, добавляем такой код:
AuthType Basic AuthName "Password Protected Area" AuthUserFile /home/user/www-auth/.htpasswd Require valid-user
home/user/www-auth/.htpasswd - файл с паролем - пароль задаете Вы сами.
Авторизацию уже увидите, но она пока еще не работает
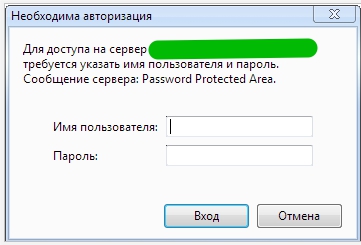
Теперь необходимо добавить пользователя в файл паролей:
htpasswd -c /home/user/www-auth/.htpasswd USERNAME
USERNAME это имя пользователя для авторизации. Укажите свой вариант.
Закрытие контента от индексации при помощи Javacascript
При использовании данного метода текст, блок, код, ссылка или любой другой контент кодируется в Javascript, а далее Данный скрипт закрывается от индексации при помощи Robots.txt
Такой Метод можно использовать для того, чтобы скрыть например Меню от индексации, для лучшего контроля над распределением ссылочного веса. К примеру есть вот такое меню, в котором множество ссылок на разные категории. В данном примере это — порядка 700 ссылок, если не закрыть которые можно получить большую кашу при распределении веса.

Данный метод гугл не очень то одобряет, так-как он всегда говорил, что нужно отдавать одинаковый контент роботам и пользователям. И даже рассылал письма в средине прошлого года о том, что нужно открыть для индексации CSS и JS файлы.
Подробнее об этом можно почитать тут.
Однако в данный момент это один из самых действенных методов по борьбе с индексацией нежелательного контента.
Точно также можно скрывать обычный текст, исходящие ссылки, картинки, видео материалы, счетчики, коды. И все то, что вы не хотите показывать Роботам, или что является не уникальным.
Директивы файла robots.txt для wordpress
Теперь давайте рассмотрим поподробнее:
1 – 16 строки блок настроек для всех роботов
User-agent: — Это обязательная директива, определяющая поискового агента. Звездочка говорит, что директива для роботов всех поисковых систем. Если блок предназначен для конкретного робота, то необходимо указать его имя, например Yandex, как в 18 строке.
По умолчанию для индексирования разрешено всё. Это равнозначно директиве Allow: /.
Поэтому для запрета индексирования конкретных папок или файлов используется специальная директива Disallow: .
В нашем примере с помощью названий папок и масок названий файлов, сделан запрет на все служебные папки вордпресса, такие как admin, themes, plugins, comments, category, tag… Если указать директиву в таком виде Disallow: /, то будет дан запрет индексирования всего сайта.
Allow: — как я уже говорил директива разрешающая индексирование папок или файлов. Её нужно использовать когда в глубине запрещённых папок есть файлы которые всё же надо проиндексировать.
В моём примере строка 3 Disallow: /wp-admin — запрещает индексирование папки /wp-admin, а 14 строка Allow: /wp-admin/admin-ajax.php — разрешает индексирование файла /admin-ajax.php расположенного в запрещенной к индексированию папке /wp-admin/.
17 — Пустая строка (просто нажатие кнопки Enter без пробелов)
18 — 33 блок настроек конкретно для агента Яндекса (User-agent: Yandex). Как вы заметили этот блок полностью повторяет все команды предыдущего блока. И возникает вопрос: «А на фига такая заморочка?». Так вот это всё сделано всего лишь из-за нескольких директив которые рассмотрим дальше.
34 — Crawl-delay — Необязательная директива только для Яндекса. Используется когда сервер сильно нагружен и не успевает отрабатывать запросы робота. Она позволяет задать поисковому роботу минимальную задержку (в секундах и десятых долях секунды) между окончанием загрузки одной страницы и началом загрузки следующей. Максимальное допустимое значение 2,0 секунды. Добавляется непосредственно после директив Disallow и Allow.
35 — Пустая строка
Host: https://site.ru
37 — Пустая строка (просто нажатие кнопки Enter без пробелов) обязательно должна присутствовать.
38 — Sitemap: http://site.ru/sitemap.xml — адрес расположения файла (файлов) карты сайта sitemap.xml (ОБЯЗАТЕЛЬНАЯ директива), располагается в конце файла после пустой строки и относится ко всем блокам.
Поисковики индексируют HTTPS-версию сайта, а браузер потом пугает входящих?! Хватит это терпеть!
Если ты веб-мастер и у сайта есть https-версия, значит либо купишь сертификат, либо закроешь ее от индесации. Для счастья вполне достаточно тёплого-лампового http. Этого я бы и оставил.
Ты наверное того же мнения, а значит, первым делом, лезешь в Гугл или Яндекс с запросом «как закрыть от индексации https-версию сайта» и находишь заветную формулу. А она не работает. Но давай без забеганий. Может именно у тебя сработает этот мэйнстримный вариант.
Итак, тебе предлагают, в пару к файлу robots.txt создать https.txt и разместить его туда же (в корень сайта). В https.txt пропиши вот эти две строчки:
User-agent: * Disallow: /
Сохрани и утри проступившую испарину. Первая часть Марлезонского балета успешно комплитнулась, с чем я тебя и поздравляю. Все тебе хлопают в ладоши, хлопают, хлопают, кончили хлопать. Проследуем в следующий зал.
Эту часть делай. Она по-любому понадобится.
А вот следующая работает не у всех.
Открываешь файл .htaccess (если в корне сайта нет такого, создай).
Находишь строку RewriteEngine on (если нету, вставь) и сразу под ней добавь:
RewriteCond %{HTTPS} on
RewriteRule ^robots\.txt$ https.txt
Сохрани и проверь работает-ли. Для этого открой сайт в двух вкладках. Допустим, домен сайта lexium.ru
Значит в первой вкладке вставишь такую ссылку https://www.lexium.ru/robots.txt
Во второй эту — https://www.lexium.ru/robots.txt
Если шаманство с .htaccess сработало, текст страничек в этих вкладках отличается. Во второй он вот такой:
User-agent: * Disallow: /
Значит всё отлично. Дальше можно не читать.
Если не сработало, придется лезть на сервер и исправлять конфиг ngnix для домена.
Если на хостинге, на сервере, на VDS, на VPS (не знаю что там у тебя) установлена ISP-панель, то считай повезло. Если нет, значит статья почти бесполезна. Хотя, как знать? Дальше покажу в картинках
Хотел в стихах, но… а, не важно
Заходим в панель.
В левом вертикальном меню клацаем пункт WWW Домены.
Находим нужный в списке.
Клацаем по нему.
В верхнем горизонтальном меню пиктограмм кликаем кнопку «Конфиг».
Появляется окно редактирования конфига
В нём (внимание!) выбирай вкладку Ngnix!. Теперь ты видишь нужный конфиг.
В нём находишь кучку директив location, после которых идут некие буквы, потом открывающая фигурная скобка
Ниже еще несколько строчек, завершающихся закрывающейся фигурной скобкой.
Эта конструкция составляет цельный блок.
Я пролистал все блоки location и после закрывающей скобки последнего, вставил вот такой:
Теперь ты видишь нужный конфиг.
В нём находишь кучку директив location, после которых идут некие буквы, потом открывающая фигурная скобка. Ниже еще несколько строчек, завершающихся закрывающейся фигурной скобкой.
Эта конструкция составляет цельный блок.
Я пролистал все блоки location и после закрывающей скобки последнего, вставил вот такой:
location /robots.txt {
if ($scheme = "https") {
rewrite (.*) /https.txt;
}
root $root_path;
}
Внизу окошка есть кнопки ОК и Отмена. Ты, есссно, жмакаешь ОК. Если кнопок не видно, значит убрались ниже экрана. Листать, в данном случае, гиблое дело. Нажми пару раз «Ctrl -» (кнопку Ctrl и кнопку «минус» одновременно). Это уменьшит масштаб странички и кнопочки станут доступны.
После ОК, конфиг сохраняется, а ты, если всё сделано правильно, радуешься победе.
Как там у тебя, понятия не имею, но надеюсь на лучшее.
Помогло? Зашли Админу на чай.
Пример настройки файла robots.txt
Давайте разберем на примере, как настроить файл robots.txt. Ниже находится пример файла, значение команд из которого будет подробно рассмотрено в статье.
В данном файле мы видим, что от поисковых систем Яндекс и Google закрыты от индексации все документы на сайте, кроме страницы /test.html
Остальные поисковые системы могут индексировать все документы, кроме:
- документов в разделах /personal/ и /help/
- документа по адресу /index.html
- документов, адреса которых включают параметр clear_cache=Y
Последние две команды требуют отдельного внимания.
Командой /index.html закрыт от индексации дубль главной страницы сайта. Как правило, главная страница доступна по двум адресам:
- site.com
- site.com/index.html или site.com/index.php
Если не закрыть второй адрес от индексации, то в поиске может появиться две главных страницы!
Команда Disallow: /*?clear_cache=Y закрывает от индексации все страницы, в адресах которых используется последовательность символов ?clear_cache=Y. Часто различный функционал на сайте, например, сортировки или формы подбора добавляют к адресам страниц различные параметры, из-за чего генерируется множество страниц-дублей. Закрывая дубли с параметрами от индексации, Вы решаете проблему попадания дублей в базу поисковых систем.
Посмотрите, какие страницы необходимо закрывать от индексации, в статье про проведение технического аудита сайта.
Закрыть от индексации ссылки в WordPress
Как новичку, так и опытному вебмастеру легче использовать плагины: они удобные, не требуют знания языков программирования, устанавливаются и настраиваются в два клика. Изменять файл functions.php через ПУ хостинга я не рекомендую.
Можно ли спрятать с noindex & nofollow?
К тому же, Google практически не реагирует на подобные атрибуты: для него решающую роль играет robots.txt, а не ручные указания в коде.
Удалить через WP No External Links
Русифицированный плагин, создающий страницу-прокладку при переходе на внешний URL, позволяет так закрывать урлы. Таким образом он подменяет внешнюю ссылку на внутреннюю, что ведет к уменьшению теряемого веса и улучшению поведенческих факторов.
Чтобы его использовать и закрыть от индексации URL, необходимо поменять стандартную конфигурацию. Для этого:
В первом разделе оставить активными только три самых первых чекбокса – как на скрине. Дальше ничего не трогаем и переходим к “Шифрование ссылок”: там включаем кодировку base64.

Далее включаем яваскриптовый редирект (следующий отдел), выставляем время, равное 3 секундам и меняем текст на предложение перейти обратно на главную.
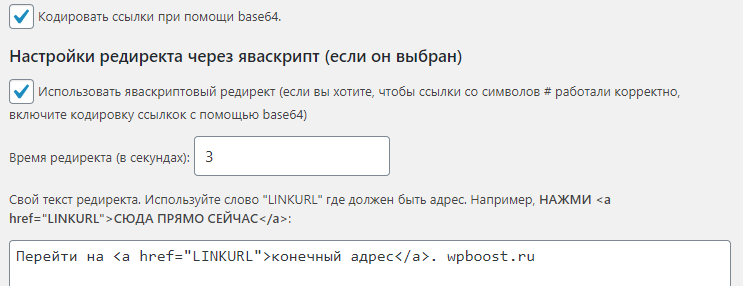
Сохраняем изменения.
Замаскировать, используя Clearfy PRO
Русифицированный модуль технического SEO. Принцип его работы в отношении маскировки ссылок отличается: он не ставит никакого редиректа, а оборачивает их в JavaScript фрагмент, визуально, при помощи стилей, отличая их, однако на коде они всего лишь исполняемый по команде (клику) скрипт.
Clearfy -15%
Защита при помощи скрипта TAC
Можно стараться бесконечно спрятать авторские ссылки от индексации, однако при наличии закодированных линков в теме или вредоносных шаблонов, будут появляться более критичные, сильно вредящие ресурсу. Удалить такие при установке новой темы поможет TAC: он выявляет вредные адреса, зачастую содержащиеся в неофициальных темах (не из официального каталога WordPress), и удаляет их.
Мне нравитсяНе нравится
Запрет индексации, robots и htaccess. Закрыть от индексации страницы, папки, поддомены, ссылки.
Читайте так же — запрет индексации:
- Поддомена
- Ссылки
- Страницы
- Части контента страницы
 Запрет индексации требуется в том случае, когда вы не хотите, чтобы ваша информация попала в результаты поисковой выдачи. Так же это бывает необходимо, если вы не хотите, чтобы страницы не передавали свой вес другим, на которые стоят ссылки. На самом деле, задачи запрета индексации страниц и ссылок имеют одинаковые верные решения. То есть, если вы хотите скрыть от роботов страницу, недостаточно скрыть ссылку на нее. Тем более недостаточно запретить индексацию в robots.txt, ведь роботы прекрасно проходят на такие страницы по внешним ссылкам с других сайтов.
Запрет индексации требуется в том случае, когда вы не хотите, чтобы ваша информация попала в результаты поисковой выдачи. Так же это бывает необходимо, если вы не хотите, чтобы страницы не передавали свой вес другим, на которые стоят ссылки. На самом деле, задачи запрета индексации страниц и ссылок имеют одинаковые верные решения. То есть, если вы хотите скрыть от роботов страницу, недостаточно скрыть ссылку на нее. Тем более недостаточно запретить индексацию в robots.txt, ведь роботы прекрасно проходят на такие страницы по внешним ссылкам с других сайтов.
А потом, к тому же, берут из общедоступных источников(например dmoz.org) тайтл, который может быть уже неактуален. Таким образом, страница попадает в выдачу. Атрибут rel = nofollow всего лишь не дает ссылке передать вес странице акцептору, но отнимает у донора. А, в случае внутренней перелинковки, может серьезно нарушить процесс распределения весов. В итоге, единственным эффективным методом является запрет индексации в htaccess, который описан ниже. Подобные рассуждения ведет Мэтт Каттс (Matt Cutts) руководитель Google’s Webspam team в небольшом видео-уроке.>>>
Если доступа к robots.txt нет, стоит использовать метатег noindex. Именно метатег.
< meta name=’robots’ content=’noindex’ />
Тег noindex иногда используют с целью оптимизации сниппетов, но в остальном пользы от него не замечено. Взамен объяснений дам ссылку на статью —
Запрет индексации ссылки в htaccess:
Для этого можно создать скриптик:
<?
Header (‘Location:’.$_GET.’ ‘); exit();
?>
назвать его redirect.php и сохранить в папке http://mysite.ru/outlink/
Скрипту передавать параметр url:
http://mysite.ru/outlink/redirect.php?url=http://www.site.ru
Далее
Первый вариант – доступ к http://mysite.ru/outlink/ запретить роботам, как описано выше.
В htaccess задать страницу 403 ошибки или возвращать ее на главную:
ErrorDocument 403 http://mysite.ru/
Таким образом все будут переходить по адресу, заданному параметром url, но поисковые роботы будут попадать на главную, предварительно получив ответ:
302 Moved Permanently, Location: http://mysite.ru/;
Второй вариант – это в /outlink/.htaccess :
RewriteEngine on
RewriteCond %{HTTP_USER_AGENT} ^Google.*
RewriteCond %{HTTP_USER_AGENT} ^.*yandex.*
RewriteRule ^(.*)$ http://mysite.ru/?
В этом случае робот получит ответ:
301 Moved Permanently, Location: http://mysite.ru/;
Третий вариант – в http://mysite.ru/outlink/.htaccess :
(кстати рекомендованный Мэттом Каттсом 😉
AuthType Basic
AuthName ‘BBEguTE 1 u 1′ //сообщение только на латинице
AuthUserFile /’путь от корня сервера’/outlink/.htpasswd
Require valid-user
< Files .htpasswd> //лишний пробел после <
deny from all
< /Files> //лишний пробел после <
В /outlink/ разместить htpasswd содержащий имя пользователя и пароль, например единичками:
1:$apr1$xbXrU/..$dpywDS4kwdIovYs5oPImK0
Путь от корня сервера можете узнать, создав скриптик в папке http://mysite.ru/outlink/path.php следующего содержания:
< ?php //тут стоит лишний пробел между < и ?
phpinfo();
?>
Из переменной DOCUMENT_ROOT => /home/www/users/AM/public_html берем путь и ставим вместо ‘путь от корня сервера’.
Проверить работу этих и других методов запрета индексации можно зайдя на сайт с помощью этой формочки посмотреть как поисковый робот.
Неплохая справка по htaccess — http://www.ph4.ru/spravka_htaccess.ph4
VN:F
пожалуйста, оцените страницу, я старался 🙂
пожалуйста подождите…
Rating: 4.6/5 (47 votes cast)
Зачем необходимо закрывать внешние ссылки от индексации
Опытные вебмастера всегда закрывают внешние или ненужные ссылки на своих блогах. Для чего они так делают? Все дело как раз заключается в том, что любая веб страница имеет определенный вес.
Однако, вес страницы перераспределяется при простановке в ней различных ссылок.
Если на первой странице проставлена анкор ссылка на вторую страницу, то часть веса отдается второй странице
И не важно, внешняя это ссылка или внутренняя
Чтобы было понятнее, поясню на примере. Предположим, что первая страница имеет вес равный 10 баллов. После постановки ссылки на вторую страницу, вес каждой страницы будет равняться по 5 баллов.
Тем самым получается, что чем больше ссылок на определенную страницу, тем больше ее вес.
Поэтому наша задача в основном заключается в том, чтобы не отдавать вес со своих страниц другим блогам, а удерживать внутри своего.
Мой пример с баллами является приближённым. На самом деле, вес самой ссылки зависит от многих факторов, в числе которых релевантность, ключевые слова, удаленность от начала страницы и других.
Если Вы хотите быстро продвинуть какую-либо страницу, то необходимо будет ссылаться на нее с других страниц. В этом как раз и заключается один из элементов грамотной внутренней перелинковки страниц блога.
Учесть также нужно и то, что чем больше ссылок Вы поставите на странице, тем меньше веса останется на этой странице!
Кроме того, большое количество ссылок плохо тем, что страницы, на которые ссылается эта, также получат ничтожные веса.
Если Вы хотите в будущем зарабатывать на продаже постовых, то учтите, что заказчики, как правило, предъявляют особые требования к страницам размещения.
Одним из этих требований является ограниченное количество внешних ссылок на странице с постовым. Обычно это не более 3-5 внешних ссылок.
Надеюсь, я убедил Вас в том, что закрыть внешние ссылки от индексации нужно в срочном порядке. Приступим к выполнению задуманного.
Запрещаем индексацию страницы
Запрет индексации одной единственной страницы отличается от запрета всего сайта только наличием дополнительной инструкции и URL адреса. Причем исключить из индекса можно не только конкретный адрес, но и маску. Однако возможность эта имеется только при работе с файлом robots.txt.
При помощи robots.txt
Для запрета конкретной страницы (спектра страниц по маске) используется инструкция «Disallow:». Синтаксис крайне простой:
Disallow: /wp-admin (исключаем всю папку wp-admin) Disallow: /wp-content/plugins (исключаем папку plugins, которая находится в wp-content) Disallow: /img/images.jpg (исключаем изображение images.jpg, которое находится в папке img) Disallow: /dogovor.pdf (исключаем файл /dogovor.pdf) Disallow: */trackback (исключаем папку trackback в любой папке первого уровня) Disallow: /*my (исключаем любую папку заканчивающуюся на my)
Все достаточно просто, не правда ли? Но это позволяет избавиться от множества проблем во время продвижения сайта. Актуализируйте robots.txt каждый месяц в зависимости от апдейтов Яндекса и Гугла.
При помощи тэгов
Исключение возможно и при помощи тэга <meta name=»robots» content=»noindex»>. Для этого необходимо просто вписать его в код конкретной страницы, которую Вы хотите закрыть от поисковиков.
Данный тэг размещается в <head> сайта, наряду с другими meta тэгами.
Стоит отметить, что значение параметра «content» может быть не только «noindex». Рассмотрим все возможные варианты.
| noindex | Самый распространенный параметр. Запрещает индексацию. |
| index | Обратный предыдущему параметр. Разрешает индексацию. Обычно не применяется, так как поисковая система по умолчанию индексирует все. |
| follow | Разрешает следовать по ссылкам, которые расположены на странице. Так же редко применяется, так как и без данного тэга будет переходить по ссылкам. |
| nofollow | Запрещает переходить по ссылкам. |
Маски к директивам файла robots.txt для wordpress
Теперь немного как создавать маски:
- Disallow: /wp-register.php — Запрещает индексировать файл wp-register.php, расположенный в корневой папке.
- Disallow: /wp-admin — запрещает индексировать содержимое папки wp-admin, расположенной в корневой папке.
- Disallow: /trackback — запрещает индексировать уведомления.
- Disallow: /wp-content/plugins — запрещает индексировать содержимое папки plugins, расположенной в подпапке (папке второго уровня) wp-content.
- Disallow: /feed — запрещает индексировать канал feed т.е. закрывает RSS канал сайта.
- * — означает любая последовательность символов, поэтому может заменять как один символ, так и часть названия или полностью название файла или папки. Отсутствие конкретного названия в конце равносильно написанию *.
- Disallow: */*comments — запрещает индексировать содержимое папок и файлов в названии которых присутствует comments и расположенных в любых папках. В данном случае запрещает индексировать комментарии.
- Disallow: *?s= — запрещает индексировать страницы поиска
Приведенные выше строки вполне можно использовать в качестве рабочего файла robots.txt для wordpress. Только в 36, 38 строках необходимо вписать адрес вашего сайта и ОБЯЗАТЕЛЬНО УБРАТЬ номера строк. И у вас получится рабочий файл robots.txt для wordpress, адаптированный под любую поисковую систему.
Единственная особенность — размер рабочего файла robots.txt для сайта wordpress не должен превышать 32 кБ дискового пространства.
Ещё одна маленькая рекомендация.
Нестандартные Директивы
Google не понимаю эту директиву. Указывает роботу, что URL страницы содержит GET-параметры, которые не нужно учитывать при индексировании. Такими параметрами могут быть идентификаторы сессий, пользователей, метки UTM, т.е. все то что не влияет на содержимое страницы.
Заполняйте директиву Clean-param максимально полно и поддерживайте ее актуальность. Новый параметр, не влияющий на контент страницы, может привести к появлению страниц-дублей, которые не должны попасть в поиск. Из-за большого количества таких страниц робот медленнее обходит сайт. А значит, важные изменения дольше не попадут в результаты поиска. Робот Яндекса, используя эту директиву, не будет многократно перезагружать дублирующуюся информацию. Таким образом, увеличится эффективность обхода вашего сайта, снизится нагрузка на сервер.
Например, на сайте есть страницы, в которых параметр используется только для того, чтобы отследить с какого ресурса был сделан запрос и не меняет содержимое, по всем трем адресам будет показана одна и та же страница:
example.com/dir/bookname?ref=site_1 example.com/dir/bookname?ref=site_2 example.com/dir/bookname?ref=site_3
Если указать директиву следующим образом:
User-agent: Yandex Clean-param: ref /dir/bookname
то робот Яндекса сведет все адреса страницы к одному:
example.com/dir/bookname
Пример очистки нескольких параметров сразу: и :
Clean-param: ref&sort /dir/bookname
Clean-Param является межсекционной, поэтому может быть указана в любом месте файла robots.txt. Если директив указано несколько, все они будут учтены роботом.
User-agent: Yandex Disallow: /wp-admin Disallow: /wp-includes Crawl-delay: 1.5 User-agent: * Disallow: /wp-admin Disallow: /wp-includes Allow: /wp-*.gif
Google не понимает эту директиву. Таймаут его роботам можно указать в панели вебмастера.
Яндекс перестал учитывать Crawl-delay
Проанализировав письма за последние два года в нашу поддержку по вопросам индексирования, мы выяснили, что одной из основных причин медленного скачивания документов является неправильно настроенная директива Crawl-delay в robots.txt Для того чтобы владельцам сайтов не пришлось больше об этом беспокоиться и чтобы все действительно нужные страницы сайтов появлялись и обновлялись в поиске быстро, мы решили отказаться от учёта директивы Crawl-delay.
Для чего была нужна директива Crawl-delay
Когда робот сканирует сайт как сумасшедший и это создает излишнюю нагрузку на сервер. Робота можно попросить «поубавить обороты». Для этого можно использовать директиву Crawl-delay. Она указывает время в секундах, которое робот должен простаивать (ждать) для сканирования каждой следующей страницы сайта.
Google Директиву Host никогда не поддерживал, а Яндекс полностью отказывается от неё. Host можно смело удалять из robots.txt. Вместо Host нужно настраивать 301 редирект со всех зеркал сайта на главный сайт (главное зеркало).
Блокировка индексации сайта robots.txt
К данному ресурсу обращаются чаще всего на
стадии разработки сайта, когда вмешательство поисковых систем крайне
нежелательно. Далее представлена подробная инструкция, как блокировать
индексацию сайта при помощи robots.txt:
- в корне сайта необходимо создать текстовый файл robots.txt и прописать в нем строки, позволяющие скрыть все ссылки от любого поискового бота (защита предназначена для всех видов браузеров);
- форма записи для проведения операции скрытия информации: «Users-agens:*\ Disallow»;
- в последнем разделе после двоеточия вы указываете тип скрываемой информации: папка, отдельный файл в Яндекс, картинку или второй домен.
Для каждой поисковой системы задано свое имя,
к которому вы обращаетесь, вводя его наименование в разделе Disallow.
Зачем закрывать ссылки от индексации
Одну причину скрытия внешних ссылок мы уже
рассмотрели ранее. Однако, на практике можно столкнуться и еще с одной задачей
защиты контента. Наличие ссылок на внешние ресурсы значительно увеличивает вес html-страницы за счет дополнительного контента стороннего сайта, а это означает
низкую скорость загрузки и медленную работу веб ресурса. Принцип защиты от индексации заключается в сокрытии
истинного веса html-страницы различными путями (запрет перехода по
ссылкам, отведение информации на отдельные файлы).
Директивы метатега robots и X-Robots-Tag
Два метода управления индексацией отличаются синтаксисом и способом внедрения. Метатег robots размещают в html-коде страницы и заполняют его атрибуты — параметры с именем робота (name) и командами для него (content). Тег x-robots добавляют в файл конфигурации и атрибуты в этом случае не используют.
Запрет индексации контента роботом Google с помощью метатега robots выглядит так:
Запрет индексации контента роботом Google с помощью тега x-robots имеет такой вид:
При этом у метатегов robots и X-Robots-Tag общие директивы — команды для обращения к роботам поисковиков. Рассмотрим список актуальных директив для разных поисковых систем и их функции.
Функции директив и их поддержка разными поисковиками
| НАЗВАНИЕ | ФУНКЦИЯ ДИРЕКТИВЫ | YANDEX | BING | YAHOO! | |
| index/noindex | Разрешение/запрет индексации текста. Чаще всего используют noindex, чтобы скрыть страницу из результатов выдачи. | + | + | + | + |
| follow/nofollow | Разрешение/запрет перехода роботом по ссылкам на странице. | + | + | + | + |
| archive/noarchive | Разрешение/запрет показа в поиске кэшированной версии страницы. | + | + | + | + |
| all/none |
Сочетает в себе две директивы, отвечающие за индексацию текста и ссылок. all — эквивалент index, follow (используется по умолчанию). none — эквивалент noindex, nofollow. |
+ | + | – | + |
| nosnippet | Запрет отображения сниппета (фрагмента текста) или видео в результатах поиска. | + | – | + | – |
| max-snippet | Ограничивает размер сниппета. Формат директивы: max-snippet:, где number — количество символов. | + | – | – | + |
| max-image-preview | Задает максимальный размер изображений для показа страницы в поиске. Формат директивы: max-image-preview:, где setting может иметь значение none, standard или large. | + | – | – | + |
| max-video-preview | Ограничение длительности видео, которые отображаются в поиске. Значение указывают в секундах. Также можно задавать статическое изображение (0) или снимать ограничения (-1). Формат директивы: max-video-preview: | + | – | – | + |
| notranslate | Запрет перевода страницы в выдаче. | + | – | – | – |
| noimageindex | Запрет индексации изображений страницы. | + | – | – | – |
| unavailable_after | Запрет показа страницы в поиске после определенной даты. Директиву указывают в формате unavailable_after: [дата/время]. | + | – | – | – |
| noyaca | Запрет применения описания из Яндекс.Каталога в сниппете. | – | + | – | – |
В таблице приведены как запрещающие, так и разрешающие команды. Однако индексация открытого» содержимого сайта происходит по умолчанию и директивы вроде index и follow можно не прописывать.
Сравнение директив Google и Яндекс
Как видно в таблице выше, у Google и Яндекса есть как общие, так и уникальные команды. В Google это nosnippet, max-snippet, max-image-preview, max-video-preview, notranslate, noimageindex, unavailable_after. В Яндексе — noyaca.
Теперь рассмотрим, какие из директив можно использовать в метатеге robots, а какие — в теге X-Robots, чтобы их понимали боты Яндекса и Google.
| Директива | Метатег robots Google | Заголовок X-Robots-Tag Google | Метатег robots Yandex | Заголовок X-Robots-Tag Yandex |
| noindex | + | + | + | + |
| nofollow | + | + | + | + |
| noarchive | + | + | + | + |
| index/ follow/ archive | + | + | + | – |
| none | + | + | + | + |
| all | + | + | + | – |
| nosnippet | + | + | – | – |
| max-snippet | + | + | – | – |
| max-snippet | + | + | – | – |
| max-image-preview | + | + | – | – |
| max-video-preview | + | + | – | – |
| notranslate | + | + | – | – |
| noimageindex | + | + | – | – |
| unavailable_after | + | + | – | – |
| noyaca | – | – | + | – |
