Полное руководство по robots.txt и метатегу noindex
Содержание:
- Значения noindex, nofollow в мета тегах
- Директивы метатега robots и X-Robots-Tag
- Правила для конкретных поисковых систем
- How do search engines interpret conflicting directives?
- What is a Noindex Meta Tag?
- Как применять метатег Noindex?
- Обработка комбинированных директив индексирования и показа контента
- Как общаться с технической поддержкой о мета-тегах
- Understanding Robots Meta Tag Attributes and Directives
- NOODP — запрет использования DMOZ поисковиками
- SEO best practices with robots meta directives
- Функция wp_robots()
- Использование метатега robots для блокирования доступа к сайту
- Что делать если вы обнаружили на статье мета-тег
- Robots meta etiketini kullanma
- Как использовать метатег robots
- Google про мета-тег robots
- Что такое тег Noindex
- Директива max-image-preview:large
- Метатеги для поисковых систем
- Как использовать noindex и nofollow
- Use the newly created template to produce the final HTML documentation
- Основные мета теги
- Заключение
Значения noindex, nofollow в мета тегах
Заголовочные метатеги <head> содержат важную информацию для поисковых систем о странице сайта. Рассмотрим мета тег robots:
В данном примере значение мета тега robots содержит значение nofollow и noindex, что означает запрет на индексирование страницы, а также запрет на переход по ссылкам на ней. Эти параметры могут быть записаны как вместе, так и раздельно. Например, один параметр может быть включен, другой выключен. По умолчанию оба они включены.
Например, разрешим индексацию, но запретим переходить поисковому роботу по ссылкам на конкретной странице
Отмечу тот факт, что для Яндекса и Google этот мета тег оказывает решающее значение при обходе сайта. Например, если указать в файле robots.txt страницы, которые не требуется индексировать, то поисковая система может проигнорировать их. В случае мета тегов это будет являться уже жестким требованием.
Данный подход позволяет эффективно и точечно бороться с дублями страниц на сайте.
Примечание
Чтобы указать действие для конкретного поисковика можно вместо name=»robots» написать имя поисковой машины. Например, для Яндекса:
Для гугл надо написать: name=»google».
Директивы метатега robots и X-Robots-Tag
Два метода управления индексацией отличаются синтаксисом и способом внедрения. Метатег robots размещают в html-коде страницы и заполняют его атрибуты — параметры с именем робота (name) и командами для него (content). Тег x-robots добавляют в файл конфигурации и атрибуты в этом случае не используют.
Запрет индексации контента роботом Google с помощью метатега robots выглядит так:
Запрет индексации контента роботом Google с помощью тега x-robots имеет такой вид:
При этом у метатегов robots и X-Robots-Tag общие директивы — команды для обращения к роботам поисковиков. Рассмотрим список актуальных директив для разных поисковых систем и их функции.
Функции директив и их поддержка разными поисковиками
| НАЗВАНИЕ | ФУНКЦИЯ ДИРЕКТИВЫ | YANDEX | BING | YAHOO! | |
| index/noindex | Разрешение/запрет индексации текста. Чаще всего используют noindex, чтобы скрыть страницу из результатов выдачи. | + | + | + | + |
| follow/nofollow | Разрешение/запрет перехода роботом по ссылкам на странице. | + | + | + | + |
| archive/noarchive | Разрешение/запрет показа в поиске кэшированной версии страницы. | + | + | + | + |
| all/none |
Сочетает в себе две директивы, отвечающие за индексацию текста и ссылок. all — эквивалент index, follow (используется по умолчанию). none — эквивалент noindex, nofollow. |
+ | + | – | + |
| nosnippet | Запрет отображения сниппета (фрагмента текста) или видео в результатах поиска. | + | – | + | – |
| max-snippet | Ограничивает размер сниппета. Формат директивы: max-snippet:, где number — количество символов. | + | – | – | + |
| max-image-preview | Задает максимальный размер изображений для показа страницы в поиске. Формат директивы: max-image-preview:, где setting может иметь значение none, standard или large. | + | – | – | + |
| max-video-preview | Ограничение длительности видео, которые отображаются в поиске. Значение указывают в секундах. Также можно задавать статическое изображение (0) или снимать ограничения (-1). Формат директивы: max-video-preview: | + | – | – | + |
| notranslate | Запрет перевода страницы в выдаче. | + | – | – | – |
| noimageindex | Запрет индексации изображений страницы. | + | – | – | – |
| unavailable_after | Запрет показа страницы в поиске после определенной даты. Директиву указывают в формате unavailable_after: [дата/время]. | + | – | – | – |
| noyaca | Запрет применения описания из Яндекс.Каталога в сниппете. | – | + | – | – |
В таблице приведены как запрещающие, так и разрешающие команды. Однако индексация открытого» содержимого сайта происходит по умолчанию и директивы вроде index и follow можно не прописывать.
Сравнение директив Google и Яндекс
Как видно в таблице выше, у Google и Яндекса есть как общие, так и уникальные команды. В Google это nosnippet, max-snippet, max-image-preview, max-video-preview, notranslate, noimageindex, unavailable_after. В Яндексе — noyaca.
Теперь рассмотрим, какие из директив можно использовать в метатеге robots, а какие — в теге X-Robots, чтобы их понимали боты Яндекса и Google.
| Директива | Метатег robots Google | Заголовок X-Robots-Tag Google | Метатег robots Yandex | Заголовок X-Robots-Tag Yandex |
| noindex | + | + | + | + |
| nofollow | + | + | + | + |
| noarchive | + | + | + | + |
| index/ follow/ archive | + | + | + | – |
| none | + | + | + | + |
| all | + | + | + | – |
| nosnippet | + | + | – | – |
| max-snippet | + | + | – | – |
| max-snippet | + | + | – | – |
| max-image-preview | + | + | – | – |
| max-video-preview | + | + | – | – |
| notranslate | + | + | – | – |
| noimageindex | + | + | – | – |
| unavailable_after | + | + | – | – |
| noyaca | – | – | + | – |
Правила для конкретных поисковых систем
Иногда вам может потребоваться предоставить конкретные инструкции для конкретной поисковой системы, исключая других роботов. Или вы можете составить совершенно разные инструкции для разных поисковых систем.
В этих случаях вы можете изменить значение content атрибута для конкретной поисковой системы (например, googlebot для Google или yandex для Яндекс).
Примечание. Учитывая, что поисковые системы будут просто игнорировать инструкции, которые они не поддерживают или не понимают, очень редко нужно использовать несколько тегов мета-роботов для установки инструкций для определенных сканеров.
How do search engines interpret conflicting directives?
As you can imagine, when you start stacking directives, it’s easy to mess up. If a scenario presents itself where there are conflicting directives, Google will default to the most restrictive one.
Take for example the following directives:
Verdict: Google will err on the side of caution and not index the page.
But, the way conflicting directives are interpreted can differ among search engines. Let’s take another example:
Google will not index this page, but Yandex will do the exact opposite and index it.
So keep this in mind, and make sure that your robots directives work right for the search engines that are important to you.
What is a Noindex Meta Tag?
A ‘noindex’ tag tells search engines not to include the page in search results.
The most common method of noindexing a page is to add a tag in the head section of the HTML, or in the response headers. To allow search engines to see this information, the page must not already be blocked (disallowed) in a robots.txt file. If the page is blocked via your robots.txt file, Google will never see the noindex tag and the page might still appear in search results.
To tell search engines not to index your page, simply add the following to the </head> section:
<meta name=”robots” content=”noindex, follow”>
The second part of the content tag here indicates that all the links on this page should be followed, which we’ll discuss below.
Alternatively, the noindex tag can be used in an X-Robots-Tag in the HTTP header:
X-Robots-Tag: noindex
For more information see Google Developers’ post on
Как применять метатег Noindex?
Существует три способа добавления Noindex на страницы:
Метатег «robots»
Разместите приведенный ниже код в раздел <head> страницы:
<meta name=”robots” content=”noindex”>
Он сообщает всем типам поисковых роботов об условиях индексации страницы. Если нужно запретить индексацию страницы только для определенного робота, поместите его название в значение атрибута name.
Чтобы запретить индексацию страницы для Googlebot:
<meta name=”googlebot” content=”noindex”>
Чтобы запретить индексацию страницы для Bingbot:
<meta name=”bingbot” content=”noindex”>
Также можно разрешить или запретить роботам переход по ссылкам, размещенным на странице.
Чтобы разрешить переход по ссылкам на странице:
<meta name=”robots” content=”noindex,follow”>
Чтобы запретить поисковым роботам сканировать ссылки на странице:
<meta name=”robots” content=”noindex,nofollow”>
X-Robots-Tag
x-robots-tag позволяет управлять индексацией страницы через HTTP-заголовок. Этот тег также указывает поисковым системам не отображать определенные типы файлов в результатах поиска. Например, изображения и другие медиа-файлы.
Для этого у вас должен быть доступ к файлу .htaccess. Директивы в метатеге «robots» также применимы к x-robots-tag.
Блокировка индексации через YoastSEO
Плагин YoastSEO в WordPress автоматически генерирует приведенный выше код. Для этого на странице записи перейдите в интерфейсе YoastSEO в настройки публикации, щелкнув по значку шестеренки. Затем в опции «Разрешить поисковым системам показывать эту публикацию в результатах поиска?» выберите «Нет».
Также можно задать тег noindex для страниц категорий. Для этого зайдите в плагин Yoast, в «Вид поиска». Если в разделе «Показать категории в результатах поиска» выбрать «Нет», тег noindex будет размещен на всех страницах категорий.
Обработка комбинированных директив индексирования и показа контента
В одном метатеге robots можно создать инструкцию из нескольких директив, перечисленных через запятую. Ниже приведен пример метатега robots, который запрещает поисковым роботам индексировать страницу и сканировать ссылки на ней:
<meta name="robots" content="noindex, nofollow">
В следующем примере фрагмент текста ограничивается 20 символами, но разрешен показ крупных изображений:
<meta name="robots" content="max-snippet:20, max-image-preview:large">
Если перечислены различные директивы для нескольких поисковых роботов, поисковая система будет суммировать запреты. Пример:
<meta name="robots" content="nofollow"> <meta name="googlebot" content="noindex">
Обнаружив эти метатеги, робот Googlebot будет действовать так же, как при наличии на странице директив .
Как общаться с технической поддержкой о мета-тегах
Чтобы не тратить зря время, не упоминайте расширение ПРОДЗЕН и термины «красная рожица», «грустная мордочка», «значок робота» и т.п.
Сотрудники ТП не могут комментировать то, как работает расширение, не знают и не должны знать, что оно показывает и т.п. Поэтому упомянув расширение, вы гарантированно получите отказ его обсуждать, иногда даже с советом его не использовать.
Не ссылайтесь только лишь на наличие самого мета-тега.
Если статья новая и не получает показов — так и напишите.
Если публикация опубликована больше суток назад, успешно набирала просмотры, а потом внезапно получила мета-тег, посмотрите график конкретной статьи в метрике — там будет видно, что в какой-то момент резко прекратились просмотры. Приведите скриншот этого графика.
Т.е. основным в вашем письме должно быть то, что возникли проблемы с публикацией. Про мета-тег можно вообще не упоминать, или упоминать в качестве дополнения.
К сожалению, это может не помочь. Если менеджеры, помогающие участникам программы Нирвана, ещё готовы разбираться с проблемами, то сотрудники обычной поддержки очень часто начинают писать стандартные отписки, не сильно вникая в их смысл.
Иногда можно подождать, пока ваше обращение будет отмечено как завершённое и написать ещё раз — если повезёт, вам ответит сотрудник, настроенный как-то помочь вам.
Так же можно обратиться за помощью в официальные группы Дзена в ВК или в телеграме.
Если ничего добиться не удастся, то остаётся только грустить вместе с грустным роботом.
Understanding Robots Meta Tag Attributes and Directives
Using robots meta tags is quite simple once you understand how to set the two attributes: name and content. Both of these attributes are required, so you must set a value for each.
Let’s take a look at these attributes in more detail.
Name
The name attribute controls that crawlers and bots (user-agents, also referred to as UA) should follow the instructions contained within the robots meta tag.
To instruct all crawlers to follow the instructions, use:
name=»robots»
In most scenarios, you’ll want to use this as default, but you can use as many different meta robots tags as needed to specify instructions to different crawlers.
When instructing different crawlers, it’s simply a case of using multiple tags:
There are hundreds of different user-agents. The most common ones are:
- : Googlebot (you can see a full list of Google crawlers here)
- Bing: Bingbot (you can see a full list of Bing crawlers here)
- DuckDuckGo: DuckDuckBot
- Baidu: Baiduspider
- Yandex: YandexBot
Content
The content attribute is what you use to give the instructions to the specified user-agent.
It’s important to know that if you do not specify a meta robots tag on a web page, the default is to index the page and to follow all of the links (unless they have a rel=»nofollow» attribute specified inline).
The different directives that you can use includes:
- index (include the page in the index) [Note: you do not need to include this if noindex is not specified, it is assumed as index)
- noindex (do not include the page in the index or show on the SERPs)
- follow (follow the links on the page to discover other pages)
- nofollow (do not follow the links on the page)
- none (a shortcut to specify noindex, nofollow)
- all (a shortcut to specify index, follow)
- noimageindex (do not index the images on the page)
- noarchive (do not show a cached version of the page on the SERPs)
- nocache (this is the same as noarchive, but only for MSN)
- nositelinkssearchbox (do not show a search box for your site on the SERPs)
- nopagereadaloud (do not allow voice services to read your page aloud)
- notranslate (do not show translations of the page on the SERPs)
- unavailable_after (specify a time after which the page should not be indexed)
You can see a full list of the directives that Google supports here and the ones that Bing supports here.
NOODP — запрет использования DMOZ поисковиками
Для создания фрагментов часто применяется такой источник, как Open Directory Project. Чтобы поисковики не применяли его, для описания содержимого сайта, добавляется тег:
<meta name=»robots» content=»noodp»>

Или такой:
<meta name=»имя_робота» content=»noodp»>
Параметры атрибута content можно объединять, таким образом:
<meta name=»robots» content=»noodp, nofollow»>
Запреты поисковым системами
Каким образом можно дать понять поисковому роботу, что какую-то часть страницы не нужно проверять или по какой-то одной ссылке не стоит переходить?
Разные поисковые системы предлагают сделать это по разному. Яндекс советует вставлять такой текст между тегами <!—noindex—><!—/noindex—>, тогда как Google предлагает добавлять к ссылкам атрибут rel=»nofollow».
SEO best practices with robots meta directives
-
All meta directives (robots or otherwise) are discovered when a URL is crawled. This means that if a robots.txt file disallows the URL from crawling, any meta directive on a page (either in the HTML or the HTTP header) will not be seen and will, effectively, be ignored.
-
In most cases, using a meta robots tag with parameters «noindex, follow» should be employed as a way to to restrict crawling or indexation instead of using robots.txt file disallows.
-
It is important to note that malicious crawlers are likely to completely ignore meta directives and as such, this protocol does not make a good security mechanism. If you have private information that you don’t want to make publicly searchable, choose a more secure approach, such as password protection, to keep visitors from viewing confidential pages.
-
You do not need to use both meta robots and the x-robots-tag on the same page – doing so would be redundant.
Функция wp_robots()
В WP 5.7 появилась функция wp_robots(), которая выводит метатег .
функция автоматически вызывается ядром WordPress на всех страницах фронта, происходит это на событии wp_head. Таким образом, мета-тег будет выводится на всех страницах фронта автоматически, если указана хоть одна директива robots.
Функция «цепляется» на хук в файле /wp-includes/default-filters.php:
add_action( 'wp_head', 'wp_robots', 1 );
Плагин или тема не должны вызывать wp_robots() отдельно! Это может быть нужно, в особых случаях, например, когда шаблон не может использовать wp_head(). В этом случае функцию нужно подключить к своему фильтру или вызвать напрямую в коде. Пример:
// подключение к фильтру add_action( 'my_custom_template_head', 'wp_robots' ); // прямой вызов <?php wp_robots() ?>
Использование метатега robots для блокирования доступа к сайту
Данный метод запрета индексации страниц сайта встречается гораздо реже в повседневной жизни. Как следствие происходит это из-за что разработчики большинства CMS просто не обращают на это внимания/забывают/забивают. И тогда ответственность за поведение роботов на сайте полностью ложится на плечи вебмастеров, которые в свою очередь обходятся простейшим вариантом – robots.txt.
Но продвинутые вебмастера, которые в теме особенностей индексации сайтов и поведения роботов, используют метатег robots.
И снова небольшая выдержка из руководства от Google:
Внушает оптимизм, не правда ли? И еще:
Следовательно, все страницы, которые мы хотим запретить к индексации, а так же исключить их из индекса, если они уже проиндексированы (насколько я понял, это касается и доп. индекса Гугла), необходимо на всех таких страницах поместить метатег
Что еще более важно, эти самые страницы не должны быть закрыты через robots.txt!
Немного побуду кэпом и расскажу, какие еще значения (content=»…») может принимать мататег robots:
- noindex – запрещает индексацию страницы
- nofollow – запрещает роботу следовать по ссылкам на странице
- index, follow – разрешает роботу индексацию страницы и переход по ссылкам на этой странице
- all – аналогично предыдущему пункту. По большому счету, бесполезная директива, эквивалентна отсутствию самого метатега robots
- none – запрет на индексацию и следование по ссылкам, эквивалентно сочетанию noindex,nofollow
- noarchive – запрет поисковику выводить ссылку на кеш страницы (для Яндекса это «копия», для Google это «сохраненная копия»)
Так как в справке Яндекса нижеследующие параметры не описаны, то они, скорее всего, там и не сработают. Так что эти параметры только для Google:
- noimageindex – запрет на индексацию изображений на странице
- nosnippet – запрет на вывод сниппета в результатах поиска (при этом так же удаляется и сохраненная копия!)
- noodp – запрет для Google на вывод в качестве сниппета описания из каталога DMOZ
Вроде все, осталось только сказать, что количество пробелов, положение запятой и регистр внутри content=»…» здесь не играет никакой роли, но все же для красоты лучше писать как положено (с маленькой буквы, без пробелов и разделяя атрибуты запятой).
Короче говоря, чтобы полностью запретить индексацию ненужных страниц и появление их в поиске необходимо на всех этих страницах разместить метатег .
Так что если вам известны все страницы (наборы страниц, категории и т.д.), которые не должны попасть в индекс и есть доступ к редактированию их содержания (конкретно, содержания внутри тега ), то можно обойтись без запрещающих директив в файле robots.txt, но разместив на страницах метатег robots. Данный вариант, как вы понимаете, является эффективным и предпочтительным.
Рекомендую к прочтению:
- Мануал Google «Блокировка индексирования при помощи атрибута noindex»
- Мануал Яндекса «Как удалить страницы из поиска»
Итак, у нас остался последний нераскрытый вопрос, и он о внутренних ссылках.
Что делать если вы обнаружили на статье мета-тег
Ещё раз подчеркну, что наличие мета-тега — норма на новых, не прошедших модерацию каналов. Проверка (или, как говорят, «выход на алл») может занять какое-то время. Иногда каналы успевают достигнуть порога монетизации, в этом случае монетизация не будет подключена до прохождения проверки.
Если канал не новый, то возможны разные ситуации:
- Иногда мета-тег снимается простым переопубликованием (т.е. нужно отредактировать и снова её опубликовать, ничего не меняя).
- Если это не помогло, то высока вероятность того, что статья ограничена (возможно ошибочно). В этом случае поможет только обращение в службу поддержки Дзена, правда добиться этого не всегда бывает просто.
Robots meta etiketini kullanma
Robots meta etiketi, tek bir sayfanın dizine nasıl eklenmesi ve Google Arama sonuçlarında kullanıcılara nasıl sunulması gerektiğini kontrol etmek için ayrıntılı, sayfaya özel bir yaklaşım kullanabilmenizi sağlar. Robots meta etiketini belirli bir sayfanın bölümüne şu şekilde yerleştirin:
<!DOCTYPE html> <html><head> <meta name="robots" content="noindex" /> (…) </head> <body>(…)</body> </html>
Yukarıdaki örnekte yer alan robots meta etiketi, arama motorlarına sayfayı arama sonuçlarında göstermemesini bildirir. özelliğinin değeri (), yönergenin tüm tarayıcılar için geçerli olduğunu belirtir. Belirli bir tarayıcıya yönelik yönerge vermek için özelliğinin değerini, ilgili tarayıcının adıyla değiştirin. Belirli tarayıcılar, kullanıcı aracıları (user-agents) olarak da bilinir (tarayıcılar, sayfa istemek için kendi kullanıcı aracılarını kullanır). Google’ın standart web tarayıcısının kullanıcı aracısının adı şeklindedir. Yalnızca Googlebot’un sayfanızı dizine eklemesini engellemek için etiketi aşağıdaki şekilde güncelleyin:
<meta name="googlebot" content="noindex" />
Bu etiket artık özellikle Google’a bu sayfayı web arama sonuçlarında göstermemesini bildirmektedir. Hem hem de özelliği büyük/küçük harfe duyarlı değildir.
Arama motorlarının, farklı amaçlar için farklı tarayıcıları olabilir. Google tarayıcılarının tam listesini inceleyin.
Örneğin, bir sayfayı Google’ın web arama sonuçlarında gösterirken Google Haberler’de göstermemek için aşağıdaki meta etiketi kullanın:
<meta name="googlebot-news" content="noindex" />
Birden çok tarayıcıyı bağımsız olarak belirtmek için birden çok robots meta etiketi kullanın:
<meta name="googlebot" content="noindex"> <meta name="googlebot-news" content="nosnippet">
Как использовать метатег robots
Метатег robots позволяет задавать на уровне страницы детальные настройки, которые определяют, как эта страница будет индексироваться и показываться в результатах поиска Google. Метатег robots следует размещать в разделе страницы. Пример:
<!DOCTYPE html> <html><head> <meta name="robots" content="noindex" /> (…) </head> <body>(…)</body> </html>
Код в этом примере запрещает поисковым системам показывать страницу в результатах поиска. Заданное для атрибута значение указывает, что директива предназначена для всех поисковых роботов. Если вы хотите закрыть доступ только одному из них, вместо укажите в значении атрибута название нужного робота. Отдельные поисковые роботы также называются агентами пользователя (поисковый робот использует агент пользователя для отправки запроса страницы). Агент пользователя стандартного поискового робота Google называется . Чтобы запретить сканирование страницы только роботу Googlebot, измените тег, как указано в примере ниже:
<meta name="googlebot" content="noindex" />
Такой тег сообщает Google, что эту страницу не следует показывать в результатах поиска. Атрибуты и можно указывать без учета регистра.
Для разных целей поисковые системы могут использовать разных роботов. Полный список роботов Google можно найти здесь.
Например, если вам нужно, чтобы контент со страницы был представлен в результатах веб-поиска Google, но не в Google Новостях, используйте следующий метатег:
<meta name="googlebot-news" content="noindex" />
Если нужно задать разные настройки для разных поисковых роботов, используйте несколько метатегов robots:
<meta name="googlebot" content="noindex"> <meta name="googlebot-news" content="nosnippet">
Google про мета-тег robots
Интересную информацию я нашел в справочнике Гугла:
Чтобы заблокировать большую часть поисковых роботов, добавьте следующий метатег в раздел <head> веб-страницы:
Если вы хотите закрыть доступ к странице только роботам Google, используйте такой код:
Другие поисковые системы могут иначе интерпретировать атрибут noindex на странице и показывать ее в результатах поиска.
По поводу ноуиндекс ничего нового мы не узнали, но зато я увидел вот что! В атрибуте name указано значение googlebot, а это говорит о том, что можно использовать различных поисковых ботов. Это я увидел в англоязычном справочнике Гугла.

Вот что пишет справочник Google
Странно здесь одно, что в справочнике Яндекса никакой информации про это я не увидел.
Что такое тег Noindex
Noindex — это тег, в который вы заключаете часть кода, и этот код по идее не должен индексироваться Яндексом. Тег ноиндекс был предложен именно Яндексом, и по сей день учитывается только системами Yandex и Rambler. Вот как он выглядит:
<noindex>скрываемый текст</noindex>
Noindex – парный тег, и его необходимо закрывать.
Noindex не чувствителен к вложенности.
Целесообразность использования тега
Лично я смысла в его использовании не вижу. Потому что Google этот тег игнорирует. Да и зачем скрывать что-то? Надо делать сайты для людей!
Раньше сеошники скрывали в него часть текста, чтобы не было переспама. Но лично я предпочитаю в целях борьбы с переспамом просто снижать количество ключей в наиболее важных зонах документа.
Если же вы все-таки решили пользоваться этим тегом, то гляньте видео от ТопЭксперт:
Директива max-image-preview:large
С версии WP 5.7 WordPress по умолчанию добавляет директиву max-image-preview:large в мета-тег на все страницы.
<meta name="robots" content="max-image-preview:large" />
Чтобы отключить эту директиву, можно использовать следующий код:
remove_filter( 'wp_robots', 'wp_robots_max_image_preview_large' );
max-image-preview:
Эта директива определяет максимальный размер изображений, которые могут показываться в результатах поиска для этой страницы.
Если не указать директиву max-image-preview, будет возможен предварительный просмотр изображения размером, заданным по умолчанию.
Допустимые значения для :
- none
- Нет изображения для предварительного просмотра.
- standard
- Может быть показано изображение для предварительного просмотра по умолчанию.
- large
- Может быть показано более крупное изображение, вплоть до максимальной ширины области просмотра.
Это распространяется на все виды результатов поиска (веб-поиск Google, Google Картинки, рекомендации и данные, предоставляемые Ассистентом). Ограничение не применяется в тех случаях, когда издатель предоставил отдельное разрешение на использование контента, например добавил структурированные данные или заключил лицензионное соглашение с компанией Google. В частности, структурированные данные могут определять каноническую и AMP-версию статьи.
Если вы не хотите, чтобы ваши канонические страницы и их AMP-версии были представлены в Google Поиске и рекомендациях в виде увеличенных значков, укажите в директиве значение или .
Метатеги для поисковых систем
Robots
Метатег указывает роботам поисковых систем, как сканировать и индексировать страницу.
Для конкретного бота можно задать свою инструкцию. Например, заменить robots на Googlebot для Гугла или на YandexBot для Яндекса.
Возможные указания:
- all – означает, что разрешена индексация и переход по ссылкам, аналогично index, follow;
- noindex – запрет индексации;
- index – разрешена индексация;
- nofollow – нельзя переходить по ссылкам;
- follow – можно переходить по ссылкам;
- noarchive – запрещено показывать ссылку на сохраненную копию в выдаче;
- noyaca – (для Яндекса) не использовать для сниппета описание из Яндекс.Каталога;
- nosnippet – (в Google) нельзя использовать для сниппета фрагмент текста и показывать видео;
- noimageindex – (в Google) запрет указания страницы как источника изображения;
- unavailable_after: – (в Google) после указанной даты будет прекращено сканирование и индексирование страницы;
- none – запрет индексации и перехода по ссылкам, аналогичен noindex, nofollow.
Description
Метатег name=«description» может использоваться поисковыми системами при формировании сниппета, поэтому он должен:
- точно описывать содержание страницы;
- вызывать желание кликнуть;
- включать продвигаемое ключевое слово.
В разных поисковых системах выводятся 160–240 символов.
Description для каждой продвигаемой страницы должен быть уникальным.
Keywords
Метатег name=«keywords» раньше использовался поисковыми системами при ранжировании, но из-за многочисленных манипуляций его значимость постоянно уменьшалась. Теперь большинство поисковиков его игнорируют. Google не поддерживает вообще, а Яндекс пишет, что может учитывать. Но на практике keywords давно не оказывает влияния, а его некорректное заполнение может привести к переспаму.
Существуют три подхода:
- оставлять пустым;
- писать конкретные фразы или отдельные слова через запятую;
- указать через пробел бессвязный набор слов, из которых могут быть составлены ключевые фразы.
Если принято решение прописать ключевые слова, важно не допускать спама. Ключевые слова должны характеризовать конкретную страницу и упоминаться в контенте
Ключевые слова должны характеризовать конкретную страницу и упоминаться в контенте.
Title
Title технически не является метатегом, но его часто относят к этой группе, потому что он содержит информацию, которая используется поисковыми системами и браузерами.
Данный HTML-тег важен для SEO: влияет на ранжирование и кликабельность по сниппету.
Классические рекомендации по заполнению метатега:
- использовать главное продвигаемое ключевое слово на странице;
- разместить ключ вначале;
- обеспечить уникальность внутри сайта;
- сделать привлекательным для пользователя;
- подобрать такую длину, чтобы заголовок не обрезался в сниппете.
Рекомендуема длина – 70–80 символов.
Как использовать noindex и nofollow
Тэг Noindex для любого контента применяется так:
текст, который надо скрыть <a href=”ссылка куда-то”>, и еще</a> текст</noindex>.
Весь текст и анкор ссылки изначально индексируются, но потом удаляются из базы поисковика. Гиперссылка индексируется, и вес по ней передается.
При работе с Ноиндекс существует вероятность того, что снизится валидность кода, так как данный тэг знает только российский поисковик. Поэтому рекомендуется следующий вариант написания:
<!—Noindex—> Весь текст, который надо скрыть <!—/noindex—>.
При этом другие поисковики просто его пропустят, и валидность кода останется неизменной.
Атрибут Nofollow для ссылок применяется
<a href=”веб-ссылка куда-то” rel=”nofollow”> анкор </a>
При этом анкор попадает в индекс, но поисковик по веб-ссылке не идет, вес на странице остается.
Если на странице слишком много Нофоллоу, то это может негативно сказаться на лояльности поисковиков.
Совместное использование
Для того чтобы закрыть и текстовую часть, и гиперссылку, следует придерживаться такого написания:
<!—Noindex—> Весь текст, который надо скрыть <a href=”веб-ссылка куда-то” rel=”nofollow”> анкор </a>, и еще текст <!—/noindex—>
Варианты правильного использования Noindex и Nofollow для запрета индексации документа в целом
Тег и атрибут, все время ходят “за ручку”, и часто их применяют вместе. Они могут применяться в meta name=robots документа для указания рекомендаций по его индексации и переходу по веб-ссылкам. Указание на запрет индексации необходимо, если обнаружены дубли страниц, Или в сети появилась конфиденциальная или устаревшая информация, а другим способом страницы убрать нельзя.
В случае, если вы хотите закрыть всю страницу от индексации и запретить учет располагающихся на ней ссылок, необходимо указать в метаданных страницы — следующее:

Ноуиндекс создает команду Яндексу не индексировать контент на странице, но робот ходит по ее веб-ссылкам. Поэтому дополнительный Ноуфоллоу указывает по ним на не ходить. Данное указание воспринимают как Яндекс, так и Google.
Что касается удаления документа из индекса Google, то поисковиком предусмотрен альтернативный метод: запись X-Robots-Tag: noindex, nofollow. Данное указание закрепляется в http-заголовках, не видимых в коде страницы.
Рассказываем о разнице между Nofollow и Noindex, как их правильно использовать для ссылок и скрытия контента на сайте.
Всегда следите за наличием рассмотренных в статье тегов и атрибутов в нужных местах, чтобы получать именно тот результат, которого вы ожидаете.
Use the newly created template to produce the final HTML documentation
Everything is now in place to produce the final documentation with the newly created template. We simply need to select it for the desired HTML build.
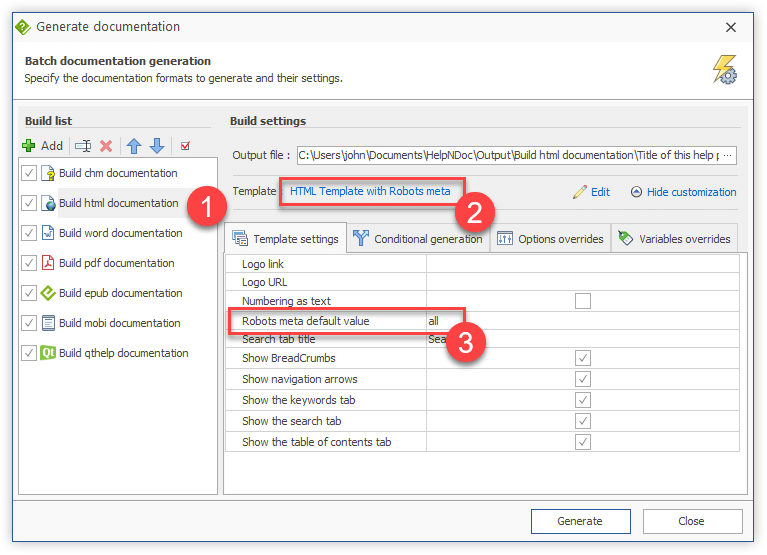
The newly create template can now be used by any HTML build in any HelpNDoc project. Here is how to proceed:
- From HelpNDoc’s “Home” ribbon tab, in the “Project” group, click the top part of the “Generate help” button
- Select the HTML build in the list
- Change the template to the newly created “HTML Template with Robots meta” by clicking the currently selected template’s name
- Click “Generate” to build the final documentation
In order to customize the default value of the robots meta tag, this can be done from the same dialog:
- Click “Customize” if the “Template settings” tab is not already visible
- In the “Template settings” tab, locate the “Robots meta default value” setting
- Change its value
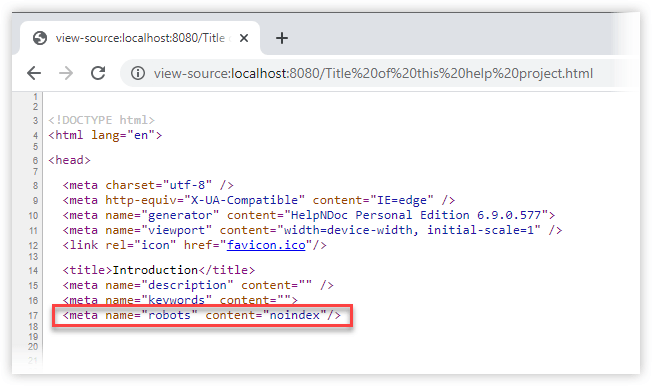
- Click “Generate” to build the updated final documentation: every HTML page will contain the new default value if not overridden for a specific topic
Thanks to HelpNDoc’s very powerful template system and customization capabilities, we can greatly customize the generated HTML documentation’s look and feel and optimize it for Search Engine Optimization (SEO) purposes. You can download your free copy of HelpNDoc now to test it for yourself for as long as needed.
See also
- Produce a Rich Text Format (RTF) file from your documentation project using the HelpNDoc help authoring tool
- Context sensitive HTML help and URL aliases for help topics in your HTML documentation web-sites
- 3 ways to speed-up hyperlink creation in your help file, user manual or eBook
- How to manage HelpNDoc’s panels: move and dock them where you want
- How to update the icons of your HTML documentation’s table of contents
Sep 23, 2020
Categories:
articles
Основные мета теги
Ниже приведены несколько основных тегов <meta> с комментариями по применению и примерами использования.
Meta-тег description
Краткое описание документа (страницы сайта). Поисковые системы могут использовать содержимое мета тега description для вывода в сниппете поисковой выдачи.

Пример использования мета тега description
Meta-тег keywords
Ключевые слова страницы. Ранее использовался для указания поисковым системам основные смысловые фразы веб-страницы. На данный момент существуют разные мнения как правильно и стоит ли заполнять мета тег keywords.
Пример заполнения мета тега keywords
Meta-тег viewport
Задает некоторые параметры окна просмотра в браузере. Атрибут width указывает ширину окна просмотра (вьюпорта), initial-scale — коэффициент масштабирования при первом открытии страницы.
Пример использования мета тега viewport
Мета тег для адаптивного сайта: указывает, что ширина вьюпорта подгоняется под размеры устройства:
Кодировка веб страницы. Наиболее частое значение: «UTF-8».
Пример использования мета тега кодировки charset
Meta тег refresh
Мета тег с атрибутом http-equiv=»refresh» указывает время автоматического обновления страницы. Страница будет автоматически перезагружаться с интервалом указанным в content атрибуте. Значение указывается в секундах.
Заключение
Конечно, не стоит закрывать все ссылки на сайте, обязательно ссылайтесь на полезные ресурсы для посетителя и никаких nofollow, noindex вам не понадобится. Потому что роль данных тегов важна с точки зрения индексации, но не с точки зрения продвижения вашего сайта. Ну к примеру, я не использовал данный тег и мои сайты ранжировались нормально. Это скорее некая дополнительная фича к robots.txt.
Не злоупотребляйте спамными техниками и прочими черными методами продвижения сайтов и старайтесь не слушать биржи о покупке ссылок и волшебном продвижении в ТОП 10, и ничего за это вам не будет. Поймите – их цель продать вам продукт и они будут вливать вам как можно больше воды. Можно продвигать сайт без них, есть конкретные кейсы и примеры (точнее без покупки ссылок), ну а в сегодняшней статье всё.
Как вы используете meta-robots name?
Используете ли вы различных ботов (googlebot, googlebotnews) для запрета индексации той или иной страницы?
