Http
Содержание:
- Технический обзор
- 5 последних уроков рубрики «Разное»
- Что такое HTTP/2 и зачем он нужен
- Ключи шифрования
- HTTP-СОЕДИНЕНИЕ
- Прикидываемся браузером, или делаем HTTP-запрос из терминала
- 3.4 Кодовые таблицы (character sets).
- 3.9 Качественные значения (Quality Values).
- 3.6 Кодирование передачи (Transfer Codings).
- Функциональность
- What can be controlled by HTTP
- Для чего нужен HTTP
- 3.10 Метки языков (Language Tags).
- HTTP-сеанс [ править ]
- Basic aspects of HTTP
- HTTP/1.0 — 1996
- Преимущество http/2 для разработчиков
Технический обзор
URL-адрес, начинающийся со схемы HTTP и метки имени домена WWW
HTTP функционирует как протокол запроса-ответа в вычислительной модели клиент-сервер. Веб — браузер , например, может быть клиент и приложение , запущенное на компьютере хостинг на веб — сайт может быть сервер . Клиент отправляет на сервер сообщение HTTP- запроса . Сервер, который предоставляет ресурсы, такие как файлы HTML и другой контент, или выполняет другие функции от имени клиента, возвращает ответное сообщение клиенту. Ответ содержит информацию о статусе завершения запроса, а также может содержать запрошенное содержимое в теле сообщения.
Веб-браузер — это пример пользовательского агента (UA). Другие типы пользовательских агентов включают программное обеспечение для индексирования, используемое поставщиками поиска ( веб-сканеры ), голосовыми браузерами , мобильными приложениями и другим программным обеспечением, которое получает доступ, потребляет или отображает веб-контент.
HTTP разработан, чтобы позволить промежуточным элементам сети улучшать или обеспечивать связь между клиентами и серверами. Веб -сайты с высокой посещаемостью часто выигрывают от серверов веб-кеша, которые доставляют контент от имени вышестоящих серверов, чтобы сократить время отклика. Веб-браузеры кэшируют ранее использованные веб-ресурсы и повторно используют их, когда это возможно, для уменьшения сетевого трафика. Прокси-серверы HTTP на границах частной сети могут облегчить связь для клиентов без глобально маршрутизируемого адреса путем ретрансляции сообщений с внешними серверами.
HTTP — это протокол прикладного уровня , разработанный в рамках набора Интернет-протоколов . Его определение предполагает лежащий в основе и надежный протокол транспортного уровня , и обычно используется протокол управления передачей (TCP). Однако HTTP может быть адаптирован для использования ненадежных протоколов, таких как протокол дейтаграмм пользователя (UDP), например, в HTTPU и протоколе обнаружения простых служб (SSDP).
HTTP / 1.1 — это версия исходного HTTP (HTTP / 1.0). В HTTP / 1.0 для каждого запроса ресурса выполняется отдельное соединение с одним и тем же сервером. HTTP / 1.1 может повторно использовать соединение несколько раз для загрузки изображений, скриптов , таблиц стилей и т.д. после того, как страница была доставлена. Таким образом, связь HTTP / 1.1 имеет меньшую задержку, поскольку установление TCP-соединений связано со значительными накладными расходами.
5 последних уроков рубрики «Разное»
-
Выбрать хороший хостинг для своего сайта достаточно сложная задача. Особенно сейчас, когда на рынке услуг хостинга действует несколько сотен игроков с очень привлекательными предложениями. Хорошим вариантом является лидер рейтинга Хостинг Ниндзя — Макхост.
-
Как разместить свой сайт на хостинге? Правильно выбранный хороший хостинг — это будущее Ваших сайтов
Проект готов, Все проверено на локальном сервере OpenServer и можно переносить сайт на хостинг. Вот только какую компанию выбрать? Предлагаю рассмотреть хостинг fornex.com. Отличное место для твоего проекта с перспективами бурного роста.
-
Создание вебсайта — процесс трудоёмкий, требующий слаженного взаимодействия между заказчиком и исполнителем, а также между всеми членами коллектива, вовлечёнными в проект. И в этом очень хорошее подспорье окажет онлайн платформа Wrike.
-
Подборка из нескольких десятков ресурсов для создания мокапов и прототипов.
Что такое HTTP/2 и зачем он нужен
Протокол HTTP/1.1 используется с 1999 года и со временем обрел одну существенную проблему. Современные сайты, в отличие от того, что было распространено в 1999-м году, используют множество различных элементов: скрипты на Javascript, стили на CSS, иногда еще и flash-анимацию. При передаче всего этого хозяйства между браузером и сервером создаются несколько соединений.
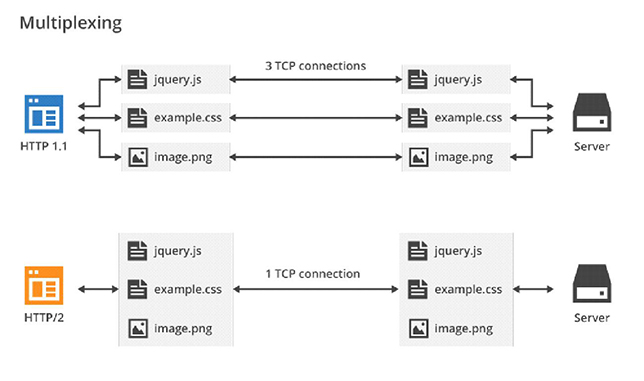
Протокол HTTP/2 существенно ускоряет открытие сайтов за счет следующих особенностей:
соединения: несколько запросов могут быть отправлены через одно TCP-соединение, и ответы могут быть получены в любом порядке. Отпадает необходимость держать несколько TCP-соединений;
приоритеты потоков: клиент может задавать серверу приоритеты — какого типа ресурсы для него более важны, чем другие;
сжатие заголовка: размер заголовка HTTP может быть сокращен;
push-отправка данных со стороны сервера: сервер может отправлять клиенту данные, которые тот еще не запрашивал, например, на основании данных о том, какую следующую страницу открывают пользователи.
Замеряем пульс российского диджитал-консалтинга
Какие консалтинговые услуги востребованы на российском рынке, и как они меняют бизнес-процессы? Представляете компанию-заказчика диджитал-услуг?
Примите участие в исследовании Convergent, Ruward и Cossa!
Разработка протокола HTTP/2 основывалась на другом протоколе SPDY, который был разработан Google, но компания Google уже объявила о том, что откажется от дальнейшей поддержки SPDY в пользу более многообещающего HTTP/2.
Ключи шифрования
Кроме подтверждения подлинности сайта, SSL-сертификат шифрует данные. После того как браузер убедился в подлинности сайта, начинается обмен шифрами. Шифрование HTTPS происходит при помощи симметричного и асимметричного ключа. Вот что это значит:
Чтобы установить HTTPS-соединение, браузеру и серверу надо договориться о симметричном ключе. Для этого сначала браузер и сервер обмениваются асимметрично зашифрованными сообщениями, где указывают секретный ключ и далее общаются при помощи симметричного шифрования.
Итак, какова функция протокола HTTPS?
Также стоит упомянуть, какой порт используется протоколом HTTPS по умолчанию. HTTPS использует для подключения 443 порт — его не нужно дополнительно настраивать
HTTP-СОЕДИНЕНИЕ
Соединение между клиентом и сервером устанавливается обязательно до того, как они смогут “общаться” друг с другом, при этом используется самый надежный протокол-TCP. По умолчанию, TCP использует 80-ый порт. Поток разбивается на пакеты IP,что гарантирует получение пакетов в правильном порядке без потерь. HTTP-протокол прикладного уровня TCP, основанного на IP. HTTPS — защищенная версия HTTP, куда вставлены дополнительные уровни между HTTP и TCP, называемые TLS и SSL (Transport Layer Security и Secure Sockets Layer, соответственно). По умолчанию, HTTPS использует 443-ий TCP-порт, и в данной статье будет рассмотрен именно HTTPS- протокол.

Подключение HTTP идентифицируется как <исходный IP, исходный порт> и <IP приемника, порт приемника>. На клиентском уровне протокол представлен кортежем: <IP, порт>. Установка соединения между двумя конечными точками — процесс многоступенчатый. Он включает в себя следующие шаги:

- расчет IP адреса по имени хоста DNS,
- установление соединения с сервером,
- отправка запроса,
- ожидание ответа,
- закрытие соединения.
В HTTP/1.0, все соединения закрывались после одной транзакции. Таким образом, если клиент запрашивал три отдельных изображения с одного сервера, он трижды подключался к удаленному хосту. Как видно на схеме выше, это вызывает множество задержек в сети, что приводит к не-оптимальной работе.
Чтобы избавиться от этих задержек, в HTTP/1.1 были введены постоянные соединения — долгоживущие соединения, которые остаются открытыми, пока клиент не закроет их. Эти соединения используются по умолчанию, а чтобы произвести транзакцию клиент должен установить соединение: “Connection: close” в заголовке запроса. Это значит, что сервер должен прервать соединение сразу после того, как оправит ответ клиенту.
Помимо постоянных соединений, браузеры / клиенты для минимизации времени задержек сети используют метод, называемый параллельные соединения. Старая концепция параллельных соединений заключается в создании пула соединений (как правило, не более шести соединений). То есть, если клиент хочет загрузить с веб-сайта шесть ресурсов, создаются шесть параллельных соединений, в результате чего время отклика становится минимальным. Это огромный плюс по сравнению с последовательными соединениями, где клиент скачивает ресурсы друг за другом.
Параллельные соединения в сочетании с постоянными соединениями — вот ответ сегодняшним технологиям сведения к минимуму задержки в сети. Углубленный анализ подключений HTTP рассмотрен в разделе (спецификация HTTP)
Прикидываемся браузером, или делаем HTTP-запрос из терминала
Чтобы понять, как браузер общается с сервером, нужно думать как браузер, нужно стать браузером.
Попробуем обратиться к веб-странице http://http.maxkuznetsov.ru так, как это делают браузеры под капотом. Для этого отправим запрос из терминала/командной строки с помощью утилиты netcat. Чаще всего она установлена по умолчанию: в Mac OS X — это «nc», в других ОС может быть «ncat» или «netcat». (Или воспользуйтесь онлайн-сервисом https://reqbin.com/u4178vu3, в котором слева и справа выберите табы Raw для отображения «голых» запросов и ответов. Но из терминала получится нагляднее.)
Дальше ничего не произойдёт, терминал подвиснет — это нормально. Команда netcat подключилась к серверу по адресу http.maxkuznetsov.ru к 80-му порту, и сервер ждёт от нас текст запроса.
Введём в терминале такие строки запроса.
После Host нужно ввести две пустые строки: одна строка отступа, вторая содержит тело запроса, но в данном примере оно пустое. Такие правила протокола HTTP. Получив вторую пустую строку, веб-сервер поймёт, что запрос завершён, обработает его и пришлёт ответ, включающий интересующую нас веб-страницу с html.
После этого браузер разбирает ответ, убирает техническую информацию и отображает html-страницу в кодировке UTF-8 — так ему сказал сервер в заголовке Content-Type. Если в HTML включены CSS, Javascript, картинки, то браузер запросит их отдельными запросами ровно таким же образом. Если он их уже запрашивал раньше, то возьмёт из локального кэша. Поэтому первый раз страницы грузятся визуально дольше.
Разберём структуру запроса и ответа более детально.
3.4 Кодовые таблицы (character sets).
HTTP использует то же самое определение термина «кодовая таблица»,
которое описано для MIME:
Термин «кодовая таблица» используется в данном документе, чтобы
сослаться на метод, использующий одну или несколько таблиц для
преобразования последовательности октетов в последовательность
символов. Стоит отметить, что однозначное преобразование в
обратном направлении не требуется, и что не все символы могут
быть доступны в данной кодовой таблице, и что кодовая таблица
может обеспечивать более чем одну последовательность октетов для
представления специфических символов. Это определение допускает
различные виды кодирования символов, от простых однотабличных
отображений типа US-ASCII до сложных методов, переключающих
таблицы, наподобие тех, которые используют методики ISO 2022.
Однако определение, связанное с именем кодовой таблицы MIME
ДОЛЖНО полностью определять отображение, которое преобразует
октеты в символы. В частности использование внешней информации
профилирования для определения точного отображения не
разрешается.
Обратите внимание: Это использование термина «кодовая таблица»
обычно упоминается как «кодирование символов»
Однако, с тех пор
как HTTP и MIME совместно используют одиннаковую запись, важно,
чтобы совпадала также и терминология.. Кодовые таблицы HTTP идентифицируются лексемами, не чувствительными
к регистру
Полный набор лексем определен реестром кодовых таблиц
.
Кодовые таблицы HTTP идентифицируются лексемами, не чувствительными
к регистру. Полный набор лексем определен реестром кодовых таблиц
.
charset = token
Хотя HTTP позволяет использовать в качестве значения charset
произвольную лексему, любая лексема, которая имеет предопределенное
значение в реестре кодовых таблиц IANA, ДОЛЖНА представлять набор
символов, определенный в данном реестре. Приложениям СЛЕДУЕТ
ограничить использование символьных наборов теми, которые
определены в реестре IANA.
3.9 Качественные значения (Quality Values).
Обсуждение содержимого HTTP (раздел 12) использует короткие числа «с
плавающей точкой» для указания относительной важности («веса»)
различных оговоренных параметров. Вес — это нормализованое
вещественное число в диапазоне от 0 до 1, где 0 — минимальное, а
1 — максимальное значение
HTTP/1.1 приложения НЕ ДОЛЖНЫ
генерировать более трех цифр после десятичной точки.
Пользовательским конфигурациям этих значений СЛЕДУЕТ также
ограничиваться этим режимом.
qvalue = ( "0" )
| ( "1" )
«Качественные значения» — не корректное название, так как эти
значения просто представляют отношение снижения производительности
к желательному качеству.
3.6 Кодирование передачи (Transfer Codings).
Значения кодирования передачи используются для указания
преобразования кодирования, которое было или должно быть применено
к телу объекта (entity-body) в целях гарантирования «безопасной
передачи» по сети. Оно отличается от кодирования содержимого тем,
что кодирование передачи — это свойство сообщения, а не
первоначального объекта.
transfer-coding = "chunked" | transfer-extension
transfer-extension = token
Все значения кодирования передачи (transfer-coding) не
чувствительны к регистру. HTTP/1.1 использует значения кодирования
передачи (transfer-coding) в поле заголовка Transfer-Encoding
().
Кодирования передачи — это аналоги значений
Content-Transfer-Encoding MIME, которые были разработаны для
обеспечения безопасной передачи двоичных данных при использовании
7-битного обслуживания передачи. Однако безопасный транспорт
имеет другое предназначение для чисто 8-битного протокола передачи.
В HTTP единственая опасная характеристика тела сообщения вызвана
сложностью определения точной длины тела сообщения (),
или желанием шифровать данные при пользовании общедоступным
транспортом.
Кодирование по кускам (chunked encoding) изменяет тело сообщения
для передачи его последовательностью кусков, каждый из которых
имеет собственный индикатор размера, сопровождаемым опциональным
завершителем, содержащим поля заголовка объекта. Это позволяет
динамически создаваемому содержимому передаваться вместе с
информацией, необходимой получателю для проверки полноты получения
сообщения.
Chunked-Body = *chunk
"0" CRLF
footer
CRLF
chunk = chunk-size CRLF
chunk-data CRLF
hex-no-zero = <HEX за исключением "0">
chunk-size = hex-no-zero *HEX
chunk-ext = *( ";" chunk-ext-name )
chunk-ext-name = token
chunk-ext-val = token | quoted-string
chunk-data = chunk-size(OCTET)
footer = *entity-header
Кодирование по кускам (chunked encoding) оканчивается куском
нулевого размера, следующим за завершителем, оканчивающимся пустой
строкой. Цель завершителя состоит в эффективном методе обеспечения
информации об объекте, который сгенерирован динамически; приложения
НЕ ДОЛЖНЫ посылать в завершителе поля заголовка, которые явно не
предназначены для использования в завершителе, такие как
Content-MD5 или будущие расширения HTTP для цифровых подписей и
других возможностей.
Примерный процесс декодирования Chunked-Body представлен в
.
Все HTTP/1.1 приложения ДОЛЖНЫ быть в состоянии получать и
декодировать кодирование передачи «по кускам» («chunked» transfer
coding), и ДОЛЖНЫ игнорировать расширения кодирования передачи,
которые они не понимают. Серверу, который получил тело объекта со
значением кодирования передачи, которое он не понимает, СЛЕДУЕТ
возвратить ответ с кодом 501 (Не реализовано, Not Implemented) и
разорвать соединение. Сервер НЕ ДОЛЖЕН посылать поля кодирования
передачи (transfer-coding) HTTP/1.0 клиентам.
Функциональность
Механизм и концепция HTTP включает в себя то, что файлы связаны с другими файлами через ряд ссылок. Этот выбор вызовет дополнительные запросы на передачу. Любое устройство веб-сервера на самом деле содержит программу, которая называется HTTP-демоном, которая предназначена для прогнозирования HTTP-запросов и обработки их по их получении. Типичный веб-браузер — это HTTP-клиент, который постоянно посылает запросы на серверные устройства. Пользователь вводит запросы в файл, проходя через веб-файл, который в данном случае обычно является URL-адресом, или нажимает на ссылку; браузер формирует HTTP-запрос, а затем отправляет его на IP-адрес, указанный через URL.
HTTP следует заданному циклу всякий раз, когда посылает запрос:
- Браузер запросит HTML-страницу. Затем сервер возвращает HTML-файл с хоста.1
- Браузер запросит таблицу стилей. Затем сервер возвращает файл CSS.
- Браузер запрашивает изображение в формате JPG. Сервер возвращает файл JPG.
- Браузер запросит код JavaScript (язык программирования). После этого сервер возвращает JS-файл.
- Браузер запрашивает различные формы данных. Сервер возвращает данные в виде XML или JSON файлов.
What can be controlled by HTTP
This extensible nature of HTTP has, over time, allowed for more control and functionality of the Web. Cache or authentication methods were functions handled early in HTTP history. The ability to relax the origin constraint, by contrast, has only been added in the 2010s.
Here is a list of common features controllable with HTTP.
-
Caching
How documents are cached can be controlled by HTTP. The server can instruct proxies and clients, about what to cache and for how long. The client can instruct intermediate cache proxies to ignore the stored document. -
Relaxing the origin constraint
To prevent snooping and other privacy invasions, Web browsers enforce strict separation between Web sites. Only pages from the same origin can access all the information of a Web page. Though such constraint is a burden to the server, HTTP headers can relax this strict separation on the server side, allowing a document to become a patchwork of information sourced from different domains; there could even be security-related reasons to do so. -
Authentication
Some pages may be protected so that only specific users can access them. Basic authentication may be provided by HTTP, either using the and similar headers, or by setting a specific session using HTTP cookies. -
Proxy and tunneling
Servers or clients are often located on intranets and hide their true IP address from other computers. HTTP requests then go through proxies to cross this network barrier. Not all proxies are HTTP proxies. The SOCKS protocol, for example, operates at a lower level. Other protocols, like ftp, can be handled by these proxies. -
Sessions
Using HTTP cookies allows you to link requests with the state of the server. This creates sessions, despite basic HTTP being a state-less protocol. This is useful not only for e-commerce shopping baskets, but also for any site allowing user configuration of the output.
Для чего нужен HTTP
Благодаря взаимодействию клиента (локального компьютера с браузером) и сервера (высокопроизводительного специального компьютера) в сети можно передавать данные. Изначально HTTP использовался только для гипертекстовых документов, но сейчас он может передавать любую информацию. Гипертекстовые документы также могут содержать гиперcсылки, при нажатии на которые формируется новый http-запрос, в ответе на который может содержаться другой гипертекстовый документ. Таким образом мы перемещаемся по страницам в интернете.
Как он работает
HTTP-запрос состоит из трех элементов:
- стартовой строки, которая задает параметры запроса или ответа,
- заголовка, который описывает сведения о передаче и другую служебную информацию.
- тело (его не всегда можно встретить в структуре). Обычно в нем как раз лежат передаваемые данные. От заголовка тело отделяется пустой строкой.
Важнейшим элементом структуры запроса является стартовая строка. Благодаря ей сервер понимает, что от него хотят. Вот как она устроена:
Метод + URI + HTTP/Версия
Метод (иногда его называют HTTP-глаголом) – описывает, какое именно действие нужно совершить со страницей. Можно придумать самые разные, но стандартных методов девять: GET, HEAD, POST, PUT, DELETE,CONNECT, OPTIONS, TRACE, PATCH. Их функциональность раскрывается в названии, они позволяют получить данные (GET), отправить данные на сервер (POST), удалить (DELETE) или заменить часть (PATCH).
URI (Uniform Resource Locator) – единообразный идентификатор ресурса, идентифицирует ресурс и определяет его точное местоположение. Именно с помощью URL записаны ссылки в интернете.
В отличие от него URN не ведет к конкретному адресу, а просто определяет ресурс во множестве терминов. Потенциально это удобно, чтобы не перегружать интернет устаревшими или пропавшими ссылками.
Версия показывает, какую версию протокола нужно использовать в ответе сервера.
HTTP-ответ строится примерно по тому же принципу, что и запрос:
HTTP/Версия + Код состояния + Пояснение
Версия совпадает с версией в запросе.
Код состояния показывает статус запроса. Это трехзначное число, благодаря которому можно узнать, получен ли запрос, обработан ли он, какие ошибки есть. Например, одна из самых известных ошибок – 404 – сообщает о том, что сервер не нашел ресурс по адресу. Возможно, в запросе опечатка, ошибка или он не соответствует протоколу.
В пояснении стоит краткое описание ответа, например, к той же ошибке 404 может добавляться Not Found, что и раскрывает суть статуса запроса.
Курс
Этичный хакер
Начните с программирования на Python и JavaScript, изучите Linux и Windows и освойте тестирование на проникновение. Скидка 5% по промокоду BLOG.
Узнать больше
3.10 Метки языков (Language Tags).
Метка языка идентифицирует естественный язык: разговорный,
письменный, или другой используемый людьми для обмена информацмей
с другими людьми. Машинные языки являются исключением. HTTP
использует метки языка внутри полей Accept-Language и
Content-Language.
Синтаксис и запись HTTP меток языка такие же, как определяемые
. В резюме, метка языка состоит из одной или нескольких
частей: метка первичного языка и, возможно пустой, ряд подчиненных
меток:
language-tag = primary-tag *( "-" subtag )
primary-tag = 1*8ALPHA
subtag = 1*8ALPHA
Внутри метки не допустим пробел и все метки не чувствительны к
регистру. Пространство имен меток языка управляется IANA. Например
метки содержат:
en, en-US, en-cockney, i-cherokee, x-pig-latin
Любая двухсимвольная первичная метка является меткой аббревеатуры
языка ISO 639, а любая двухсимвольная подчиненная метка является
меткой кода страны ISO 3166. (Последние три метки из
вышеперечисленных — не зарегистрированные метки; все, кроме
последней — примеры меток, которые могли бы быть зарегистрированы
в будущем.)
HTTP-сеанс [ править ]
HTTP-сеанс — это последовательность сетевых транзакций запрос – ответ. Клиент HTTP инициирует запрос, устанавливая соединение протокола управления передачей (TCP) с определенным портом на сервере (обычно порт 80, иногда порт 8080; см. Список номеров портов TCP и UDP ). HTTP-сервер, прослушивающий этот порт, ожидает сообщения запроса от клиента. После получения запроса сервер отправляет обратно строку состояния, например « HTTP / 1.1 200 OK », и собственное сообщение. Тело этого сообщения обычно является запрошенным ресурсом, хотя также может быть возвращено сообщение об ошибке или другая информация.
Постоянные соединения править
В HTTP / 0.9 и 1.0 соединение закрывается после одной пары запрос / ответ. В HTTP / 1.1 был введен механизм keep-alive, при котором соединение можно было повторно использовать для более чем одного запроса. Такие постоянные соединения заметно сокращают задержку запроса, поскольку клиенту не нужно повторно согласовывать соединение TCP 3-Way-Handshake после отправки первого запроса. Еще один положительный побочный эффект заключается в том, что в целом соединение со временем становится быстрее из-за механизма TCP.
Версия 1.1 протокола также улучшила оптимизацию полосы пропускания для HTTP / 1.0. Например, в HTTP / 1.1 введено кодирование передачи по частям, позволяющее передавать контент в постоянных соединениях в потоковом режиме, а не в буфере. Конвейерная обработка HTTP дополнительно сокращает время задержки, позволяя клиентам отправлять несколько запросов, прежде чем ждать каждого ответа. Еще одним дополнением к протоколу стало обслуживание байтов , когда сервер передает только часть ресурса, явно запрошенную клиентом.
Состояние сеанса HTTP править
HTTP — это протокол без сохранения состояния . Протокол без сохранения состояния не требует, чтобы HTTP-сервер сохранял информацию или статус о каждом пользователе в течение нескольких запросов. Однако некоторые веб-приложения реализуют состояния или сеансы на стороне сервера, используя, например, файлы cookie HTTP или скрытые переменные в веб-формах .
Basic aspects of HTTP
HTTP is generally designed to be simple and human readable, even with the added complexity introduced in HTTP/2 by encapsulating HTTP messages into frames. HTTP messages can be read and understood by humans, providing easier testing for developers, and reduced complexity for newcomers.
Introduced in HTTP/1.0, HTTP headers make this protocol easy to extend and experiment with. New functionality can even be introduced by a simple agreement between a client and a server about a new header’s semantics.
HTTP is stateless: there is no link between two requests being successively carried out on the same connection. This immediately has the prospect of being problematic for users attempting to interact with certain pages coherently, for example, using e-commerce shopping baskets. But while the core of HTTP itself is stateless, HTTP cookies allow the use of stateful sessions. Using header extensibility, HTTP Cookies are added to the workflow, allowing session creation on each HTTP request to share the same context, or the same state.
A connection is controlled at the transport layer, and therefore fundamentally out of scope for HTTP. Though HTTP doesn’t require the underlying transport protocol to be connection-based; only requiring it to be reliable, or not lose messages (so at minimum presenting an error). Among the two most common transport protocols on the Internet, TCP is reliable and UDP isn’t. HTTP therefore relies on the TCP standard, which is connection-based.
Before a client and server can exchange an HTTP request/response pair, they must establish a TCP connection, a process which requires several round-trips. The default behavior of HTTP/1.0 is to open a separate TCP connection for each HTTP request/response pair. This is less efficient than sharing a single TCP connection when multiple requests are sent in close succession.
In order to mitigate this flaw, HTTP/1.1 introduced pipelining (which proved difficult to implement) and persistent connections: the underlying TCP connection can be partially controlled using the header. HTTP/2 went a step further by multiplexing messages over a single connection, helping keep the connection warm and more efficient.
Experiments are in progress to design a better transport protocol more suited to HTTP. For example, Google is experimenting with QUIC which builds on UDP to provide a more reliable and efficient transport protocol.
HTTP/1.0 — 1996
В отличие от HTTP/0.9, спроектированного только для HTML-ответов, HTTP/1.0 справляется и с другими форматами: изображения, видео, текст и другие типы контента. В него добавлены новые методы (такие, как POST и HEAD). Изменился формат запросов/ответов. К запросам и ответам добавились HTTP-заголовки. Добавлены коды состояний, чтобы различать разные ответы сервера. Введена поддержка кодировок. Добавлены составные типы данных (multi-part types), авторизация, кэширование, различные кодировки контента и ещё многое другое.
Вот так выглядели простые запрос и ответ по протоколу HTTP/1.0:
Помимо запроса клиент посылал персональную информацию, требуемый тип ответа и т.д. В HTTP/0.9 клиент не послал бы такую информацию, поскольку заголовков попросту не существовало.
Пример ответа на подобный запрос:
В начале ответа стоит HTTP/1.0 (HTTP и номер версии), затем код состояния — 200, затем — описание кода состояния.
В новой версии заголовки запросов и ответов были закодированы в ASCII (HTTP/0.9 весь был закодирован в ASCII), а вот тело ответа могло быть любого контентного типа — изображением, видео, HTML, обычным текстом и т. п. Теперь сервер мог послать любой тип контента клиенту, поэтому словосочетание «Hyper Text» в аббревиатуре HTTP стало искажением. HMTP, или Hypermedia Transfer Protocol, пожалуй, стало бы более уместным названием, но все к тому времени уже привыкли к HTTP.
Один из главных недостатков HTTP/1.0 — то, что вы не можете послать несколько запросов во время одного соединения. Если клиенту надо что-либо получить от сервера, ему нужно открыть новое TCP-соединение, и, как только запрос будет выполнен, это соединение закроется. Для каждого следующего запроса нужно создавать новое соединение.
Почему это плохо? Давайте предположим, что вы открываете страницу, содержащую 10 изображений, 5 файлов стилей и 5 JavaScript файлов. В общей сложности при запросе к этой странице вам нужно получить 20 ресурсов — а это значит, что серверу придётся создать 20 отдельных соединений. Такое число соединений значительно сказывается на производительности, поскольку каждое новое TCP-соединение требует «тройного рукопожатия», за которым следует медленный старт.
Тройное рукопожатие
«Тройное рукопожатие» — это обмен последовательностью пакетов между клиентом и сервером, позволяющий установить TCP-соединение для начала передачи данных.
- SYN — Клиент генерирует случайное число, например, x, и отправляет его на сервер.
- SYN ACK — Сервер подтверждает этот запрос, посылая обратно пакет ACK, состоящий из случайного числа, выбранного сервером (допустим, y), и числа x + 1, где x — число, пришедшее от клиента.
- ACK — клиент увеличивает число y, полученное от сервера и посылает y + 1 на сервер.
Примечание переводчика: SYN — синхронизация номеров последовательности, (англ. Synchronize sequence numbers). ACK — поле «Номер подтверждения» задействовано (англ. Acknowledgement field is significant).

Только после завершения тройного рукопожатия начинается передача данных между клиентом и сервером. Стоит заметить, что клиент может посылать данные сразу же после отправки последнего ACK-пакета, однако сервер всё равно ожидает ACK-пакет, чтобы выполнить запрос.
Тем не менее, некоторые реализации HTTP/1.0 старались преодолеть эту проблему, добавив новый заголовок Connection: keep-alive, который говорил бы серверу «Эй, дружище, не закрывай это соединение, оно нам ещё пригодится». Однако эта возможность не была широко распространена, поэтому проблема оставалась актуальна.
Помимо того, что HTTP — протокол без установления соединения, в нём также не предусмотрена поддержка состояний. Иными словами, сервер не хранит информации о клиенте, поэтому каждому запросу приходится включать в себя всю необходимую серверу информацию, без учёта прошлых запросов. И это только подливает масла в огонь: помимо огромного числа соединений, которые открывает клиент, он также посылает повторяющиеся данные, излишне перегружая сеть.
Преимущество http/2 для разработчиков
Современный протокол избавляет разработчиков от большого
количества устаревших мероприятий, к которым ранее им приходилось прибегать для
ускорения загрузки документов:
-
Доменное
шардирование. Раньше в http/1.1
число открытых соединений было ограничено. Но можно было установить большое количество
соединений за счет загрузки файлов сразу с нескольких поддоменов, чтобы
ускорить работу. Такой подход был особенно актуальным для сайтов, куда
загружено множество изображений. Теперь благодаря HTTP/2 нет нужды прибегать к домен-шардингу,
потому что протокол дает возможность запросить неограниченное количество ресурсов.
Тем более, что с новым протоколом доменное шардирование не только не повысит производительность,
но и нагрузит сервер лишними соединениями. -
Объединение
скриптов Java и CSS. Процедура заключается в том, чтобы из множества
маленьких файлов создать один большой. Это конечно уменьшает число запросов, но
пользователь, посетив страницу, загрузит абсолютно все CSS и JS файлы, даже те, которые ему не
понадобятся. Соответственно объединение файлов съедает память. Еще одна
трудность – все элементы нуждаются в одновременной чистке из кэша, так как
недопустимо, чтобы дата окончания срока действия каждого из них разнилась. Если
поменять даже одну строку в CSS,
срок действия закончится у всех элементов одновременно. HTTP/2 позволяет не прибегать к объединению
файлов, потому что он не затрачивает много ресурсов. -
Объединение
картинок (спрайты). Тоже снижает количество запросов, но так как вес изображения
увеличится, загружаться он будет дольше. Более того, для показа хотя бы одной
картинки нужно загрузить весь спрайт. Вывод – применение спрайтов чревато занятием
больших объемов памяти. -
Доменные
имена без cookie. Подразумевает загрузку
изображений, JS и CSS файлов с другого домена, где нет данных cookie. -
Перенос JavaScript, CSS, картинок в HTML-файл. Аналогично уменьшает количество соединений, но
страница не отобразится до полной загрузки всего файла.
