15 best wayback machine alternatives 2021
Содержание:
- FAQ
- Archive.is
- Индексация веб-страниц в интернете
- Screenshot History for Any Website – Screenshots.com
- web.archive.org
- Возможности использования веб-архивов
- Как проверять полученные статьи на уникальность
- Итак, приступим:
- Восстановление сайта с помощью «Archivarix»
- Archive-It
- Conclusion
- Как найти уникальный контент для своего сайта
- Как избавиться от рекламы WAYBACK MACHINE в Chrome/Firefox/Internet Explorer/Edge?
- Which Sites Are Cataloged?
FAQ
I download from Wayback Machine but can use only a home page of the site, why?
The site you download from Wayback Machine needs to be installed on the server. You can’t just view all its pages on your PC. Also, make sure you’ve installed thefile called .htaccess on the server – it is responsible for the correctness of URLs working. Mind that it is compatible with Apache servers only. Finally, checkwhether you used a demo or paid archive.org Downloader. The demo version has a limit of 4 pages.
Why does Wayback Machine Downloader work slowly?
Sometimes, when you download Wayback Machine sites, you have to wait for several hours until the process is completed, especially is the site is large. This is primarily the fault of the Web Archive itself rather than the archive.org Downloader. The Archive is slow; moreover, it can block IPs, which try to downloadWayback Machine files too fast. The speed can further drop down if the original site contains many broken links.
Don’t I break the copyright laws by using the Wayback Machine Downloader?
If you use the archive.org Downloader to restore your own site, then, obviously, you don’t violate any laws, and the content belongs to you. When it comes to accessing third-party sites by using Wayback downloads, the legislative norms can vary from one country to another. But anyway, the risk is minimal, as few peoplecare much about their former websites. Thus, there are no recorded cases of complaints about using third-party expired content.
How long should I wait for the delivery of a WordPress conversion?
The conversion itself usually takes no more than 1-2 business days. But you need to keep in mind that depending on the Wayback Machine download site size, thedownload process can take from several hours to several days.
Will the Downloader tool archive entire website or a single page that I specify?
The Wayback Machine Downloader always extracts entire sites (up to 20 thousand pages per domain.) All the pages that can be accessed from the starting page willbe automatically downloaded.
What is the total number of files the Wayback Machine Downloader can extract?
The Wayback Machine Downloader will try to get all files that are found on the domain. But sometimes, attempts fail if the Web Archive declines the requests. Commonly, the webarchive extractor makes up to five attempts using different IP-addresses.
If you have additional questions of how to download from archive.org effectively and correctly, read the full review on the official site of the download WaybackMachine tool. It contains detailed guides and instructions on archive downloading, extracting, installing, and using.
Archive.is
Archive.is is another good alternative to Wayback Machine and arguably better than Screenshots for most people. It is not one of the most attractive websites or easy to navigate, but its database and archiving methods makes up for it.
Archive.is will let you both search for website history and let you take a screenshot of any domain on demand, which will be saved for everyone to see. This makes it a perfect solution to get all the details about a website, including data and graphical details.
How it Works
Archive.is archives a website on demand or according to the frequency of the activities on a particular website. It will take both screenshot and code of a website while archiving. However, unlike Wayback Machine it doesn’t sends crawlers to archive web pages. This means a website can’t stop Archive.is from archiving using a robot.txt file.
If there is a website that may be blocking Wayback Machine from crawling its site, then you should opt for Archive.is to get a peek.
Practical Use
The website of Archive.is is not nearly as attractive as Wayback Machine or Screenshots. Although, it is quite simple to navigate with least options to worry about. On the main page, you will find two search bars, one in red at the top and other in blue at the bottom. Red search bar is where you can demand archiving of a web page, and in the blue, you can check the history of any website.
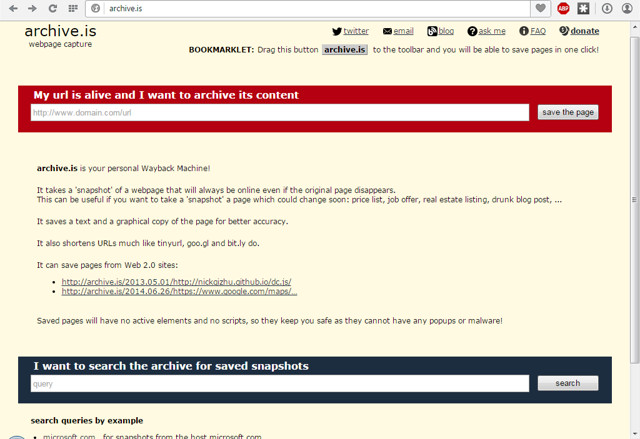
Demand Archive
In the red search bar, you can demand archiving of any website and Archive.is will copy code and take a screenshot of it. Just enter the URL of the website page in the search bar, and click on “save the page”.
Archive.is will start processing and after a short delay (depending on the page size), you will see the archived page and a screenshot of it.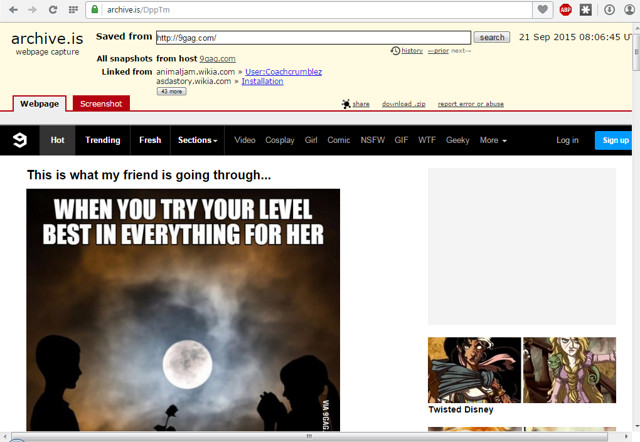
Note: You are not limited to just adding Landing page URL of a particular website, you can add URL of any page of a website. Just access the page you want to archive and copy/paste its URL in the archive.is search, it will be archived.
Check Archived History of a Website
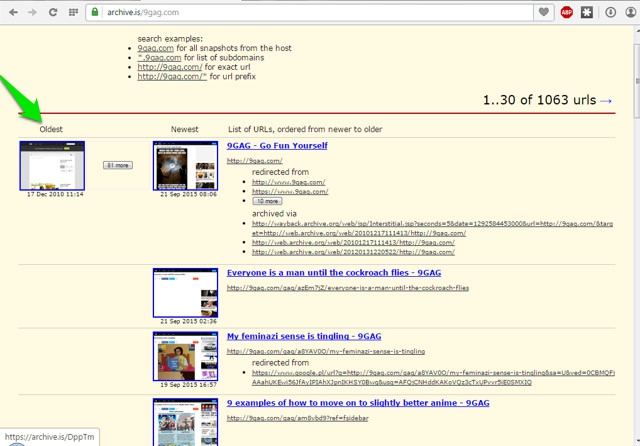
In the blue search bar below, you can enter the URL of a website, and you will see all its history. There will be two options, Oldest and Newest. Oldest just contains the oldest archived web page, and Newest contains the latest archived pages and going back from there.
You will see all the archived pages, starting from the latest and going backwards along with the data mentioned below each web page. You can just click on any webpage to see its details.
The archived web page will open up and you can easily scroll between it. You can click on “Screenshot” to see a screenshot of that particular web page.
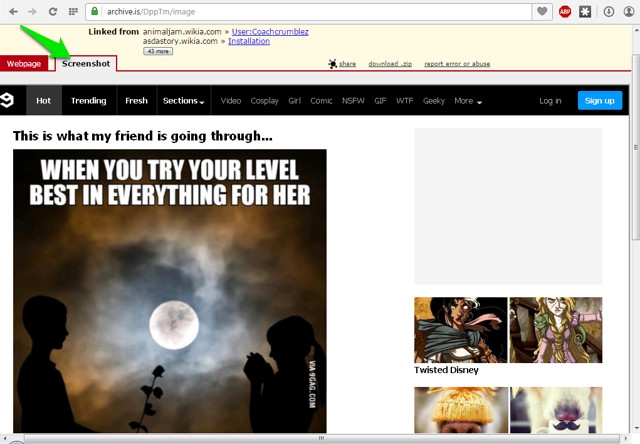
You can also share the web page over social networks by clicking on “share”. The web page can also be downloaded for future reference, just click on “Download” to download the results.
In our results, Screenshots archived 9gag 21 times and on the other hand, Archive.is archived it 1063 times. You can weigh the frequency of archiving website with this little example.
Key Features: Archives both code and screenshot of a web page, huge database, share & download results, and request for archiving of any website any time.
Cons: Unattractive interface, hard to navigate to reach the required web page and doesn’t provide much information about a particular web page.
SEE ALSO: 40 Cool And Interesting Websites
Индексация веб-страниц в интернете
Начиная с 1996 года по настоящее время на сайте archive.org собрано более 466 миллиардов веб-страниц (эта цифра все время увеличивается). Архив страниц интернета создан для сохранения, ознакомления и изучения имеющей информации, которая накопилась за все эти годы во всемирной сети.
Время от времени, специальные роботы, принадлежащие сервису, индексируют содержание практически всех сайтов в интернете
Следует принять во внимание, что во время обхода робота для индексации сайтов, на некоторых сайтах могли возникать внутренние проблемы: сайт, или некоторые страницы сайта были недоступны, сайт находился на техобслуживании, не работали подключаемые внешние элементы и т. д
Поэтому некоторые архивы сайтов будут полными, а некоторые снимки (архивы) могут содержать только частичную информацию. Имейте в виду, что некоторые сайты индексируются часто, другие сайты, наоборот, довольно редко.
Для просмотра веб-страниц используется онлайн сервис The Wayback Machine. В Internet Archive доступны для просмотра не только действующие в настоящий момент сайты, но и сайты, которые уже не существуют. С помощью архива интернета можно побывать на прекративших существование сайтах, и ознакомится с содержимым веб-страниц удаленных сайтов.
Благодаря замечательному архиву сайтов интернета можно проследить историю изменений, как изменялся внешний облик сайта и его содержимое с течением времени, использовать архивы для восстановления сайта, искать необходимую информацию.
На главной странице сайта archive.org можно получить доступ к архивным данным, которые сгруппированы в тематические разделы, или сразу перейти на страницу сервиса Wayback Machine.

Screenshot History for Any Website – Screenshots.com
The first internet Wayback machine alternative which makes our list is Screenshots. This internet archive website takes the screenshot of any website and saves it in a database that allows users to access the cached copy of that website in future. The website claims to have 250 million historical website screenshots.
It will provide you complete information about the website you searched for within a few minutes. All you have to do is enter the URL of the website which you want to check in the Search field and hit on the Search button.
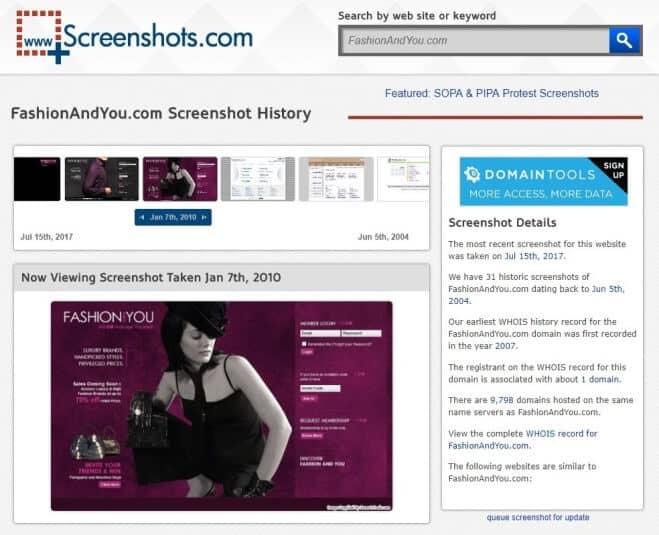
The results will show you two screenshots out of which one will show you the current state of the website and another one will show you how the website looked a while ago. If a website is updated multiple times, Screenshots is going to display multiple variations of the same. This site uses the Whois database of DomainTools to find the websites to archive.
When it comes to the matters of archived screenshots of any website or webpages then Screenshots.com is the most appropriate Internet Archive Wayback Machine alternative site.
You might also like: Top 10 Best uTorrent Alternatives to Download Movies Free
web.archive.org


В самом верху написано, сколько всего снимком страницы сделано, дата первого и последнего снимка.
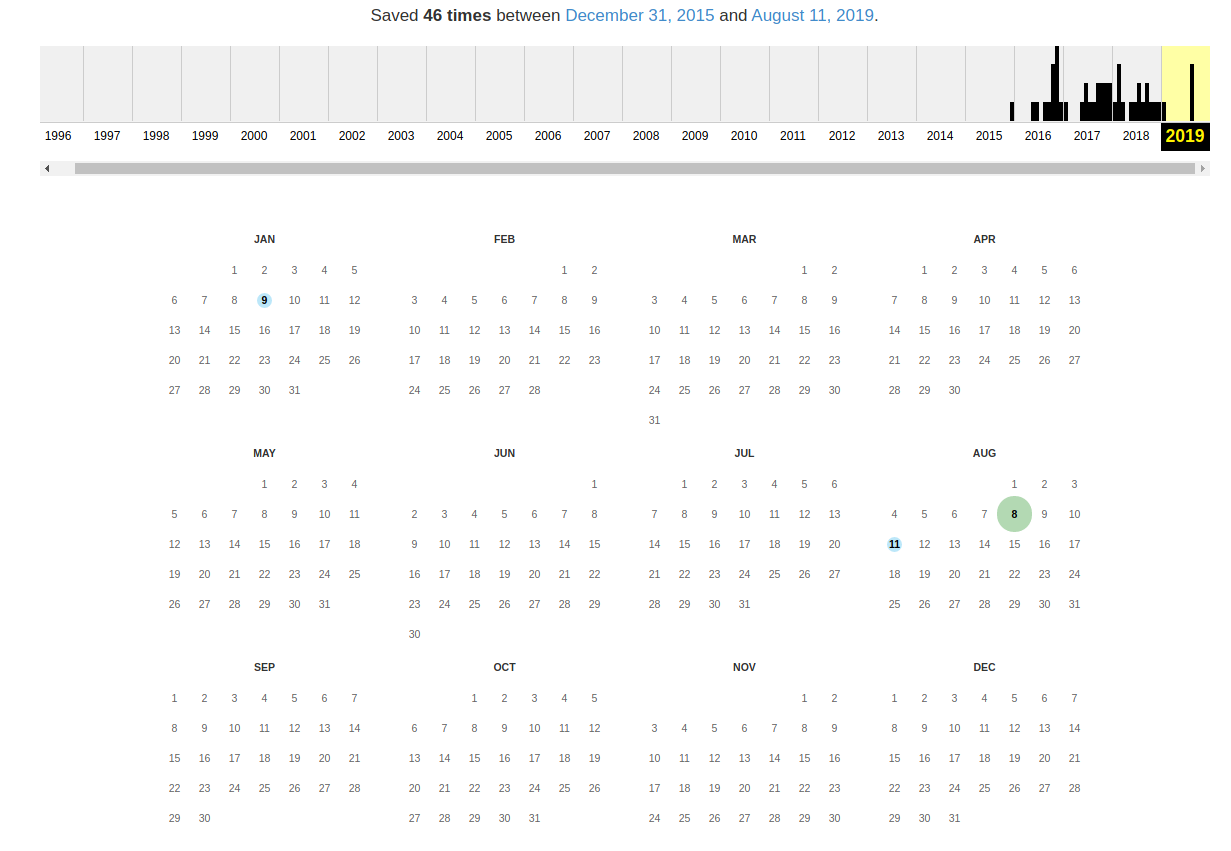
Затем идёт шкала времени на которой можно выбрать интересующий год, при выборе года, будет обновляться календарь.
Обратите внимание, что календарь показывает не количество изменений на сайте, а количество раз, когда был сделан архив страницы.
Точки на календаре означают разные события, разные цвета несут разный смысл о веб захвате. Голубой означает, что при архивации страницы от веб-сервера был получен код ответа 2nn (всё хорошо); зелёный означает, что архиватор получил статус 3nn (перенаправление); оранжевый означает, что получен статус 4nn (ошибка на стороне клиента, например, страница не найдена), а красный означает, что при архивации получена ошибка 5nn (проблемы на сервере). Вероятно, чаще всего вас должны интересовать голубые и зелёные точки и ссылки.


Используя эту миниатюру вы сможете переходить к следующему снимку страницы, либо перепрыгнуть к нужной дате:
Кроме календаря доступна следующие страницы:
- Collections — коллекции. Доступны как дополнительные функции для зарегистрированных пользователей и по подписке
- Changes
- Summary
- Site Map
Changes
«Changes» — это инструмент, который вы можете использовать для идентификации и отображения изменений в содержимом заархивированных URL.
Начать вы можете с того, что выберите два различных дня какого-то URL. Для этого кликните на соответствующие точки:
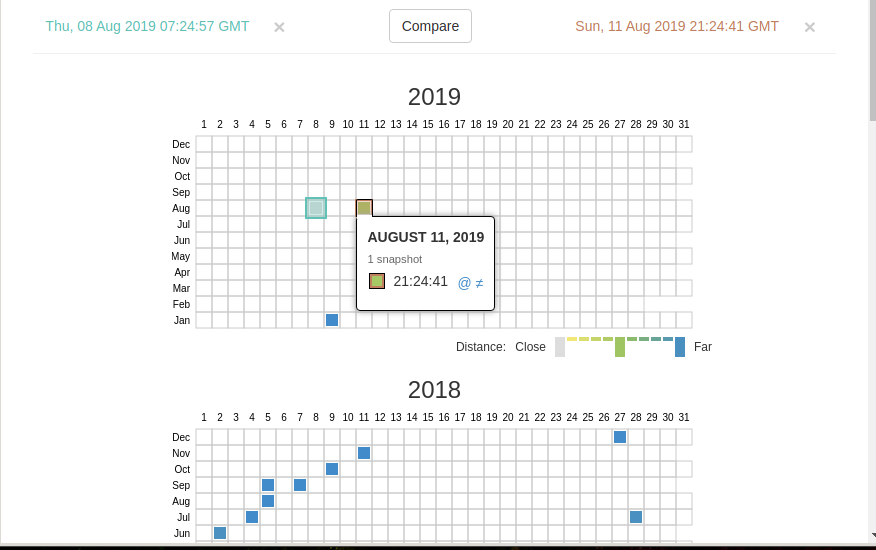
И нажмите кнопку Compare. В результате будут показаны два варианта страницы. Жёлтый цвет показывает удалённый контент, а голубой цвет показывает добавленный контент.
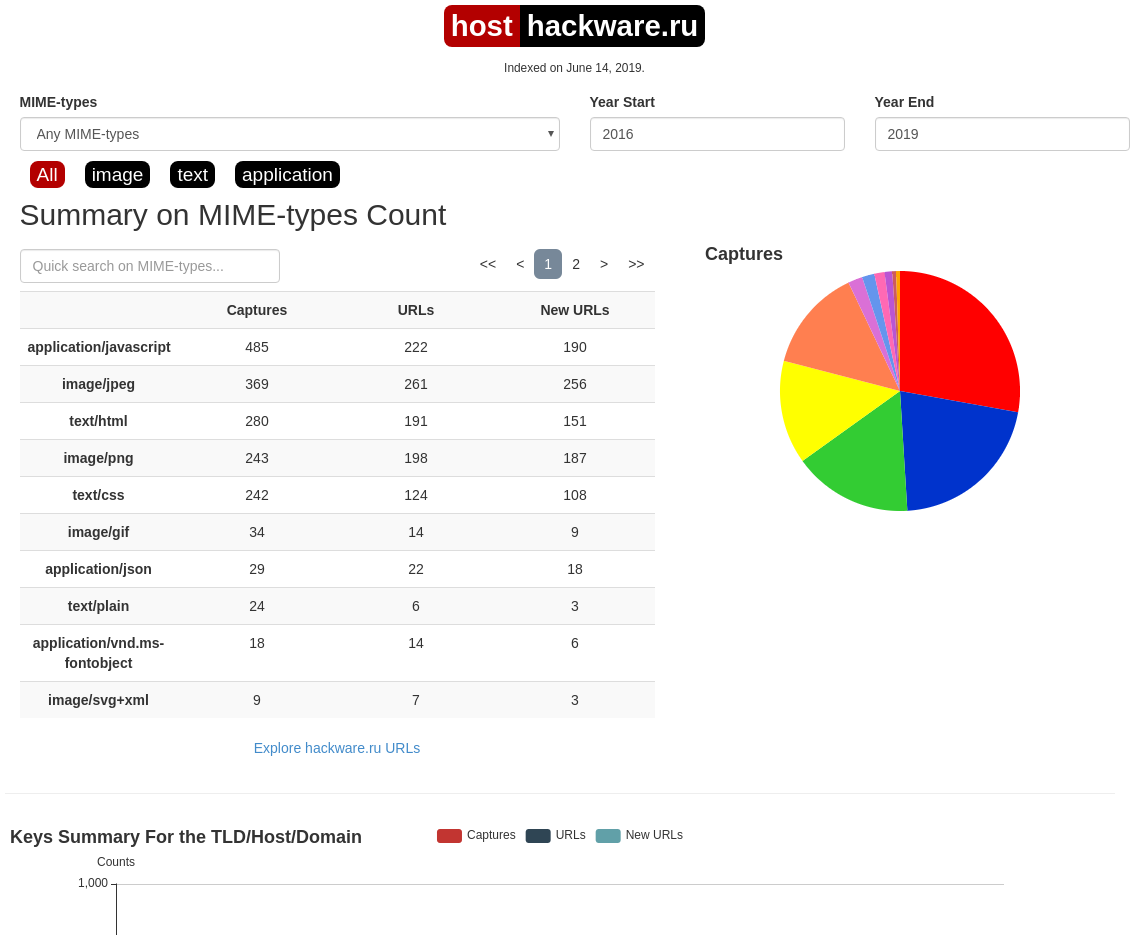
В этой вкладке статистика о количестве изменений MIME-типов.
Site Map
Как следует из название, здесь показывается диаграмма карты сайта, используя которую вы можете перейти к архиву интересующей вас страницы.
Если вместо адреса страницы вы введёте что-то другое, то будет выполнен поиск по архивированным сайтам:

Показ страницы на определённую дату
Кроме использования календаря для перехода к нужной дате, вы можете просмотреть страницу на нужную дату используя ссылку следующего вида: http://web.archive.org/web/ГГГГММДДЧЧММСС/АДРЕС_СТРАНИЦЫ/
Обратите внимание, что в строке ГГГГММДДЧЧММСС можно пропустить любое количество конечных цифр.
Если на нужную дату не найдена архивная копия, то будет показана версия на ближайшую имеющуюся дату.
Возможности использования веб-архивов
Возможности сохраненной истории
Теперь каждый знает, что такое веб-архив, какие сайты предоставляют услуги сохранения копий проектов. Но многие до сих пор не понимают, как использовать представленную информацию. Возможности архивных данных выражаются в следующем:
- Выбор доменного имени. Не секрет, что многие веб-мастера используют уже прокачанные домены. Стоит понимать, что опытные юзеры отслеживают не только целевые параметры, но и историю предыдущего использования. Каждый пользователь сети желает знать, что приобретает: имелись ли ранее запреты или санкции, не попадал ли проект под фильтры.
- Восстановление сайта из архивов. Иногда случается беда, которая ставит под угрозу существование собственного проекта. Отсутствие своевременных бэкапов в профиле хостинга и случайная ошибка может привести к трагедии. Если подобное произошло, не стоит расстраиваться, ведь можно воспользоваться веб-архивом. О процессе восстановления поговорим ниже.
- Поиск уникального контента. Ежедневно на просторах интернета умирают сайты, которые наполнены контентом. Это случается с особым постоянством, из-за чего теряется огромный поток информации. Со временем такие страницы выпадают из индекса, и находчивый веб-мастер может позаимствовать информацию на личный проект. Конечно, существует проблема с поиском, но это вторичная забота.
Мы рассмотрели основные возможности, которые предоставляют веб-архивы, самое время перейти к более подробному изучению отдельных элементов.
Восстанавливаем сайт из веб-архива
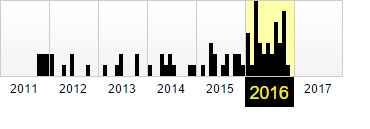 Фиксация в веб-архиве за 2011–2016 годы
Фиксация в веб-архиве за 2011–2016 годы
Никто не застрахован от проблем с сайтами. Большинство их них решается с использованием бэкапов. Но что делать, если сохраненной копии на сервере хостинга нет? Воспользоваться веб-архивом. Для этого следует:
- Зайти на специализированный ресурс, о которых мы говорили ранее.
- Внести собственное доменное имя в строку поиска и открыть проект в новом окне.
- Выбрать наиболее удачный снимок, который располагается ближе к проблемной дате и имеет полноценный вид.
- Исправить внутренние ссылки на прямые. Для этого используем ссылку «http://web.archive.org/web/любой_порядковый_номер_id_/Название сайта».
- Скопировать потерянную информацию или данные дизайна, которые будут применены для восстановления.
Заметим, что процесс несколько утомительный, с учетом скорости работы архива. Поэтому рекомендуем владельцам больших веб-ресурсов чаще выполнять бэкапы, что сохранит время и нервы.
Ищем уникальный контент для собственного сайта
 Уникальный контент из веб-архива
Уникальный контент из веб-архива
Некоторые веб-мастера используют интересный способ получения нового, никому не нужного контента. Ежедневно сотни сайтов уходят в небытие, а вместе с ними теряется информация. Чтобы стать владельцем контента, нужно выполнить следующее:
- Внести URLв строку поиска.
- На сайте аукциона доменных имен скачать файлы с именем ru.
- Открыть полученные файлы с использованием excel и начать отбор по параметру наличия проектной информации.
- Найденные в списке проекты ввести на странице поиска веб-архива.
- Открыть снимок и получить доступ к информационному потоку.
Рекомендуем отслеживать контент на наличие плагиата, это позволит найти действительно достойные тексты. А на этом все! Теперь каждый знает о возможностях и методах использования веб-архива. Используйте знание с умом и выгодой.
Как проверять полученные статьи на уникальность
Есть несколько способов проверки статей на уникальность и наверное многие из них вам известны. Тем не мене здесь мы приведем лучшие способы проверки контента на уникальность.
- Проверка статей с использованием специализированных сервисов типа etxt.ru, text.ru или адвего. Данный способ подходит когда нужно проверить одну или две статьи, так как проверка занимает длительное время и существуют ограничения по количеству проверок в день с конкретного IP адреса.
- Если вам не жалко немного денег, то для ускорения процесса можно использовать пакетную проверку статей предоставляемую такими сервисами.
- Использовать специализированное программное обеспечение для проверки уникальности статей типа Advego Plagiatus.

Программа для проверки уникальности статей из Вебархива
После чего открываем программу и загружаем наши статьи для пакетной проверки используйте меню программы: «Операции -> Пакетная проверка».

Настройка программы для проверки уникальных статей из вебархива
Если у вас отсутствует необходимость проверять много статей, то просто включите отображение каптчи и вводите ее вручную.
На этом пожалуй все. Мы рассмотрели как можно получить множество уникальных статей абсолютно бесплатно. Желаем вам удачи !
Ссылки используемые в статье
- 1. web.archive.org – интернет архив веб сайтов
- 2. Web Arhcive Downloder – это уникальная программа для сохранения сайтов из интернет архива.
Итак, приступим:
Шаг 1. Установите UnHackMe (1 минута).
- Скачали софт, желательно последней версии. И не надо искать на всяких развалах, вполне возможно там вы нарветесь на пиратскую версию с вшитым очередным мусором. Оно вам надо? Идите на сайт производителя, тем более там есть бесплатный триал. Запустите установку программы.
Затем следует принять лицензионное соглашение.
И наконец указать папку для установки. На этом процесс инсталляции можно считать завершенным.
Шаг 2. Запустите поиск вредоносных программ в UnHackMe (1 минута).
- Итак, запускаем UnHackMe, и сразу стартуем тестирование, можно использовать быстрое, за 1 минуту. Но если время есть — рекомендую расширенное онлайн тестирование с использованием VirusTotal — это повысит вероятность обнаружения не только перенаправления на WAYBACK MACHINE, но и остальной нечисти.
Мы увидим как начался процесс сканирования.
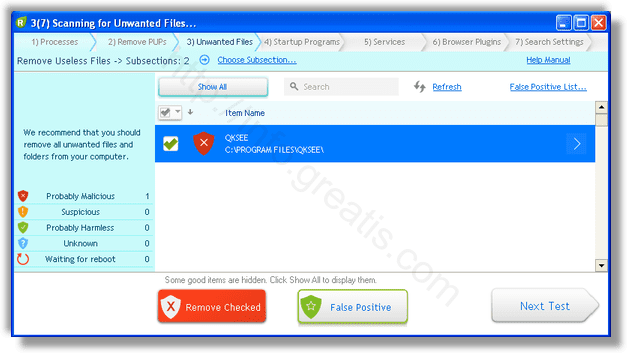
Шаг 3. Удалите вредоносные программы (3 минуты).
- Обнаруживаем что-то на очередном этапе. UnHackMe отличается тем, что показывает вообще все, и очень плохое, и подозрительное, и даже хорошее. Не будьте обезьяной с гранатой! Не уверены в объектах из разряда “подозрительный” или “нейтральный” — не трогайте их. А вот в опасное лучше поверить. Итак, нашли опасный элемент, он будет подсвечен красным. Что делаем, как думаете? Правильно — убить! Ну или в английской версии — Remove Checked. В общем, жмем красную кнопку.
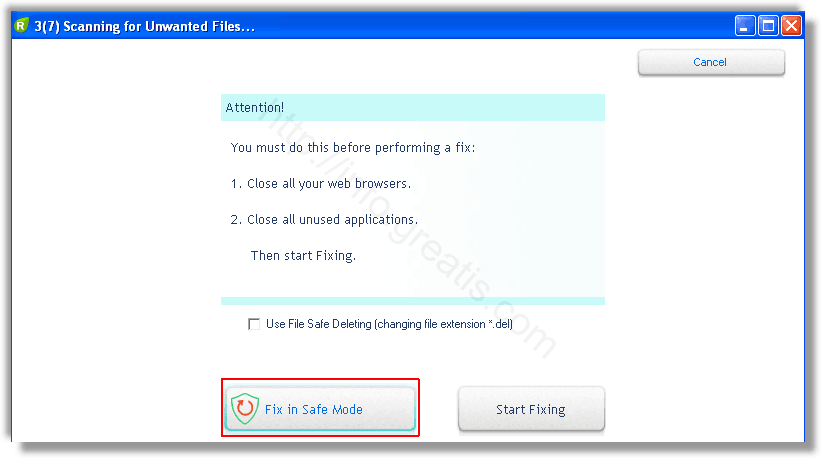
После этого вам возможно будет предложено подтверждение. И приглашение закрыть все браузеры. Стоит прислушаться, это поможет.
В случае, если понадобится удалить файл, или каталог, пожалуй лучше использовать опцию удаления в безопасном режиме. Да, понадобится перезагрузка, но это быстрее, чем начинать все сначала, поверьте.
Ну и в конце вы увидите результаты сканирования и лечения.
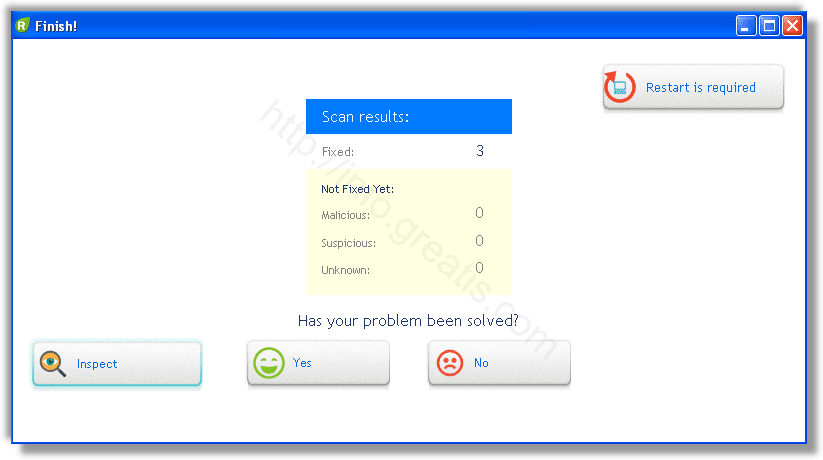
Итак, как вы наверное заметили, автоматизированное лечение значительно быстрее и проще! Лично у меня избавление от перенаправителя на WAYBACK MACHINE заняло 5 минут! Поэтому я настоятельно рекомендую использовать UnHackMe для лечения вашего компьютера от любых нежелательных программ!
Восстановление сайта с помощью «Archivarix»
После выбора наиболее приемлемого тарифного плана можно приступить к самому главному, именно — восстановлению некогда преданного забвению веб-ресурса.
Кроме того, «Архиварикс» может скачивать и восстанавливать не только сайт из Веб Архива, но и тех. которые на момент скачивания являются рабочими — находятся в режиме онлайн, именно это и есть ключевое отличие данного сервиса от всевозможных «парсеров», а также различного рода «качалок».
Главная задача «Архиварикса» состоит в восстановлении полностью функциональной и работоспособной версии сайта, дабы тот мог полноценно использоваться на сервере пользователя.
Archivarix
Приступим к обзору первого модуля, отвечающего за восстановление сайта из Архива. Чтобы воспользоваться им, необходимо перейти по адресу: https://ru.archivarix.com/
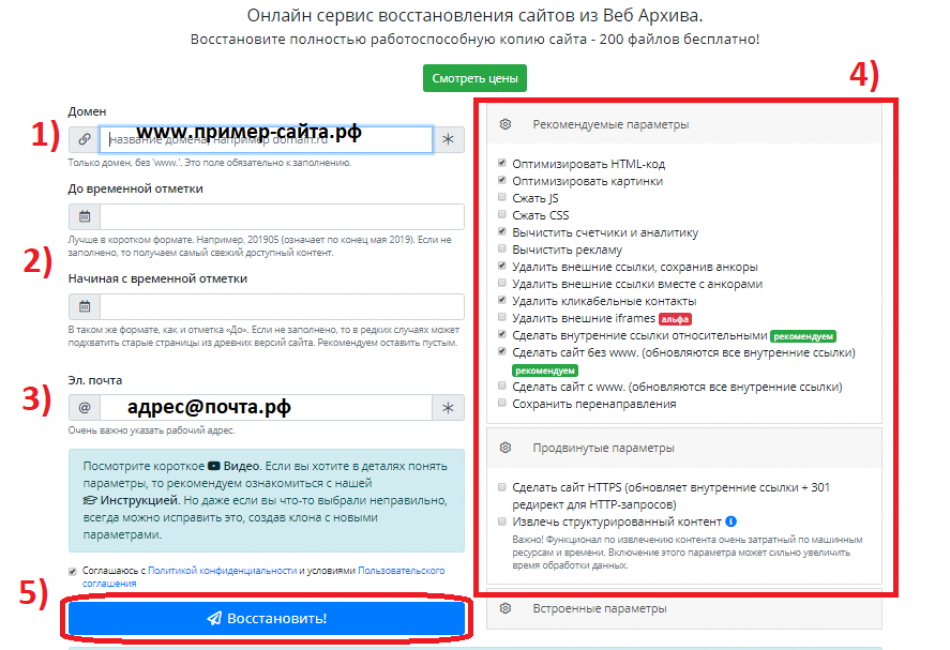
Далее необходимо заполнить все пункты, находящиеся на странице.
А именно:
- Вспомнить и ввести корректное название доменного имени, например: «пример-сайта.рф».
- Выбрать актуальную версию сайта, указав необходимую дату «до определенной временной отметки» или наоборот, «начиная с определенной временной отметки». Если оставить данный пункт незаполненным, то пользователь получить наиболее актуальную версию веб-сайта.
- В третьей строке необходимо указать действующий и рабочий адрес электронной почты, на который впоследствии придет важная информация — уведомление и ссылка на скачивание архива.
- Для продвинутых пользователей была предусмотрены опции «Рекомендуемые/Продвинутые/Встроенные параметры», благодаря которым можно произвести тонкую настройку различных параметров.
- Нажимаем клавишу «Восстановить», разобравшись предварительно со всеми предыдущими пунктами и параметрами.
После этого система займется сбором и упорядочиванием всей необходимой информации и компонентов сайта, после этого «Архиварикс» сформирует письмо, в котором будет детально указан результат анализа полученных данных: размер сайта, количество файлов, типы данных в фактическом и процентном соотношении.
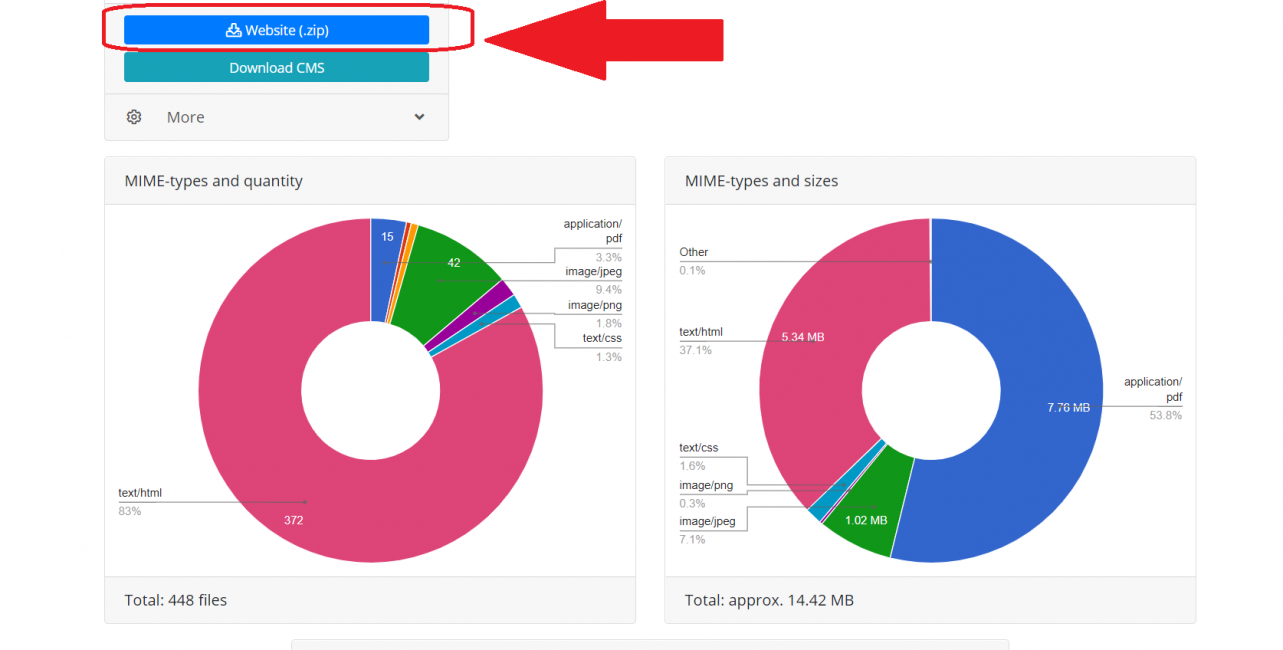
Информация о сайте, собранная Архивариксом
Чтобы скачать восстановленную копию сайта в zip-архиве — необходимо нажать на кнопку «Website (.zip)», расположенную в верхнем левом углу (как показано на скриншоте выше).
Archive-It
Do you or your organization have a website that needs to be indexed and archived frequently? If so, manually archiving each individual web page using the methods above can be incredibly tedious and costly. Fortunately, the Internet Archive provides a service called Archive-It that can automate the archiving process for you.
This service is not free; however, it can be ideal for those who want to back up their content with a “set it and forget it” mentality. Just stipulate which pages you would like to save and how often. This paid subscription is perfect for those who wish to save their web content on a regular basis.
Do you use the Wayback Machine? If so, do you visit it purely for fun or do you find it a useful tool? Are there other ways to back up content on the Web? Let us know in the comments!
Conclusion
So, these are some of the most popular and best Internet Wayback Machine alternatives of 2020 which you can use to see history and statistics of any website.
We hope this Wayback Machine alternative guide has answered all your questions like – how to find archived versions of websites? What are the best ways to view archived versions of web pages? how to access archived versions of websites?
Undoubtedly, the Internet Archive Wayback Machine is the best web archiving service that allows people to see archived versions of web pages across time. But these similar sites like Archive.org and alternative to Wayback Machine are awesome too.
Let us know using the comments section below – Which Internet Archive Wayback alternative are you using to browse an old version of a website or revisit old website data.
Did you like this list of top 10 best Internet Archive Wayback Machine alternative sites 2020? If yes, feel free to share it with your friends on social media networks like Facebook, Twitter, and Google Plus, etc.
You may also be interested in checking out:
- Top 10 Best PayPal Alternatives for Making Online Payments
- Top 8 HootSuite Alternatives for Social Media Management
- Top 10 Best Taboola Alternatives to Monetize Your Site
- Top 6 ZbigZ Alternatives for High-Speed Torrent Downloads
- Top 20 Google Keyword Planner Alternatives for Keyword Research
Как найти уникальный контент для своего сайта
Часто возникают ситуации, когда проекты по различным причинам закрывают, удаляя сайт с хостинга. При этом на таком ресурсе могут сохраняться полезные и интересные статьи. Через некоторое время они перестают индексироваться поисковыми системами и текст статей становится уникальным. Для владельцев информационных сайтов подобные статьи на нужную тематику представляют интерес.
Такой контент можно добавлять на собственный проект без угрозы каких-либо санкций со стороны поисковых систем, поскольку для них основное значение имеет уникальность контента на текущий момент, а не его первоисточник. Чтобы найти подходящие статьи, сэкономив время и деньги необходимые на создание собственного контента, нужно предварительно узнать список доменов, которые освободились в последнее время.
Зайдем в раздел продающихся доменов на сервисе Reg.ru, выберем категорию, совпадающую с тематикой собственного проекта, например, здоровье:
Далее выбираем подкатегорию или просматриваем все предложенные домены, выбирая из них варианты для дальнейшего анализа в веб-архиве:
После того как подходящие статьи найдены в веб-архиве необходимо проверить их на уникальность с помощью сервисов антиплагиата, например, text.ru. Если контент уникален, опубликуйте его на собственном сайте.
Как избавиться от рекламы WAYBACK MACHINE в Chrome/Firefox/Internet Explorer/Edge?
Я на этом деле конечно уже собаку съел, так что трудностей не возникло. Но прежде, чем закидывать вас инструкциями, давайте повторим сами себе, с чем имеем дело.
Это обычный рекламный вирус, коих стало пруд пруди. И имен у него много: может быть просто WAYBACK MACHINE, а может с дописанной строкой после имени домена WAYBACK MACHINE. В любом случае вирус закидывает вас рекламой, и про ваше любимое казино Вулкан не забывает. До кучи он заражает и свойства ярлыков браузеров.
Кроме того, вирус обожает создавать расписания для запуска самого себя, чтоб жизнь медом не казалась. В результате его деятельности вы вполне можете случайно кликнуть на нежелательную ссылку и скачать себе что-нибудь более серьезное.
Поэтому данный рекламный вирус следует удалять как можно быстрее. Ниже я приведу инструкции по избавлению от вируса WAYBACK MACHINE, но рекомендую использовать автоматизированный вариант.
Which Sites Are Cataloged?
Many popular websites are automatically archived by the Wayback Machine. However, you can use the Wayback Machine to manually archive virtually any page. Websites are often abandoned or changed completely, so the Wayback machine acts as a way to preserve the culture of the Internet by keeping a digital “hard copy” of a website. Be aware that text and images are left intact; however, some outbound links and embedded items (e.g. videos) are not.
It is important to note that The Wayback Machine only scans and archives public sites. This means that password protected sites or ones located on private servers cannot be archived. In addition, if a website prohibits search engines from including it in search results, Wayback Machine will not be able to archive it.
