9 способов найти удаленный сайт или страницу
Содержание:
- Всемирный веб архив сайтов интернета
- В наши дни создатель первого сайта выступает за свободный интернет
- [править] Примеры
- Как проверять полученные статьи на уникальность
- История создания и разработки веб-сайтов
- Как сделать качественный сателлит?
- Виды сателлитов
- Как добавить копию страницы в web archive
- Carbon-Neutralize the Approach
- Стремительное развитие интернета во всем мире
- Создание веб-страниц
- Переделка сайта
- archive.md
- Celebrate the Internet Archive’s 25th Anniversary!
- Возможности использования веб-архивов
- Как найти уникальный контент для своего сайта
- Поиск сайтов в Wayback Machine
- Зачем был придуман первый веб-сайт
- Все про archive.org: как пользоваться сервисом и как достать сайт из веб-архива
Всемирный веб архив сайтов интернета
Хранилище интернет-архив конечно не содержит всех страниц, которые когда-либо были созданы. Но шанс найти интересующий вас сайт и его архивную копию достаточно велик.
Самый мощный архив веб-сайтов доступен на Archive.org по адресу www.archive.org. Он индексирует веб, виде-, аудио и текстовые материалы, которые доступны в интернете.
Запустите ваш любимый веб-браузер и введите www.archive.org в адресной строке . Через некоторое время вы увидите главную страницу сайта интернет-архива. Она разделена на несколько частей. Каждая часть позволяет искать различный тип контента.
Раздел видео, содержит на момент написания статьи более 830 тысяч фильмов.
Раздел аудио, включает в себя более 2 миллионов записей, при это доступен еще раздел живой музыки, который насчитывает около 200 тысяч прямых трансляций с концертов в Интернет.
Однако наиболее интересным и значимым разделом сайта Archive.org является раздел web-страницы. На сегодняшний день он позволяет получить доступ к более чем 349 миллиардам архивных веб-сайтов. Для данного раздела даже выделен отдельный поддомен web.
В наши дни создатель первого сайта выступает за свободный интернет
 Бернерс Ли выступает за реорганизацию интернета.
Бернерс Ли выступает за реорганизацию интернета.
Сегодня Бернерс Ли активно выступает за открытость интернета. К локализации персональных данных пользователей своей страны и идеям суверенного интернета он относится скептически.
Тим говорит, что любое разделение сети на сегменты — очень плохая идея. Причина бурного развития Веба заключалась в том, что интернет был негосударственным, открытым и общедоступным.
Бернерс Ли призывает все страны быть очень осторожными в попытках подчинить себе мировую паутину.
Интернет должен остаться свободным.
Это отдельный мир, со своими законами и правилами, который каждый день помогает и развлекает нас уже более 25 лет, но все еще далек от совершенства. Развивайся, интернет.
![]()
iPhones.ru
Недавно этому сайту исполнилось 28 лет, и его создатель все еще жив.
[править] Примеры
Роскомнаха банит архивы интернета (Блюстители)
- web.archive.org — старейший веб-архив, сохраняющий копии сайтов с 1996 года в автоматическом режиме в определённые промежутки времени. Имеет юридический статус библиотеки, является некоммерческой организацией. Сайт обладает несколькими зеркалами. На 25 июня 2015 года был внесён в реестр запрещённых сайтов и заблокирован на территории РФ за страницу «Одиночный Джихад» (а ещё ранее — за страницу с видеороликом «Звон мечей» террористической группировки ИГИЛ, запрещённой в РФ). В начале июля доступ к сайту был возозбновлён в связи с переносом материала в отдельный архив, доступный для закачки. Позже снова заблокирован, но по состоянию на 2020 год уже удалён из реестра.
- peeep.us — совмещенный с сокращателем ссылок сайт, позволяющий сохранять страницы самим пользователям. Создаёт зеркало страницы на фиксированный момент времени, который отображается вверху жёлтой полосой, с сокращённым URL-адресом. В отличие от веб-архива, щёлкая по ссылкам, открываются веб-страницы на текущий момент времени, а не в архиве. В отличие от archive.is, может сохранять страницы, для просмотра которые видны только сохраняющему, но не остальным людям. Не сохраняет картинки и фреймы. На 25 июня 2015 года был внесён в реестр запрещённых сайтов и заблокирован на территории РФ, позднее вообще перестал открываться. На июль 2015 года на месте сайта выдаётся ошибка 404. Был разблокирован в начале сентября 2015 года.
- archive.is — сайт, аналогичный peeep.us. Отличается тем, что сохраняет не только основной html-файл страницы, но также и все картинки, стили, фреймы и фонты. Также умеет сохранять страницы с Web2.0-сайтов, например с twitter.com.
Также в роли веб-архивов выступают кеши поисковых систем, но в отличие от первых, они ненадёжны, поскольку могут быстро удаляться. Наибольший срок хранения страниц замечен за Яндексом.
В викисреде
Роль веб-архивов могут выполнять отдельные разделы сайтов, которые сами по себе ими не являются:
Копипаста Луркоморья — сборник заинтересовавших пользователей Луркоморья текстов со страниц Интернета или взятые из книжных источников.
Архивы Викиреальности — сохраняет заслуживающие внимание страницы и творчество, связанное с викисредой. Для архивов выделено специальное пространство имён.
Авторские проекты в Традиции (например, творчество АПЭ, Погребного и т. п.) — сборник творчества различных авторов, которое (в большинстве своём) ранее где-то выкладывалось.
Как проверять полученные статьи на уникальность
Есть несколько способов проверки статей на уникальность и наверное многие из них вам известны. Тем не мене здесь мы приведем лучшие способы проверки контента на уникальность.
- Проверка статей с использованием специализированных сервисов типа etxt.ru, text.ru или адвего. Данный способ подходит когда нужно проверить одну или две статьи, так как проверка занимает длительное время и существуют ограничения по количеству проверок в день с конкретного IP адреса.
- Если вам не жалко немного денег, то для ускорения процесса можно использовать пакетную проверку статей предоставляемую такими сервисами.
- Использовать специализированное программное обеспечение для проверки уникальности статей типа Advego Plagiatus.

Программа для проверки уникальности статей из Вебархива
После чего открываем программу и загружаем наши статьи для пакетной проверки используйте меню программы: «Операции -> Пакетная проверка».

Настройка программы для проверки уникальных статей из вебархива
Если у вас отсутствует необходимость проверять много статей, то просто включите отображение каптчи и вводите ее вручную.
На этом пожалуй все. Мы рассмотрели как можно получить множество уникальных статей абсолютно бесплатно. Желаем вам удачи !
Ссылки используемые в статье
- 1. web.archive.org – интернет архив веб сайтов
- 2. Web Arhcive Downloder – это уникальная программа для сохранения сайтов из интернет архива.
История создания и разработки веб-сайтов
Создателем первого в мире электронного ресурса является ученый Европейской лаборатории элементарных частиц Тим Бернерс-Ли. Именно им в декабре 1990 был разработан первый веб-браузер, который носил название World Wide Web. Сервер был основан на базе NeXTcube.
Правда, еще в сороковые годы ученый Ваннервар (Вэнивар) Буш развивал теорию о том, что с помощью специальных технических устройств можно расширить память человека, проиндексировав информацию, накопленную годами. По мнению ученого, путем проведения такой индексации можно было бы быстро найти необходимую информацию.
9 августа 1991 года появился первый онлайн-ресурс. При создании сайта была использована технология World Wide Web (WWW) и протокол передачи данных Hyper Text Transfer Protocol (HTTP), разработанный с помощью системы адресации Uniform Resource Identifier на языке программировании Hyper Text Markup Language (HTML).
На страницах первого интернет-ресурса были размещены настройки установки и работы браузеров и серверов. Ученый Тим Бернерс-Ли был уверен в том, что гипертекст может быть базой для сетей обмена данных. Свой первый проект Enquire (– гипертекстовое программное обеспечение) Тим Бернерс-Ли разработал в 1980 году.

Стандарт WWW был утвержден в мае 1991 года членами Европейского Центра ядерных исследований в Женеве (CERN). Спецификации HTTP, HTML, URI утверждены были в 1993 году. В 1993 году World Wide Web стала официально бесплатной и свободной для всего мира.
Как сделать качественный сателлит?
Если вы все же решили попробовать этот метод поискового продвижения, вот несколько правил, которые помогут создать хороший сайт-сателлит и избежать санкций со стороны Яндекса и Google.
Желательно разместить сателлит на хостинге, отличном от продвигаемого сайта, и использовать другую CMS
Владелец домена нового сайта должен отличаться от продвигаемого
Использовать новые контактные данные
В панелях вебмастеров использовать другие аккаунты
Шаблон и структура на сателлитах должны отличаться от шаблона и структуры продвигаемого сайта
Обязательно использовать оригинальный и качественный контент (ниже несколько способов получить его)
Важно, чтобы тематика вспомогательного сайта была релевантна тематике ключевого проекта
Желательно, чтобы ссылочная масса не повторялась с ссылочной массой основного ресурса
Устранить основные технические ошибки на новом сайте, если они есть
Оптимизировать и развивать сайты
Виды сателлитов
У сайтов-спутников много разных классификаций. Давайте рассмотрим самые важные и интересные.
Первая классификация — по способу наполнения сайта. В зависимости от того, насколько основательно вы подошли к построению сайта и как часто обновляете на нем информацию, есть:
- Динамические: качественные проекты с обновляемым контентом, выполненные на популярных CMS.
- Статические: обычно создаются на готовых шаблонах без сложной структуры, наполнение таких сайтов не меняется.
- Дорвеи: их цель – перевод поискового трафика на другой сайт, поэтому такие сайты не обладают значимым контентом совсем.

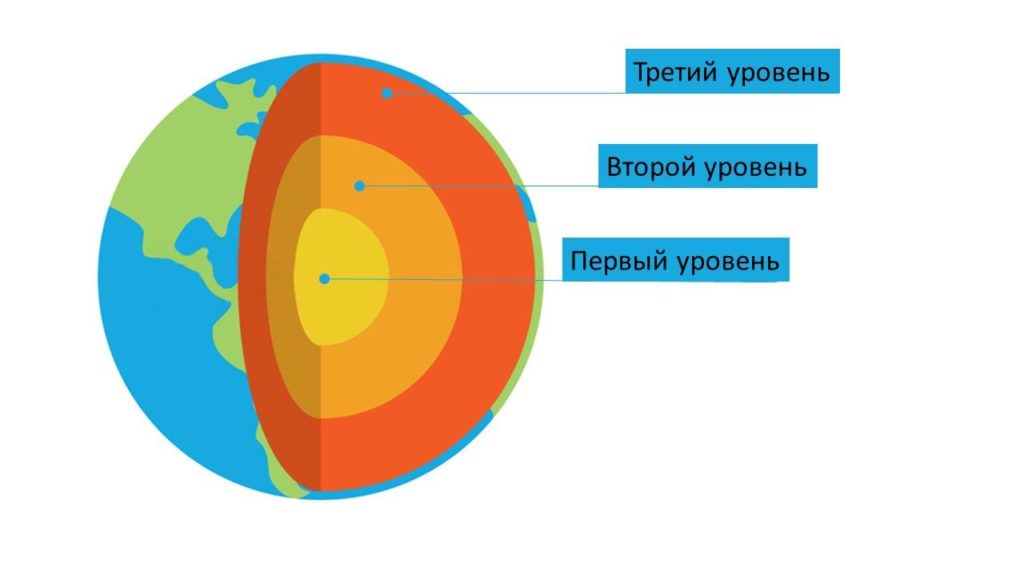
Вторая классификация – по степени развития сайта. Актуальна для схемы трехуровневой сателлитовой сети. Суть в том, что сателлиты третьего уровня продвигают сайты второго уровня, а последние влияют на ресурсы первого уровня.
Подробнее о каждом:
- Третий уровень: используются рискованные методы продвижения, рассчитанные на скорость, а не на стойкий результат. Имеют неуникальный контент и большое количество некачественных внешних ссылок.
- Второй уровень: для этих сайтов используются уже менее агрессивные способы оптимизации. Контент для таких сателлитов все еще не эталонного качества, но обладает уже гораздо большей уникальностью.
- Первый уровень: продвижение этих сайтов похоже на продвижение ключевого проекта. Для них создается качественный контент, структура. Они имеют поисковый трафик сравнимый с основным сайтом.
Как добавить копию страницы в web archive
Чтобы не дожидаться, пока бот найдёт и сохранит нужную вам страницу, можете добавить её вручную.
Если используете сайт, перейдите в специальный подраздел. Вставьте ссылку на сохраняемую страницу и нажмите Save Page. Отметьте пункт Save error pages, если хотите, чтобы система архивировала в том числе страницы, которые не открываются из-за ошибок.
Если используете приложение, вставьте ссылку на нужную страницу и нажмите Archive Page Now.
Для быстрого добавления страниц можно также использовать расширения для десктопных браузеров. После установки достаточно открыть в браузере нужную ссылку, нажать на кнопку плагина и выбрать Save Page Now.
Carbon-Neutralize the Approach
This is the idea that the high energy use of decentralized web technologies is okay as long as you make sure the energy comes from renewable resources. In practice, this looks like the Renewable Energy Buyers Alliance, the Crypto Climate Accord, or the Energy Web Foundation: leveraging the collective power of energy users to create a demand for low-carbon energy that triggers a transition of the grid to renewable infrastructure. You’ll often see the phrase “net zero” — we’ll emit carbon, but then try to balance it out.
Transition to renewables is absolutely necessary, but as an answer to high energy use, it falls short. In grid-level discussions of renewable energy adoption, we see a lot of celebration that renewables are a growing percentage of our energy source. For example, U.S. states set “renewable portfolio standards” (RPS) defining a percent-renewable energy source for their grid infrastructure, and it’s fairly common for states to exceed their targets. California, for example, had a goal of 33% renewables by 2020 which they had already exceeded by 2018.
What often gets passed over however, is that year over year, energy demand grows so much that this typically means a growth across all sectors of energy generation, from solar to coal. What we’re celebrating, then, is not a displacement of coal/actual reduction in carbon emissions, but that new demand is being covered by proportionally more renewable sources than we’re used to.
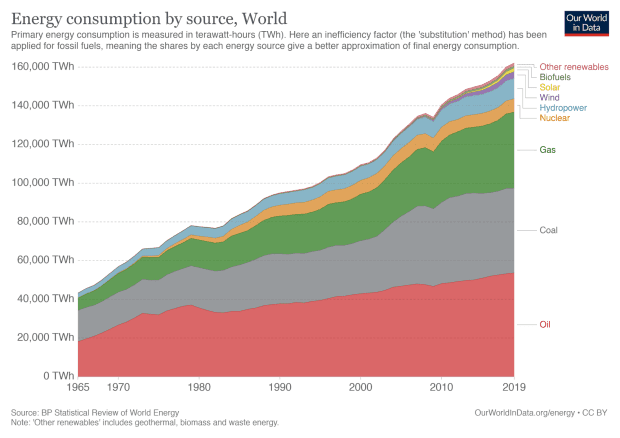
Growth in global energy demand, from BP’s Statistical Review of World Energy showing a general trend of growth across all sectors, including coal — even as renewables grow disproportionately.
And of course, even renewable infrastructure has an ecological cost (e.g. materials extraction) — so though decarbonization of our energy infrastructure is an important objective, any proposed solution that doesn’t attempt to decrease energy demand is underwhelming.
Стремительное развитие интернета во всем мире

Сегодня остается только удивляться тому, какую огромную пользу человечеству, смог принести Тим Бернер-Ли. Когда-то он создал интернет и первый сайт, произвел настоящую инновационную революцию, предшествующую стремительному развитию интернет-технологий и онлайн-бизнеса, размножению виртуальных-страниц, которые в настоящее время исчисляются миллиардами.
После появления самого первого сайта в сети-интернет, разработка сайтов стала стремительно развиваться на коммерческом уровне и стала успешной самостоятельной отраслью, которая пользуется спросом во всем мире. Так, в 1995 году веб-разработкой сайтов занималось уже примерно 1000 компаний, а по истечении десяти лет, только в США таких компаний уже было не менее 30 000 единиц зарегистрированных официально.
Первый русскоязычный сайт появился в интернете только в 1995 году, а вот более-менее активное развитие интернета в этой стране началось только ближе к концу 90-х годов. На сегодняшний день интернет пользуется огромным спросом во всем мире, множество провайдеров делают его доступным для все большего количества аудитории, благодаря расширению зон покрытия. Люди давно поняли и научились ценить всю прелесть интернет-паутины, в которой можно строить настоящий бизнес, работать и просто общаться с близкими тебе по духу единомышленниками. Но даже если нам кажется, что интернет освоен человечеством от и до, учитывая молодой возраст этого новшества, можно смело утверждать что на базе виртуальных разработок найдется еще масса засекреченных резервов, которые человечеству только предстоит освоить.
Создание веб-страниц
Разработка веб-сайтов – это процесс создания веб-ресурса или веб-приложения. HTML – специальный язык программирования для создания сайтов и веб-страниц – представляет собой несложный набор команд, описывающий структуру документа. Это язык разметки делит документ на заголовки, абзацы, таблицы, но не задает атрибуты форматирования.
Создается веб-сайт в 3 этапа:
- Веб-дизайн сайта. Разработкой внешнего вида будущего ресурса и созданием макетов занимаются веб-дизайнеры.
- Верстка. Верстальщик на основе макета разрабатывает готовые веб-страницы.
- Программирование. Программист на основе готовых шаблонов создает веб-ресурс.
Кроме непосредственно разработки, любому веб-сайту требуется дальнейшее администрирование, поддержка. Отдельная «головная боль» разработчиков и администраторов – безопасность веб-сайта. Понятие включает в себя настройку и использование HTTPS/HSTS, обновление CMS, регулярное изменение пароля входа и так далее. Безопасность ресурса для пользователей подтверждает сертификат веб-сайта.

Переделка сайта
 Сегодня закончена очередная, небольшая переделка сайта для улучшения его показателей. Что-то сразу было сделано не так, что-то нужно сделать в связи с произошедшими изменениями в Интернете. Опыт показывает, периодические переделки сайтов вполне нормальное явление, хотя есть и минусы.
Сегодня закончена очередная, небольшая переделка сайта для улучшения его показателей. Что-то сразу было сделано не так, что-то нужно сделать в связи с произошедшими изменениями в Интернете. Опыт показывает, периодические переделки сайтов вполне нормальное явление, хотя есть и минусы.
Итак, мой блог был создан в начале 2013 года. Несмотря на наличие уроков, мной было допущено достаточно много различных ошибок, которые не позволяли блогу нормально развиваться. Приходилось учиться, вникать и понимать, какие вопросы должны быть обязательно сделаны. Кроме того в Интернете многое меняется и то, что работало еще год назад, сегодня может уже не работать. Теперь интересно сравнить новый и старый блог. Мы это обязательно сделаем, когда будем рассматривать вопрос, как посмотреть историю сайта.
В январе 2016 года, был полностью заменен шаблон моего блога, он был выполнен специалистами по дизайну и верстке. Старый шаблон поднадоел, да и был он серийным, не у меня одного был установлен такой шаблон. В процессе переделки блога, возникало много мелких вопросов, которые устранялись по ходу. В результате полученного опыта на блоге была опубликована статья «Как и где заказывать сайт». Думаю, статья многим помогла не наступать на грабли.
За прошедший год выявились небольшие недочеты, выявились резервы. По этой причине снова сделана его небольшая переделка. В футер перенесен виджет моей группы Вконтакте, дополнительно установлен виджет моей группы на Facebook, а также установлен виджет от Google+. Всё лишнее из футера удалено. Можете перейти в футер и посмотреть сами.
В последнее время были проблемы на хостинге из-за превышения нагрузки на CPU ядро. Естественно, нужно было решить часть вопросов. По рекомендации специалиста, который делал мне верстку блога и делал его переделку, установлен плагин WP Smush.
Плагин WP Smush ужимает все изображения, которые есть в статьях, это уменьшает время загрузки сайта. Оптимизирована и работа слайдера. Позже нужно будет с ним поработать еще. Убраны внешние ссылки, которые получались от привязки к JustClick. Любая переделка отрицательно влияет на позиции блога. В результате статьи, которые были в Топ 1-5, провалились и теперь они находятся на позициях 20-40. Сколько времени потребуется на их возврат в исходное состояние неизвестно. Вот такой получился краткий отчет о модернизации моего блога.
Если Вы тоже хотите сделать редизайн своего ресурса, блога, хотите сделать новый дизайн или оформить группу с оригинальным дизайном в соцсетях, могу рекомендовать Вам сайт Юлии — профессионала дизайнерского мастерства. Можно сделать, как обычный дизайн, строгий, графический, так и мультяшный.
archive.md
Адреса данного Архива Интернета:
На главной странице говорящие за себя поля:
- Архивировать страницу, которая сейчас онлайн
- Искать сохранённые страницы

Для поиска по сохранённым страницам можно как указывать конкретный URL, так и домены, например:
- microsoft.com покажет снимки с хоста microsoft.com
- *.microsoft.com покажет снимки с хоста microsoft.com и всех его субдоменов (например, www.microsoft.com)
- покажет архив данного url (поиск чувствителен к регистру)
- поиск архивных url начинающихся с http://twitter.com/burg
Данный сервис сохраняет следующие части страницы:
- Текстовое содержимое веб страницы
- Изображения
- Содержимое фреймов
- Контент и изображения загруженные или сгенерированные с помощью Javascript на сайтах Web 2.0
- Скриншоты размером 1024×768 пикселей.
Не сохраняются следующие части веб-страниц:
- Flash и загружаемый им контент
- Видео и звуки
- RSS и другие XML-страницы сохраняются ненадёжно. Большинство из них не сохраняются, или сохраняются как пустые страницы.
Архивируемая страница и все изображения должны быть менее 50 Мегабайт.
Для каждой архивированной страницы создаётся ссылка вида http://archive.is/XXXXX, где XXXXX это уникальный идентификатор страницы. Также к любой сохранённой странице можно получить доступ следующим образом:
- http://archive.is/2013/http://www.google.de/ — самый новый снимок в 2013 году.
- http://archive.is/201301/http://www.google.de/ — самый новый снимок в январе 2013.
- http://archive.is/20130101/http://www.google.de/ — самый новый снимок в течение дня 1 января 2013.
Дату можно продолжить далее, указав часы, минуты и секунды:
- http://archive.is/2013010103/http://www.google.de/
- http://archive.is/201301010313/http://www.google.de/
- http://archive.is/20130101031355/http://www.google.de/
Для улучшения читаемости, год, месяц, день, часы, минуты и секунды могут быть разделены точками, тире или двоеточиями:
- http://archive.is/2013-04-17/http://blog.bo.lt/
- http://archive.is/2013.04.17-12:08:20/http://blog.bo.lt/
Также возможно обратиться ко всем снимкам указанного URL:
http://archive.is/http://www.google.de/
Все сохранённые страницы домена:
http://archive.is/www.google.de
Все сохранённые страницы всех субдоменов
http://archive.is/*.google.de
Чтобы обратиться к самой последней версии страницы в архиве или к самой старой, поддерживаются адреса вида:
- http://archive.is/newest/http://reddit.com/
- http://archive.is/oldest/http://reddit.com/
Чтобы обратиться к определённой части длинной страницы имеется две опции:
В доменах поддерживаются национальные символы:
- http://archive.is/www.maroñas.com.uy
- http://archive.is/*.测试
Обратите внимание, что при создании архивной копии страницы архивируемому сайту отправляется IP адрес человека, создающего снимок страницы. Это делается через заголовок X-Forwarded-For для правильного определения вашего региона и показа соответствующего содержимого.
Celebrate the Internet Archive’s 25th Anniversary!
As the Internet Archive turns 25, we invite you on a journey from way back to way forward, through the pivotal moments when knowledge became more accessible for all. On this anniversary page you can:
- sign up for our virtual celebration
- create a video anniversary message
- tweet about how the Internet Archive has enhanced your life & work
- dive deep into our stories, collections & important milestones in an interactive timeline
- send us a donation for our birthday!
But first, in the video above, go way back to 1996 when a young computer scientist named Brewster Kahle dreamed of building a “Library of Everything” for the digital age. A library containing all the published works of humankind, free to the public, built to last the ages. He named this digital library the Internet Archive. Its mission: to provide everyone with “Universal Access to All Knowledge.”
Возможности использования веб-архивов
Возможности сохраненной истории
Теперь каждый знает, что такое веб-архив, какие сайты предоставляют услуги сохранения копий проектов. Но многие до сих пор не понимают, как использовать представленную информацию. Возможности архивных данных выражаются в следующем:
- Выбор доменного имени. Не секрет, что многие веб-мастера используют уже прокачанные домены. Стоит понимать, что опытные юзеры отслеживают не только целевые параметры, но и историю предыдущего использования. Каждый пользователь сети желает знать, что приобретает: имелись ли ранее запреты или санкции, не попадал ли проект под фильтры.
- Восстановление сайта из архивов. Иногда случается беда, которая ставит под угрозу существование собственного проекта. Отсутствие своевременных бэкапов в профиле хостинга и случайная ошибка может привести к трагедии. Если подобное произошло, не стоит расстраиваться, ведь можно воспользоваться веб-архивом. О процессе восстановления поговорим ниже.
- Поиск уникального контента. Ежедневно на просторах интернета умирают сайты, которые наполнены контентом. Это случается с особым постоянством, из-за чего теряется огромный поток информации. Со временем такие страницы выпадают из индекса, и находчивый веб-мастер может позаимствовать информацию на личный проект. Конечно, существует проблема с поиском, но это вторичная забота.
Мы рассмотрели основные возможности, которые предоставляют веб-архивы, самое время перейти к более подробному изучению отдельных элементов.
Восстанавливаем сайт из веб-архива
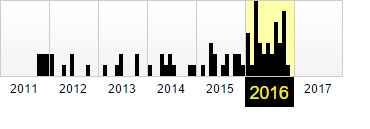 Фиксация в веб-архиве за 2011–2016 годы
Фиксация в веб-архиве за 2011–2016 годы
Никто не застрахован от проблем с сайтами. Большинство их них решается с использованием бэкапов. Но что делать, если сохраненной копии на сервере хостинга нет? Воспользоваться веб-архивом. Для этого следует:
- Зайти на специализированный ресурс, о которых мы говорили ранее.
- Внести собственное доменное имя в строку поиска и открыть проект в новом окне.
- Выбрать наиболее удачный снимок, который располагается ближе к проблемной дате и имеет полноценный вид.
- Исправить внутренние ссылки на прямые. Для этого используем ссылку «http://web.archive.org/web/любой_порядковый_номер_id_/Название сайта».
- Скопировать потерянную информацию или данные дизайна, которые будут применены для восстановления.
Заметим, что процесс несколько утомительный, с учетом скорости работы архива. Поэтому рекомендуем владельцам больших веб-ресурсов чаще выполнять бэкапы, что сохранит время и нервы.
Ищем уникальный контент для собственного сайта
 Уникальный контент из веб-архива
Уникальный контент из веб-архива
Некоторые веб-мастера используют интересный способ получения нового, никому не нужного контента. Ежедневно сотни сайтов уходят в небытие, а вместе с ними теряется информация. Чтобы стать владельцем контента, нужно выполнить следующее:
- Внести URLв строку поиска.
- На сайте аукциона доменных имен скачать файлы с именем ru.
- Открыть полученные файлы с использованием excel и начать отбор по параметру наличия проектной информации.
- Найденные в списке проекты ввести на странице поиска веб-архива.
- Открыть снимок и получить доступ к информационному потоку.
Рекомендуем отслеживать контент на наличие плагиата, это позволит найти действительно достойные тексты. А на этом все! Теперь каждый знает о возможностях и методах использования веб-архива. Используйте знание с умом и выгодой.
Как найти уникальный контент для своего сайта
Часто возникают ситуации, когда проекты по различным причинам закрывают, удаляя сайт с хостинга. При этом на таком ресурсе могут сохраняться полезные и интересные статьи. Через некоторое время они перестают индексироваться поисковыми системами и текст статей становится уникальным. Для владельцев информационных сайтов подобные статьи на нужную тематику представляют интерес.
Такой контент можно добавлять на собственный проект без угрозы каких-либо санкций со стороны поисковых систем, поскольку для них основное значение имеет уникальность контента на текущий момент, а не его первоисточник. Чтобы найти подходящие статьи, сэкономив время и деньги необходимые на создание собственного контента, нужно предварительно узнать список доменов, которые освободились в последнее время.
Зайдем в раздел продающихся доменов на сервисе Reg.ru, выберем категорию, совпадающую с тематикой собственного проекта, например, здоровье:
Далее выбираем подкатегорию или просматриваем все предложенные домены, выбирая из них варианты для дальнейшего анализа в веб-архиве:
После того как подходящие статьи найдены в веб-архиве необходимо проверить их на уникальность с помощью сервисов антиплагиата, например, text.ru. Если контент уникален, опубликуйте его на собственном сайте.
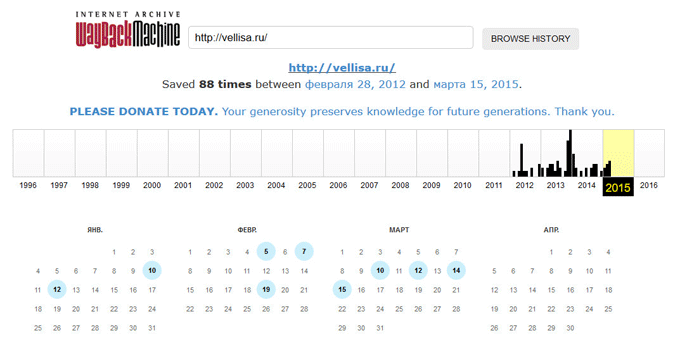
Поиск сайтов в Wayback Machine
Wayback Machine
На странице «Internet Archive Wayback Machine» введите в поле поиска URL адрес сайта, а затем нажмите на кнопку «BROWSE HISTORY».
Под полем поиска находится информация об общем количестве созданных архивов для данного сайта за определенный период времени. На шкале времени по годам отображено количество сделанных архивов сайта (снимков сайта может быть много, или, наоборот, мало).
Выделите год, в центральной части страницы находится календарь, в котором выделены голубым цветом даты, когда создавались архивы сайта. Далее нажмите на нужную дату.
Вам также может быть интересно:
- Советские фильмы онлайн в интернете
- Яндекс Дзен — лента персональных рекомендаций
Обратите внимание на то, что при подведении курсора мыши отобразится время создания снимка. Если снимков несколько, вы можете открыть любой из архивов
Сайт будет открыт в том состоянии, которое у него было на момент создания архива.
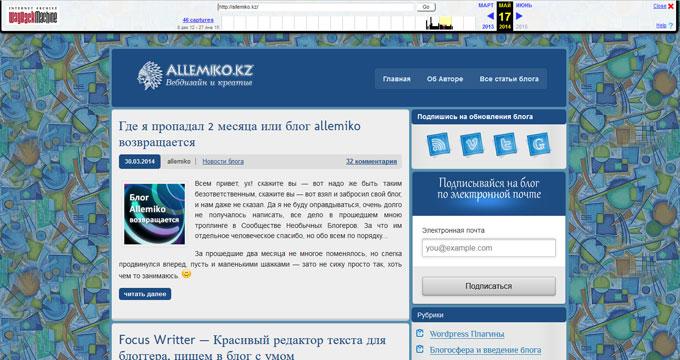
За время существования моего сайта, у него было только два шаблона (темы оформления). На этом изображении вы можете увидеть, как выглядел мой сайт в первой теме оформления.

На этом изображении вы видите сайт моего знакомого, Алема из Казахстана. Данного сайта уже давно нет в интернете, поисковые системы не обнаруживают этот сайт, но благодаря архиву интернета все желающие могут получить доступ к содержимому удаленного сайта.
Зачем был придуман первый веб-сайт
 Главная страница сайта
Главная страница сайта
Цель проекта банальна для эпохальной технологии на начальной стадии — упростить работу команде. Марк Цукерберг затем же создавал Facebook, чтобы ему и его одногруппникам было проще общаться друг с другом.
ЦЕРН отклонил идею, но Бернерс Ли проявил настойчивость и продолжил разрабатывать сайт, уже в команде с Робертом Кайо.
 Так раньше выглядел ЦЕРН, Европейская организация по ядерным исследованиям, крупнейшая в мире лаборатория физики высоких энергий.
Так раньше выглядел ЦЕРН, Европейская организация по ядерным исследованиям, крупнейшая в мире лаборатория физики высоких энергий.
Ученый предложил сделать так, чтобы гипертекст был доступен одновременно нескольким компьютерам, подключенным к интернету.
«Меня расстраивало, на разных компьютерах содержалась разная информация. И чтобы получить к ней доступ к нескольким источникам, нужно задействовать несколько компьютеров», — говорил Бернерс Ли.
 NeXT. Компьютер, на котором был создан первый веб-сайт.
NeXT. Компьютер, на котором был создан первый веб-сайт.
У британца была и более масштабная задача. В ЦЕРН приезжали люди из университетов со всего мира, и привозили с собой компьютеры со всеми видами программного обеспечения. Проблемой была невозможность использования одной программы на компьютерах с разными видами софта.
Бернерс Ли искал ее решение. Изначально он думал о создании ряда программ, берущих информацию из одной системы и конвертирующих ее формат для показа в другой.
Но оптимизировать программы под каждый софт — долго, энергозатратно и дорого. Британец выбрал другой способ: просто дать доступ к информации всем сразу.
Все про archive.org: как пользоваться сервисом и как достать сайт из веб-архива
Брюстер Кайл создал сервис Internet Archive Wayback Machine, без которого невозможно представить работу современного интернет-маркетинга. Посмотреть историю любого портала, увидеть, как выглядели определенные страницы раньше, восстановить свой старый веб-ресурс или найти нужный и интересный контент — все это можно сделать с помощью Webarchive.
Как на archive.org посмотреть историю сайта
Благодаря веб-сканеру, в библиотеке веб-архива, хранится большая часть интернет-площадок со всеми их страницами. Также, он сохраняет все его изменения. Таким образом, можно просмотреть историю любого веб-ресурса, даже если его уже давно не существует.
Для этого, необходимо зайти на https://web.archive.org/ и в поисковой строке ввести адрес веб-ресурса.
 После, некоторого времени, веб-архив выдаст календарь с датами изменений данной страницы и информацию о его создании и количестве изменений за весь период.
После, некоторого времени, веб-архив выдаст календарь с датами изменений данной страницы и информацию о его создании и количестве изменений за весь период.
 Далее, с помощью календаря со стрелками, в самом верху экрана, можно перелистывать страницы, по хронологии их изменений, чтобы отследить, как изменялся внешний вид и их содержание.
Далее, с помощью календаря со стрелками, в самом верху экрана, можно перелистывать страницы, по хронологии их изменений, чтобы отследить, как изменялся внешний вид и их содержание.
 Таким образом, можно нырнуть в прошлое и увидеть все его перемены, которые с ним происходили за все время его существования.
Таким образом, можно нырнуть в прошлое и увидеть все его перемены, которые с ним происходили за все время его существования.
Почему вы можете не узнать на Webarchive, как выглядел сайт раньше
Случается такое, что веб-площадка не может быть найден с помощью сервиса Internet Archive Wayback Machine. И происходит это по нескольким причинам:
- правообладатель решил удалить все копии;
- веб-ресурс закрыли, согласно закону о защите интеллектуальной собственности;
- в корневую директорию интернет-площадки, внесен запрет через файл robots.txt
Для того, чтобы сайт в любой момент был в веб-архиве, рекомендуется принимать меры предосторожности и самостоятельно сохранять его в библиотеке Webarchive. Для этого в разделе Save Page Now введите адрес веб-ресурса, который нужно заархивировать, нажмите кнопку Save Page
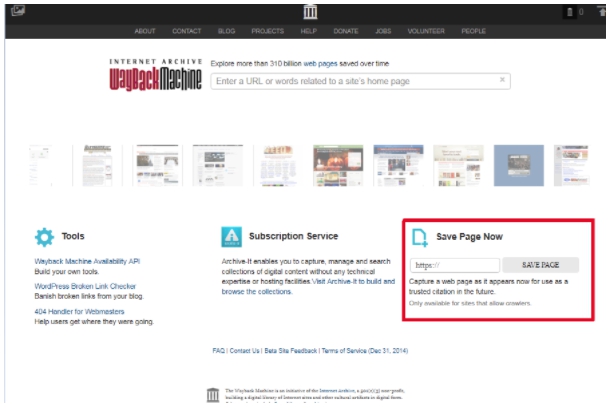 Таким образом, для безопасности и сохранности всей информации, необходимо такую процедуру повторять с каждым изменением. Это даст 100% гарантию сохранения ваших страниц на долгое время.
Таким образом, для безопасности и сохранности всей информации, необходимо такую процедуру повторять с каждым изменением. Это даст 100% гарантию сохранения ваших страниц на долгое время.
Как недействующий сайт восстановить из веб-архива
Бывают разные ситуации, когда браузер выдает, что такого-то веб-сервиса больше нет. Но данные нужно извлечь. Поможет Webarchive.
И для этого существует два варианта. Первый подходит для старых площадок небольшого размера и хорошо проиндексированных. Просто извлеките данные нужной версии. Далее просматривается код страницы и дошлифовываются вручную ссылки. Процесс несколько трудозатратный по времени и действиям. Поэтому существует другой, более оптимальный способ.
Второй вариант идеален для тех, кто хочет сэкономить время и решить вопрос скачивания, максимально быстро и легко. Для этого нужно открыть сервис восстановления сайта из Webarchive – RoboTools. Ввести доменное имя интересующего портала и указать дату сохраненной его версии. Через некоторое время, задача будет выполнена в полном объеме, с наполнением всех страниц.
Как найти контент из веб-архива
Webarchive является замечательным источником для наполнения полноценными текстами веб-ресурсов. Есть множество площадок, которые по ряду причин прекратили свое существование, но содержат в себе полезную и нужную информацию. Которая не попадает в индексы поисковых систем, и по сути есть неповторяющейся.
Так, существует свободные домены, которые хранят много интересного материала. Все что нужно, это найти подходящее содержание, и проверить его уникальность. Это очень выгодно, как финансово – ведь не нужно будет оплачивать работу авторов, так и по времени – ведь весь контент уже написан.
Как сделать так, чтобы сайт не попал в библиотеку веб-архива
Случаются такие ситуации, когда владелец интернет-площадки дорожит информацией, размещенной на его портале, и он не хочет, чтобы она стала доступной широкому кругу. В таких ситуациях есть один простой выход – в файле robots.txt, прописать запретную директиву для Webarchive. После этого изменения в настройках, веб-машина больше не будет создавать копии такого веб-ресурса.
