Субд access
Содержание:
- Один-ко-многим (1 — ¥)
- 2.4. Microsoft Access 2007
- Создание связей между сущностями
- Специфика базы данных Oracle
- MySQL
- Приведём пример
- Идеальные требования для интеграции схемы
- Нормализация базы данных
- Один-к-одному (1 — 1)
- Ключевое поле
- Рекомендуемые файлы
- 1 Анализ предметной области
- Вставка рисунка или объекта
- БД из трех таблиц
- Концептуальная модель базы данных
- Инструкция CREATE SCHEMA
Один-ко-многим (1 — ¥)
Связь один-ко-многим связывает одну запись из
основной таблицы с несколькими записями из подчинённой таблицы, у которых
значения связанных полей совпадают. Это наиболее часто используемый тип связи,
который связывает подчинённую таблицу с основной, например, подстановочной
таблицей.
В этом случае поле, по значению которого
осуществляется связь, должно быть в основной таблице индексированным (Совпадения не допускаются)
(как правило, ключевое поле с типом данных — Счётчик), а в подчинённой таблице индексированным (Совпадения допускаются)
(как правило, числовое поле с типом данных Длинное
целое).
2.4. Microsoft Access 2007
2.4.5. Создание запросов и поиск информации в базе данных
В СУБД Access 2007 можно создавать queries для отображения требуемых полей из записей одной или нескольких таблиц.
В СУБД Access 2007 применяются различные типы запросов: на выборку, на обновление, на добавление, на удаление, перекрестный query, выполнение вычислений, создание таблиц. Наиболее распространенным является query на выборку. Применяются два типа запросов: query по образцу (QBE) и query на основе структурированного языка запросов (SQL).
Запросы на выборку используются для отбора требуемой пользователю информации, содержащейся в нескольких таблицах. Они создаются только для связанных таблиц. Queries могут основываться как на нескольких таблицах, так и существующих запросах. СУБД Access 2007 включает такие средства создания запросов, как Мастер и Конструктор.
Кроме того, в СУБД Access 2007 существует множество средств для поиска и отображения информации, которая хранится в базе данных. Данные в таблицах можно отсортировать на основе любого поля или комбинации полей. Для извлечения из базы данных необходимых записей можно отфильтровать таблицу, применив средства фильтрации.
На скриншоте (рисунок 1) средства сортировки и фильтрации выделены скругленным прямоугольником красного цвета.

Рис. 1.
Рассмотрим создание запроса на выборку с помощью Конструктора
Для создания нового пустого запроса в режиме конструктора надо щелкнуть на пиктограмме Конструктор запросов (рисунок 2).

Рис. 2.
Откроется активное окно диалога Добавление таблицы (рисунок 3) на фоне неактивного окна «Запрос1». В этом окне можно выбрать таблицы и queries для создания новых запросов.
Рис. 3.
В окне Добавление таблицы следует выбрать несколько таблиц из представленного списка таблиц, на основе которых будет проводиться выбор данных, и щелкнуть на кнопке Добавить. После этого закрыть окно Добавление таблицы, а окно «Запрос1» станет активным (рисунок 4).

Рис. 4.
Окно Конструктора состоит из двух частей – верхней и нижней. В верхней части окна размещается схема данных запроса, которая содержит список связанных таблиц. В нижней части окна находится Бланк построения запроса QBE, в котором каждая строка выполняет определенную функцию.
Переместим имена полей с таблиц-источников в Бланк. Из таблицы Группы студентов переместим поле Название в первое поле Бланка, из таблицы Студенты переместим поле Фамилии во второе поле, а из таблицы Успеваемость переместим поле Оценка в третье поле и из таблицы Дисциплины переместим поле Название в четвертое поле Бланка запросов.
При необходимости можно задать принцип сортировки (по возрастанию или по убыванию) результатов запроса. В строке «Вывод на экран» автоматически устанавливается флажок просмотра информации.
Условия ограниченного поиска или критерий поиска информации вводится в строке «Условия» отбора и строке «Или». Например, введем критерий поиска — «5/A» в строке «Условия» для поля Оценка. В этом случае в результате выполнения запроса на экране будут отображаться все фамилии студентов, которые получили оценку 5/A (рисунок. 5).

Рис. 5.
Далее надо закрыть окно запроса Запрос1, появится окно диалога Сохранить, ответить — Да и ввести имя запроса, например «Успеваемость студентов». Для запуска запроса дважды щелкнем на query «Успеваемость студентов», откроется таблица с результатами выполненного запроса (рис. 6).

Рис. 6.
Далее создаем параметрический query или query с параметрами. Создаем этот query также как и предыдущий, в режиме конструктора, но только в строке Условия отбора для поля Фамилия введем условие отбора в виде приглашения в квадратных скобках, например . В этом случае в результате выполнения запроса на экране будет отображаться фамилия студента и все дисциплины, по которым он получил оценку.
Закрыть окно запроса на выборку. На вопрос о сохранении изменения ответить — Да и ввести имя запроса, например «Параметрический query». Запустим Параметрический query, дважды щелкнув на нем. В открывшемся на экране окне диалога «Введите значение параметра» надо ввести фамилию студента, информацию об успеваемости которого необходимо получить (рис. 8).

Рис. 7.
Затем надо щелкнуть на кнопке ОК, откроется таблица с результатами выполненного запроса (рис. 8).

Рис. 8.
В некоторых случаях для создания запросов можно использовать Мастер запросов. После создания запросов на выборку информации из БД Access 2007 можно приступать к формированию форм.
Далее >>> Раздел: 2.4.6. Создание форм для ввода данных в таблицы базы данных Access 2007
Создание связей между сущностями
Теперь, когда данные преобразованы в таблицы, нужно проанализировать связи между ними. Сложность базы данных определяется количеством элементов, взаимодействующих между двумя связанными таблицами. Определение сложности помогает убедиться, что вы разделили данные на таблицы наиболее эффективно.
Каждый объект может быть взаимосвязан с другим с помощью одного из трех типов связи:
Связь «один-к одному»
Когда существует только один экземпляр объекта A для каждого экземпляра объекта B, говорят, что между ними существует связь «один-к одному» (часто обозначается 1:1). Можно указать этот тип связи в ER-диаграмме линией с тире на каждом конце:
Если при проектировании и разработке баз данных у вас нет оснований разделять эти данные, связь 1:1 обычно указывает на то, что в лучше объединить эти таблицы в одну.
Но при определенных обстоятельствах целесообразнее создавать таблицы со связями 1:1. Если есть поле с необязательными данными, например «описание», которое не заполнено для многих записей, можно переместить все описания в отдельную таблицу, исключая пустые поля и улучшая производительность базы данных.
Чтобы гарантировать, что данные соотносятся правильно, в нужно будет включить, по крайней мере, один идентичный столбец в каждой таблице. Скорее всего, это будет первичный ключ.
Связь «один-ко-многим»
Эта связи возникают, когда запись в одной таблице связана с несколькими записями в другой. Например, один клиент мог разместить много заказов, или у читателя может быть сразу несколько книг, взятых в библиотеке. Связи «один- ко-многим» (1:M) обозначаются так называемой «меткой ноги вороны», как в этом примере:
Чтобы реализовать связь 1:M, добавьте первичный ключ из «одной» таблицы в качестве атрибута в другую таблицу. Если первичный ключ таким образом указан в другой таблице, он называется внешним ключом. Таблица со стороны связи «1» представляет собой родительскую таблицу для дочерней таблицы на другой стороне.
Связь «многие-ко-многим»
Когда несколько объектов таблицы могут быть связаны с несколькими объектами другой. Говорят, что они имеют связь «многие-ко-многим» (M:N). Например, в случае студентов и курсов, поскольку студент может посещать много курсов, и каждый курс могут посещать много студентов.
На ER-диаграмме эти связи отображаются с помощью следующих строк:
При проектировании структуры базы данных реализовать такого рода связи невозможно. Вместо этого нужно разбить их на две связи «один-ко-многим».
Для этого нужно создать между этими двумя таблицами новую сущность. Если между продажами и продуктами существует связь M:N, можно назвать этот новый объект «sold_products», так как он будет содержать данные для каждой продажи. И таблица продаж, и таблица товаров будут иметь связь 1:M с sold_products. Этот вид промежуточного объекта в различных моделях называется таблицей ссылок, ассоциативным объектом или таблицей связей.
Каждая запись в таблице связей будет соответствовать двум сущностям из соседних таблиц. Например, таблица связей между студентами и курсами может выглядеть следующим образом:
Обязательно или нет?
Другим способом анализа связей является рассмотрение того, какая сторона связи должна существовать, чтобы существовала другая. Необязательная сторона может быть отмечена кружком на линии. Например, страна должна существовать для того, чтобы иметь представителя в Организации Объединенных Наций, а не наоборот:
Два объекта могут быть взаимозависимыми (один не может существовать без другого).
Рекурсивные связи
Иногда при проектировании базы данных таблица указывает на себя саму. Например, таблица сотрудников может иметь атрибут «руководитель», который ссылается на другое лицо в этой же таблице. Это называется рекурсивными связями.
Лишние связи
Лишние связи — это те, которые выражены более одного раза
Как правило, можно удалить одну из таких связей без потери какой-либо важной информации. Например, если объект «ученики» имеет прямую связь с другим объектом, называемым «учителя», но также имеет косвенные отношения с учителями через «предметы», нужно удалить связь между «учениками» и «учителями»
Так как единственный способ, которым ученикам назначают учителей — это предметы.
Специфика базы данных Oracle
В контексте баз данных Oracle , A объект схемы представляет собой логическую структуру хранения данных .
База данных Oracle связывает отдельную схему с каждым пользователем базы данных . Схема состоит из набора объектов схемы. Примеры объектов схемы включают:
- столы
- Просмотры
- последовательности
- синонимы
- индексы
- кластеры
- ссылки на базу данных
- снимки
- процедуры
- функции
- пакеты
С другой стороны, объекты, не относящиеся к схеме, могут включать:
- пользователи
- роли
- контексты
- объекты каталога
Объекты схемы не имеют однозначного соответствия физическим файлам на диске, в которых хранится их информация. Однако базы данных Oracle логически хранят объекты схемы в табличном пространстве базы данных. Данные каждого объекта физически содержатся в одном или нескольких файлах данных табличного пространства . Для некоторых объектов (таких как таблицы, индексы и кластеры) администратор базы данных может указать, сколько дискового пространства Oracle RDBMS выделяет для объекта в файлах данных табличного пространства.
Нет необходимой взаимосвязи между схемами и табличными пространствами: табличное пространство может содержать объекты из разных схем, а объекты для одной схемы могут находиться в разных табличных пространствах. Однако специфика базы данных Oracle заставляет платформу распознавать негомогенизированные различия последовательностей, что считается решающим ограничивающим фактором в виртуализированных приложениях.
MySQL
Самый именитый представитель нашего обзора программ для разработки базы данных. Бесплатная база данных MySQL существует с 1995 года и теперь принадлежит компании Oracle. СУБД имеет открытый исходный код. Также существует несколько платных версий, которые предлагают дополнительные функции, такие как гео-репликация кластера и автоматическое масштабирование.
Поскольку MySQL является отраслевым стандартом, она совместима практически со всеми операционными системами и написана на языках C и C ++. Это решение является отличным вариантом для международных пользователей. Сервер СУБД может выводить клиентам сообщения об ошибках на нескольких языках.
Достоинства
- Проверка на стороне сервера;
- Может использоваться как локальная база данных;
- Гибкая система привилегий и паролей;
- Безопасное шифрование всего трафика паролей;
- Библиотека, которая может быть встроена в автономные приложения;
- Предоставляет сервер в качестве отдельной программы для сетевого окружения клиент/сервер.
Недостатки практической разработки и администрирования баз данных MySQL Приобретена компанией Oracle:
- пользователи полагают, что MySQL больше не подпадает под категорию бесплатного и открытого программного обеспечения;
- больше не поддерживается сообществом;
- пользователи не могут исправлять ошибки и патчи;
- проигрывает другим решениям из-за медленных обновлений.
Приведём пример
Допустим, вы хотите создать базу данных для интернет-форума. На форуме есть зарегистрированные пользователи, создающие темы и оставляющие сообщения в данных темах. Вся эта информация и должна размещаться в базе данных.
В теории всё можно расположить в одной таблице, а именно:
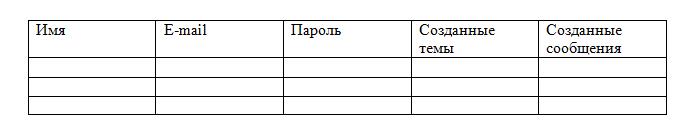
Однако такое расположение противоречит атомарности, причём в столбцах «Созданные сообщения» и «Созданные темы» возможно неограниченное число значений. Целесообразнее всего разбить таблицу на три:
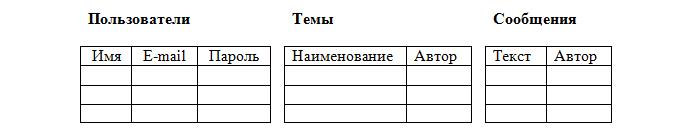
Теперь таблица «Пользователи» соответствует правилам. Но вот таблицы «Сообщения» и «Темы» — нет, т. к. не должно быть 2-х одинаковых строк. В нашем же случае один и тот же пользователь может написать 2 одинаковых сообщения:
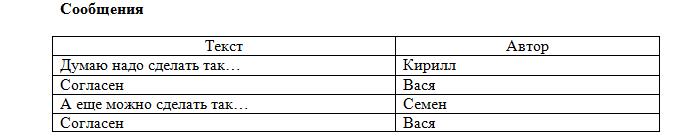
А ещё давайте вспомним о том, что каждое сообщение должно относиться к какой-нибудь теме. Для решения этого вопроса в реляционных базах данных используют ключи.
Идеальные требования для интеграции схемы
Перечисленные ниже требования влияют на детальную структуру создаваемых схем. Для некоторых приложений не требуется выполнение всех этих условий, но эти четыре требования являются наиболее идеальными.
- Сохранение перекрытия
- Каждый из перекрывающихся элементов, указанных во входном отображении, также находится в отношении схемы базы данных.
- Расширенное сохранение перекрытия
- Элементы, зависящие от источника, связанные с перекрывающимися элементами источника, передаются в схему базы данных.
- Нормализация
- Независимые сущности и отношения в исходных данных не должны группироваться вместе в одном отношении в схеме базы данных. В частности, элементы схемы, зависящие от источника, не должны группироваться с перекрывающимися элементами схемы, если при группировании совместно размещаются независимые объекты или отношения.
- Минимальность
- Если какие-либо элементы схемы базы данных отброшены, схема базы данных не идеальна.
Нормализация базы данных
После предварительного проектирования базы данных можно применить правила нормализации, чтобы убедиться, что таблицы структурированы правильно.
В то же время не все базы данных необходимо нормализовать. В целом, базы с обработкой транзакций в реальном времени (OLTP), должны быть нормализованы.
Базы данных с интерактивной аналитической обработкой (OLAP), позволяющие проще и быстрее выполнять анализ данных, могут быть более эффективными с определенной степенью денормализации. Основным критерием здесь является скорость вычислений. Каждая форма или уровень нормализации включает правила, связанные с нижними формами.
Первая форма нормализации
Первая форма нормализации (сокращенно 1NF) гласит, что во время логического проектирования базы данных каждая ячейка в таблице может иметь только одно значение, а не список значений. Поэтому таблица, подобная той, которая приведена ниже, не соответствует 1NF:
Возможно, у вас возникнет желание обойти это ограничение, разделив данные на дополнительные столбцы. Но это также противоречит правилам: таблица с группами повторяющихся или тесно связанных атрибутов не соответствует первой форме нормализации. Например, приведенная ниже таблица не соответствует 1NF:
Вместо этого во время физического проектирования базы данных разделите данные на несколько таблиц или записей, пока каждая ячейка не будет содержать только одно значение, и дополнительных столбцов не будет. Такие данные считаются разбитыми до наименьшего полезного размера. В приведенной выше таблице можно создать дополнительную таблицу «Реквизиты продаж», которая будет соответствовать конкретным продуктам с продажами. «Продажи» будут иметь связь 1:M с «Реквизитами продаж».
Вторая форма нормализации
Вторая форма нормализации (2NF) предусматривает, что каждый из атрибутов должен полностью зависеть от первичного ключа. Каждый атрибут должен напрямую зависеть от всего первичного ключа, а не косвенно через другой атрибут.
Например, атрибут «возраст» зависит от «дня рождения», который, в свою очередь, зависит от «ID студента», имеет частичную функциональную зависимость. Таблица, содержащая эти атрибуты, не будет соответствовать второй форме нормализации.
Кроме этого таблица с первичным ключом, состоящим из нескольких полей, нарушает вторую форму нормализации, если одно или несколько полей не зависят от каждой части ключа.
Таким образом, таблица с этими полями не будет соответствовать второй форме нормализации, поскольку атрибут «название товара» зависит от идентификатора продукта, но не от номера заказа:
- Номер заказа (первичный ключ);
- ID товара (первичный ключ);
- Название товара.
Третья форма нормализации
Третья форма нормализации (3NF): каждый не ключевой столбец должен быть независим от любого другого столбца. Если при проектировании реляционной базы данных изменение значения в одном не ключевом столбце вызывает изменение другого значения, эта таблица не соответствует третьей форме нормализации.
В соответствии с 3NF, нельзя хранить в таблице любые производные данные, такие как столбец «Налог», который в приведенном ниже примере, напрямую зависит от общей стоимости заказа:
В свое время были предложены дополнительные формы нормализации. В том числе форма нормализации Бойса-Кодда, четвертая-шестая формы и нормализации доменного ключа, но первые три являются наиболее распространенными.
Многомерные данные
Некоторым пользователям может потребоваться доступ к нескольким разрезам одного типа данных, особенно в базах данных OLAP. Например, им может потребоваться узнать продажи по клиенту, стране и месяцу. В этой ситуации лучше создать центральную таблицу, на которую могут ссылаться таблицы клиентов, стран и месяцев. Например:
Один-к-одному (1 — 1)
Связь один-ко-многим связывает одну запись из
основной таблицы с одной записью из подчинённой таблицы, у которых значения
связанных полей совпадают. Этот тип связи используется редко и применяется в
том случае, когда программист хочет по каким-либо причинам разбить одну таблицу
на две и более таблиц.
В этом случае поле, по значению которого
осуществляется связь, должно быть в основной таблице индексированным (Совпадения не допускаются)
(как правило, ключевое поле с типом данных — Счётчик), а в подчинённой таблице индексированным (Совпадения не допускаются)
(как правило, числовое поле с типом данных Длинное
целое).
Ключевое поле
Ключевое поле
Это та запись, которая определяет запись в таблице.
Нажимаем в колонке слева на названии таблицы Читатель. Справа появилась таблица. Правой кнопкой нажимаем на названии – конструктор – в пустом поле пишем код читателя.
Сделаем это поле ключевым (на панели задач – ключевое поле) и закроем таблицу.
Это первичный ключ. Для ключевых полей используют тип – счетчик или числовой.
Определим ключевое поле для каждой таблицы аналогично предыдущей.
Книги – код книги.
Издательство – код издательства (тип данных –мастер подстановок – Издательство- выберите поле код и наименование).
Выдача – код выдачи (код читателя – таблица Читатель /код читателя и фамилия/ и код книги – таблица Книги/ код книги и название).
Любое поле можно перетащить мышкой в начало таблицы или в другое нужное место. Ключевые поля обычно ставят на первое месте
Связывание таблиц
Переходим на вкладку – Работа с базами данных – схема данных – появилось окно.
Поочередно нажимаем на название каждой таблицы и закрываем окно.
Появилась схема данных. Определим как будем связывать таблицы.
Издательства выпускают книги. Значит, в таблицу Книги надо добавить Код издательства. Для этого открываем таблицу Книги в режиме конструктора и добавляем код издательства.
Возвращаемся в схему данных и перетаскиваем Код издательства из одной таблицы в Код издательства другой. Появляется окно. Ставим Обеспечение целостности данных и в двух других пунктах ниже. Далее нажимаем создать. Появляется связь – один ко многим, т.е. одно издательство выпускает много книг.
Аналогично свяжем две другие таблицы.
Откроем таблицу Выдача через конструктор. Добавляем поле Код читателя.
Сохраняем, закрываем.
Теперь Код читателя таблицы Читатель переносим на Код читателя таблицы Выдача.
Ставим везде галочки — создать. Появилась связь (читатель берет много книг).
Теперь свяжем таблица Книги и Выдача. Для этого в таблицу Выдача добавим Код книги. И проделаем те же манипуляции.
Заполнение таблиц
Берем таблицу Читатель. Код читателя ставим на первое место. Нумерация будет автоматическая в этом поле. Вводим остальные данные (не менее 10) и сохраняем правой кнопкой.
Заполняем остальные таблицы по аналогии.
Рекомендуемые файлы
Ответы на сертификацию Google Рекламы по проведению кампаний для приложений 2021 Сентябрь
Информатика, программирование
FREE
Лабораторки с 1 — 10 на С
Информатика
FREE
Лекции за 1 курс
Информатика
Ответы на Аттестацию официального партнера amoCRM 2021
Информатика
FREE
Готовые ЛР и ДЗ (ИУ5)
Информатика
Ответы на сертификацию Яндекс.Директ с прокторингом 2021 Сентябрь
Информатика
Рис.10
Сплошные линии, соединяющие блоки, отображают связи. Запись Заказ_на_закупку связана с записями Статья_закупки, в которых содержится заказ на закупку. Запись Поставщик связана с записями Расценка, описывающими поставляемые товары и расценки. Связи на схеме могут обеспечивать передачу такой информации, которая не представлена конкретными элементами данных, показанными на схеме.
Штриховые линии отображают перекрестные ссылки. Они не обеспечивают передачу дополнительной информации и если их убрать, то потери информации не произойдет.
Термин схема используется для определения полной таблицы всех типов элементов данных и типов записей, хранимых в БД. Термином подсхема определяют описание данных, которое использует ПП – лист. На основе одной схемы можно составить много различных подсхем. Например, на рис. 11 приведены подсхемы двух ПП – листов. Программисты имеют различные представления о данных, но обе подсхемы получены из схемы, приведенной на рис. 11.
Подсхема программиста А
Подсхема программиста В
Ни схемы, ни подсхемы не отражают способов физического запоминания данных. Существует 4 различных вида описания данных:
1.подсхема – таблица, описывающая ту часть данных, которая ориентирована на нужды одной или нескольких прикладных программ.
2.глобальное описание логической структуры БД или схема – таблица, логически описывающая всю БД. Она отражает представление о данных администратора БД.
3.описание физической организации БД – таблица физического расположения данных на носителях информации. Это представление о данных нужно системному программисту, который занимается вопросами эффективности работы системы, расположения или поиска, а также вопросами использования методов сжатия данных.
4.описание данных, которое система передает пользователю терминала БД как можно более близким к тому описанию данных, которое он использует в своей работе.
Связи этих четырех видов описания данных представлены на рисунке 12.
Следующий момент, который следует обсудить – это связи между элементами данных.
Взаимосвязь между двумя типами данных может быть простая и сложная. Под простой связью понимается такая связь, в которой элементы соединяются один с одним. Например, №_служащего и Имя, так как каждое имя имеет соответствующий №_служащего и наоборот.
Связь между служащим и отделом простая (каждый служащий может работать только в одном отделе), а связь между отделом и служащим сложная, называемая также «многие к одному», (в каждом отделе может работать много служащих).
Четыре типа связи возможны между двумя наборами элементов А и В. связь А с В может быть простой, а обратная связь – сложной и наоборот, а также обе связи могут быть простыми или сложными. На рис. 13 изображены все эти варианты.
А В – один к одному; А В – один ко многим;
А В – многие к одному; А В – многие ко многим
Рис. 13.
На рис. 14 показаны два способа представления связей между двумя наборами элементов.
|
|
|
№_служащего |
|
53730 |
|
28719 |
|
53550 |
|
79623 |
|
15971 |
|
51883 |
|
№_отдела |
|
044 |
|
172 |
|
090 |
|
|
|
|
|
№_служащего |
№_отдела |
|
53730 |
044 |
|
28719 |
172 |
|
53550 |
044 |
|
79623 |
090 |
|
15971 |
172 |
|
51883 |
044 |
Рис.14
Правила изображения схемы
1.отображать различие между именами записей, именами элементов данных и другими именами.
2.отмечать идентификаторы записей.
3.представлять ясно, какие связи являются простыми, а какие – «один ко многим».
4.связи отличать от перекрестных ссылок
5.связи между записями именовать или нумеровать.
6.не использовать повторяющиеся имена.
Один из способов представления схемы, приведенной на рис. 15, в соответствии с этими правилами (стрелки не являются обязательными).
Бесплатная лекция: «33. Конформационные изменения в белке» также доступна.
Рис. 15
1 Анализ предметной области
Зачастую, кинотеатр состоит из нескольких залов разной конфигурации, а посетителю предоставляется возможность выбора билета, для этого ему отображается текущее состояние зала. Выбранные места посетитель сообщает кассиру, который вводит их в систему и места помечаются как «проданные». Это «основной» сценарий использования информационной системы, однако надо учесть следующее:
- репертуар и расписание проката кинотеатра должен кто-то вносить в систему — соответствующую роль назовем «Менеджер»;
- посетитель и кассир должны иметь возможность просматривать расписание, при этом интересно расписание, начиная с некоторого момента времени (например, текущего времени). Составлять оно может по-разному:
- расписание показа всех фильмов, упорядоченное по времени;
- расписание прокатов в отдельных залах кинотеатра;
- расписание проката определенного фильма.
Из этого описания понятны основные функции системы, изображенные на рисунке с помощью нотации диаграммы прецедентов UML. На диаграмме не отображена роль администратора базы данных, так как администратор обычно взаимодействует с системой не через интерфейс, а через выполнение SQL-запросов.

Несмотря на то, что мы не будет разрабатывать интерфейс информационной системы и текстовые описания прецедентов, дальше нас будут интересовать данные, необходимые для выполнения того или иного прецедента, а для этого надо выделить и описать сущности. Иначе, невозможно определить «какие данные должен вводить менеджер при добавлении фильма». Основные сущности, данные которых потребуются во время работы, показаны на рисунке, при этом используется нотация диаграммы классов UML. Каждый прямоугольник соответствует одной сущности, внутри записаны поля и типы данных.

Каждая сущность, кроме hall_row содержит поле id, которое идентифицирует объект. У сущности hall_row поле id не нужно, так как в одном и том же зале кинотеатра (id_hall) не могут повторяться номера рядов (number).
Когда пользователь выберет зал и прокат — система должна отобразить заполненность зала, при этом надо отобразить конфигурацию зала с пометкой занятых и свободных мест. Под конфигурацией зала тут имеется ввиду, что разные залы имеют разный размер, а ряды зала могут иметь различное количество мест. Поэтому в базе данных зал (hall) составляется из рядов (hall_row), одним из параметров которых является вместимость (capacity).
Вставка рисунка или объекта
Создание других таблиц для этой базы данных — аналогичное.
Создайте еще 5 таблиц самостоятельно.
Вставка в запись рисунка или объекта
Рисунок или объект добавляется из имеющегося файла либо создается в приложении OLE (например, в MS Paint), а затем вставляется в текущую запись.
Рассмотрим размещение объекта OLE на примере поля Фотография начальника в таблице Преподаватели. Фотографии хранятся в формате графического редактора Paint в файлах с расширением .bmp. Если рисунка в вашем файле нет, то создайте его самостоятельно и сохраните.
- В окне базы данных установите курсор на таблице Преподаватели и нажмите кнопку Открыть
- Заполните строки (записи) открывшейся таблицы данными в соответствии с названиями столбцов (полей)
- Для размещения поля Фотография начальника выполните внедрение объекта OLE в файл базы данных. Установите курсор в соответствующее поле таблицы. Выполните команду меню Вставка|Объект
- В окне Вставка объекта выберите тип объекта Paintbrush Picture и установите флажок Создать из файла
- В этом окне можно ввести имя файла, содержащего фотографию.
- Для просмотра внедренного объекта установите курсор в соответствующее поле и дважды щелкните кнопкой мыши
- Чтобы вернуться из программы Paint, выполните команду Файл|Выход и возврат к таблице Преподаватели.
Размещение данных типа МЕМО в таблице
В таблице ПРЕДМЕТ предусмотрено поле ПРОГРАММА, которое будет содержать длинный текст – краткую программу курса. Для такого поля выберите тип данных ПолеМЕМО.
БД из трех таблиц
Сначала необходимо спроектировать структуру базы данных. Например, БД «Учеба».
В ней будет 3 таблицы с полями (полужирным начертанием выделены ключевые поля):
1. «Список курсантов» — №, фамилия, имя, день рождения, пол, улица, дом, кв, группа.
2. «Группы» — номер группы, название группы, преподаватель.
3. «Успеваемость» — код, фамилия, имя, любые 6 предметов.
Ключевые поля можно сделать тип счетчик или числовой.
Откройте новую базу данных Microsoft Access
Сохраните ее в своей папке с именем «Учеба».
Таблицы в ней создадим в режиме Конструктор.
Таблицы заполните произвольными 20 строками в режиме таблицы.
Создадим схему базы данных для данных таблиц во вкладке Работа с базами данных.
Чтобы создать схему данных, надо поочередно выбрать таблицы и протянуть связи левой кнопкой мыши от одной таблицы к другой. В открывшемся окне нажать Ок, поставив галочки в полях таблички.
Таблицы «Группы» и «Список учеников» связать связью «один-ко-многим», а таблицы «Список учеников» и «Успеваемость» — связью «один-к-одному». Таблицы «Группы» и «Успеваемость» напрямую не связаны.
Задание.
Запрос выполняется на вкладке Создание. Выполнить запрос для выделения учащихся (их группу и преподавателей), у которых одновременно экзаменационный балл по химии меньше 75 и больше 50, а по информатике балл меньше 80 и больше 60. Предоставь результат для проверки.
Концептуальная модель базы данных
Под концептуальной моделью понимают отражение предметной области для разрабатываемой базы данных. Если не вдаваться в теорию, то речь идёт о некой диаграмме с общепринятыми обозначениями:
— вещи обозначаются прямоугольниками;
— атрибуты объекта овалами;
— связи в таблицах ромбами;
— мощность и направление связей стрелками (одинарными, двойными).
Делая поставку, поставщик подтверждает её документами. Аналогично и с покупателем. Таким образом, и поставку, и покупку можно рассматривать в качестве самостоятельных объектов.
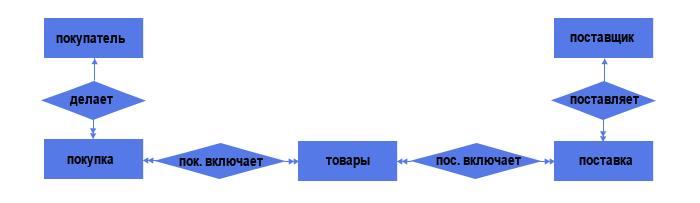
Итого 5 объектов и 4 связи. Из них:
— 2 связи типа «один ко многим» (один поставщик может делать несколько поставок; один покупатель может делать несколько покупок);
— 2 связи типа «многие ко многим» (каждая поставка может включать несколько товаров, причём одинаковый товар может быть в нескольких поставках; аналогичная ситуация по линии «Покупка — Товар»).
Но давайте вспомним, что связи типа «многие ко многим» недопустимы в реляционных моделях данных, поэтому такие связи надо менять на связи типа «один ко многим». Делаем это, добавляя промежуточный объект:
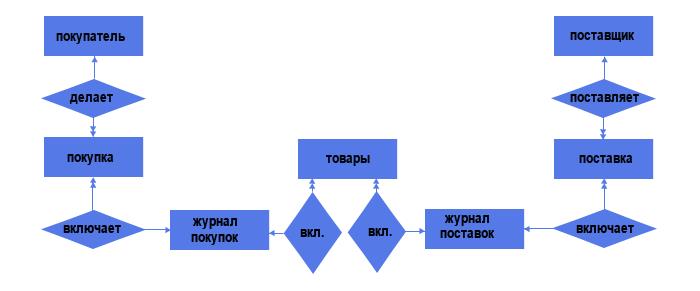
Видим, что в структуре появились ещё 2 объекта — «Журнал поставок» и «Журнал покупок» со связями типа «один ко многим» (каждый журнал может включать несколько поставок/покупок, но каждая поставка/покупка включает лишь один журнал).
Инструкция CREATE SCHEMA
В примере ниже показано создание схемы и ее использование для управления безопасностью базы данных. Прежде чем выполнять этот пример, необходимо создать пользователей базы данных Alex и Vasya, как будет описано в следующей статье (вы можете вернуться к этим примерам позже).
В этом примере создается схема poco, содержащая таблицу Product и представление view_Product. Пользователь базы данных Vasya является принципалом уровня базы данных, а также владельцем схемы. (Владелец схемы указывается посредством параметра AUTHORIZATION. Принципал может быть владельцем других схем и не может использовать текущую схему в качестве схемы по умолчанию.)
Две другие инструкции, применяемые для работы с разрешениями для объектов базы данных, GRANT и DENY, подробно рассматриваются позже. В этом примере инструкция GRANT предоставляет инструкции SELECT разрешения для всех создаваемых в схеме объектов, тогда как инструкция DENY запрещает инструкции UPDATE разрешения для всех объектов схемы.
С помощью инструкции CREATE SCHEMA можно создать схему, сформировать содержащиеся в этой схеме таблицы и представления, а также предоставить, запретить или удалить разрешения на защищаемый объект. Как упоминалось ранее, защищаемые объекты — это ресурсы, доступ к которым регулируется системой авторизации SQL Server. Существует три основные области защищаемых объектов: сервер, база данных и схема, которые содержат другие защищаемые объекты, такие как регистрационные имена, пользователи базы данных, таблицы и хранимые процедуры.
Инструкция CREATE SCHEMA является атомарной. Иными словами, если в процессе выполнения этой инструкции происходит ошибка, не выполняется ни одна из содержащихся в ней подынструкций.
Порядок указания создаваемых в инструкции CREATE SCHEMA объектов базы данных может быть произвольным, с одним исключением: представление, которое ссылается на другое представление, должно быть указано после представления, на которое оно ссылается.
Принципалом уровня базы данных может быть пользователь базы данных, роль или роль приложения. (Роли и роли приложения рассматриваются в одной из следующих статей.) Принципал, указанный в предложении AUTHORIZATION инструкции CREATE SCHEMA, является владельцем всех объектов, созданных в этой схеме. Владение содержащихся в схеме объектов можно передавать любому принципалу уровня базы данных посредством инструкции ALTER AUTHORIZATION.
Для исполнения инструкции CREATE SCHEMA пользователь должен обладать правами базы данных CREATE SCHEMA. Кроме этого, для создания объектов, указанных в инструкции CREATE SCHEMA, пользователь должен иметь соответствующие разрешения CREATE.
