Aso оптимизация. составление семантического ядра для магазинов приложений
Содержание:
- Классификация ключей
- Особенности ядра для Интернет-магазина
- Как проверить частоту запросов и их конкурентность
- Что такое семантическое ядро простыми словами
- Как использовать готовое семантическое ядро на практике
- Сервисы для парсинга и кластеризации семантического ядра
- Группировка семантического ядра для информационного сайта
Классификация ключей

Существуют разные типы поисковых словосочетаний. Определим каждые из них.
По частотности
Выделяют:
- микронизкочастотные;
- низкочастотные;
- среднечастотные;
- высокочастотные.
Если брать данные из Вордстата, то ВЧ имеют более 10 тысяч показов, СР — от 1 тыс., НЧ — от 100, МНЧ — менее 100. Все зависит от специализации и тематики. Как подобрать частотность запросов семантического ядра?
Высокочастотные — наиболее конкурентные. С ними советуют сначала не работать, потому что по ним продвигаться очень сложно. Проще ориентироваться на первые два типа. С НЧ и МНЧ следует только доработать товар, сделать контент более полезным, добавить информацию о доставке и гарантиях, прописать метатеги — и клиент уже будет в ТОПе по этим ключевым словам.
Далее переходят к СЧ. С ними мало прорабатывать структуру, согласно полученным данным. Нужно еще подключить верстальщиков и программистов, чтобы наполнить страницу и сделать ее соответствующего вида. Иногда эти действия не требуют даже переходить к ВЧ, так как сайт в любом случае появляется в ТОПе.
Благодаря исследованиям, известно, что высокочастотные дают всего десять процентов трафика, когда низкочастотные и микронизкочастотные — 70%.
По бизнес-показателям
Второй тип — некоммерческие — по ним люди ищут информацию ради ее изучения, без покупки и заказа.
Пример коммерческих слов:
Некоммерческие запросы:
- что подарить сыну
- санкт-петербург достопримечательности
- характеристика айфона 10
По геозависимости

Здесь также два типа. Есть геозависимые и геонезависимые. Если вводим первые, то поисковая выдача будет отличаться в зависимости от разных регионов, то есть от местоположения пользователя. Если вводим вторые, то результат в поисковике не будет различаться от города.
Это логично. Ведь если продвигается сайт цветов по Санкт-Петербургу, то в поиске не должны предлагаться варианты из Москвы. И наоборот. Все зависит от текущего местоположения, которое определяет браузер.
Примеры геозависимых запросов:
- купить велосипед
- кафе теремок график
- кинотеатры фильмы афиша
Варианты геонезависимых ключей:
- как готовить оладушки
- сериал смотреть онлайн
- купить велосипед в Москве
Логично, что если вы указываете название города, то конкуренция у вас формируется только в рамках населенного пункта. Сложнее конкурировать по независимым от местоположения фразам, ведь показывают все варианты на вашем языке со всего мира.
По типу
Существует четыре вида по данной классификации. Медиазапросы — по ним ищут фото, аудио, видео.
Пример:
- радио слушать онлайн
- смотреть сериал странные дела онлайн
- скачать песню Элтона Джона
Подобные ключи используются при продвижении, если вы можете предложить соответствующий контент. Однако чаще юзеры кликают на Ютуб, Я.Картинки или онлайн-кинотеатры.

Транзакционные — поиск товаров и услуг для покупки. Они полностью аналогичны коммерческим. Чтобы вывести в ТОП сайт по таким словам, нужно указать на страницах цены, создать корзину, ссылку на возможные варианты оплаты и доставки, наполнить каталог карточками товаров с изображениями и описанием. Однако часто поисковики стараются, чтобы по запросам выводились на первое место агрегаторы.
Поэтому добиться первой строчки практически нереально.
Навигационные — ищут сайт, место, событие.
Пример:
- гугл
- риф 2020
- адрес зоопарка Москва
Такие слова также используются для продвижения, если информация с веб-ресурса будет полезна по запросу в поисковике. Однако чаще подобные словосочетания собирают, если планируют продвигаться с помощью контекстной рекламы.
Информационные — по ним осуществляется поиск информации. Они используются на сайтах со статьями или новостями. Обычно над подобными текстами работают редакторы, объем может достигать 20 тысяч символов
При этом важно на таких страницах размещать схемы, красивые изображения, подчеркивать все видеороликами
Пример:
- рецепты пельменей
- город лиссабон
- история князя олега
Другие виды ключевых слов

Пример:
- ред булл
- самсунг
- зара
Нечеткие — те, которые заданы без цели. Поисковики не могут понять, что показать на них пользователю. Чаще всего в поиске просят дописать или предлагают тематические статьи. В России есть технология “Спектр” от поисковика Яндекс, которая подтягивает подобные запросы по разной информационной выдачи.
Например:
- мадагаскар — может быть остров, мультфильм, тур
- король — определение, фильм, сериал, нынешняя династия
Есть еще брендовые — те, в составе которых есть марка или название компании. Например:
- пудра avon
- машина лада
- наушники сяоми
Чтобы им соответствовать, требуются карточки товаров именно данного бренда, также он должен быть в описании, метатегах, заголовках и характеристике.
Особенности ядра для Интернет-магазина
Примечание: Уникальные запросы — это фразы, которые вбивали в строку поиска всего 1 раз. Статистики по ним нету, так как в предыдущие и последующие месяцы их частотность равна нулю. Обычно, это длинные и конкретные запросы.
Что делать в таком случае? Многие рекомендуют собирать огромное семантическое ядро с десятками тысяч низкочастотников. Сложность заключается в том, что работать с такой семантикой крайне сложно. Мы предлагаем немного иной подход.
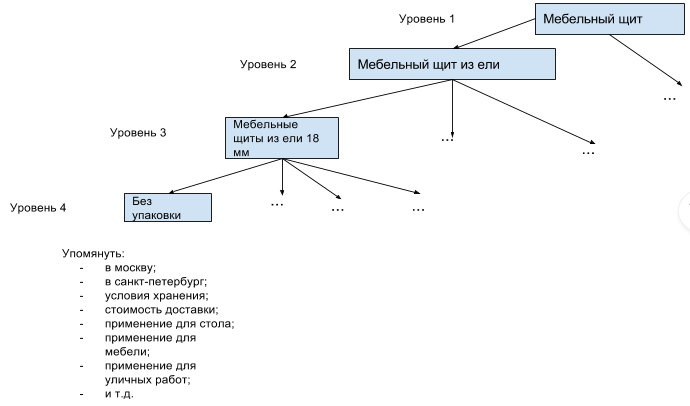
В ядре необходимо отразить дерево всех основных ключевых запросов с частотностью до 5-10 показов. А вместо очень низкочастотных запросов просто выписать слова, которые необходимо упомянуть в тексте и тэгах. Огромное количество низкочастотников формируется из достаточно небольшого количества слов.
Таким образом, Вы сможете упомянуть в описании товара большинство слов, которые формируют низкочастотные запросы. При этом, ядро будет наглядным и структурированным. Выглядеть это может таким образом:
Как проверить частоту запросов и их конкурентность
Прежде всего, в семантическое ядро сайта нужно включить все типы частотных запросов. Исключить можно НЧ запросы с показателем 10 и менее запросов в месяц. Если у вас магазин, то 5 и менее запросов в месяц.
Чтобы проверить частоту запросов пользователями в месяц, для начала, освойте работу с простыми серверами подбора ключевых слов:
- Яндекс-Wordstat;
- Google-AdWords.
Яндекс — Wordstat.yandex
Для Рунета, этот сервис наиболее подходящий. Он простой понятный без заморочек. Выдает нужные показатели, есть минимальные фильтры, есть недостатки, которые не мешают, например, нет экспорта результатов.
Как работать с Wordstat.yandex
- Авторизуйтесь в Яндекс. Войдите на сервис (https://wordstat.yandex.ru/);
- В форму поиска введите нужное ключевое слово (фразу) общего характера (ВЧ запрос);
- Wordstat.yandex откроет вам большую таблицу, где будут показаны и ваш ВЧ запрос и все включающие и похожие запросы, которые делались в поисковике Яндекс за последний месяц. Можете уточнить запрос по региону, для этого есть фильтр.
 Составление семантического ядра на Яндекс подбор слов
Составление семантического ядра на Яндекс подбор слов
В левой таблице вы видите все запросы с вашим ключевым словом, включая фразы с этим словом, которые пользователи вводили в поисковик.
В правой таблице, запросы близкие к вашим, причем эти запросы делались людьми, искавшими ваше ключевое слово. Эти фразы можно использовать в статьях, если вы подбираете ключевик отдельной статьи. Для общего семантического ядра эти фразы не нужны.
Но это еще не все. Можно использовать язык поисковых запросов. Если в поиск Wordstat.yandex ввести туже ключевую фразу в кавычках, сервис выдаст вам количество точных запросов, по этой фразе. Например, вводим запрос мебель, теперь в кавычках «мебель» (копирование фразы не пройдет, набираем руками): получаем, только статистику точных запросов – мебель.

Можно пойти дальше. Выясняем, сколько людей запрашивали конкретную фразу, без дополнительных словесных вхождений. Делаем такой запрос: «!мебель !для !дома». Получаем точное количество запросов, точной фразы – мебель для дома.

Запросы с кавычками и с восклицательным знаком используем, для тонкой коррекции семантического ядра. А пока, нас интересует первый анализ, со всеми возможными формами.
К сожалению, у Wordstat.yandex нет экспорта найденных запросов, поэтому таблицу запросов копируем и экспортируем в Excel вручную.
В приведенном примере, запроса (мебель), Wordstat.yandex выдал 40 страниц. Дальше аналитическая работа. Из всех найденных вариантов отбираете нужные вам запросы, они же ключевые слова вашего семантического ядра.

Можно пойти таким путем:
Из первого анализа по общей фразе без кавычек, подобрать ключевые фразы для разделов сайта
Например: мебель – разделы по Wordstat.yandex: корпусная мебель, кухонная мебель, мебель гостиной, детская мебель и т. д.
- Далее для каждого названия раздела подбираем свой список фраз;
- Если есть подразделы, для них тоже делаем анализ;
- В результате получаем древовидную структуру ключевых слов и фраз семантического ядра сайта.
Что такое семантическое ядро простыми словами
Как это ни странно, но семантическое ядро – это обычный excel файл, в котором списком представлены ключевые запросы, по которым вы (или ваш копирайтер) будете писать статьи для сайта.
Вот как, например, выглядит мое семантическое ядро:
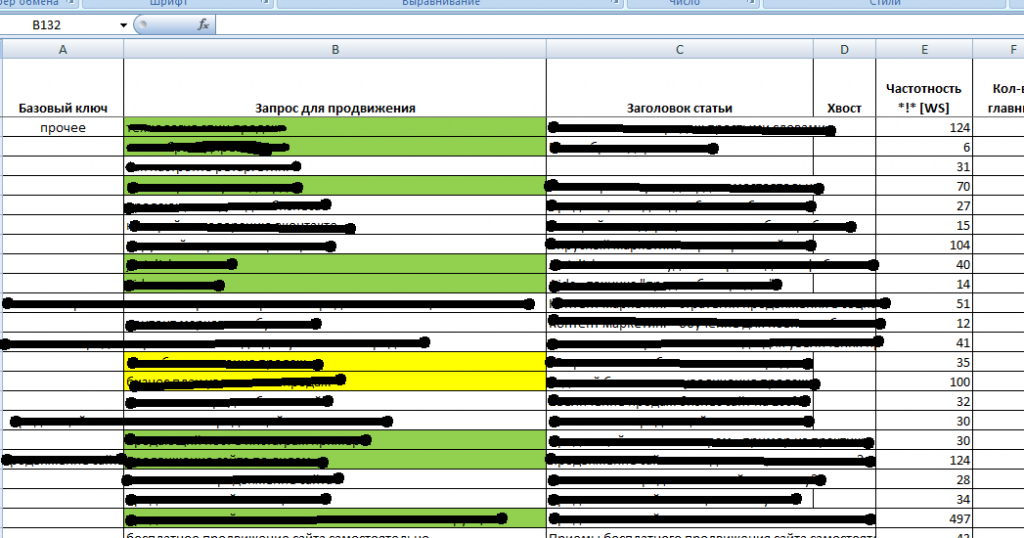
Зеленым цветом у меня помечены те ключевые запросы, по которым я уже написал статьи. Желтым – те, которым статьи собираюсь написать в ближайшее время. А бесцветные ячейки – это значит, что до этих запросов дело дойдет немного позже.
Для каждого ключевого запроса у меня определена частотность, конкурентность, и придуман “цепляющий” заголовок. Вот примерно такой же файл должен получиться и у вас. Сейчас у меня СЯ состоит из 150 ключевиков. Это значит, что я обеспечен “материалом” минимум на 5 месяцев вперед (если даже буду писать по одной статье в день).
Чуть ниже мы поговорим о том, к чему вам готовиться, если вы вдруг решите заказать сбор семантического ядра у специалистов. Здесь скажу кратко – вам дадут такой же список, но только на тысячи “ключей”
Однако, в СЯ важно не количество, а качество. И мы с вами будем ориентироваться именно на это
Зачем вообще нужно семантическое ядро?
А в самом деле, зачем нам эти мучения? Можно же, в конце концов, просто так писать качественные статьи, и привлекать этим аудиторию, правильно? Да, писать можно, а вот привлекать не получится.
Главная ошибка 90% блогеров – это как раз написание просто качественных статей. Я не шучу, у них реально интересные и полезные материалы. Вот только поисковые системы об этом не знают. Они же не экстрасенсы, а всего лишь роботы. Соответственно они и не ставят вашу статью в ТОП.
Здесь есть еще один тонкий момент с заголовком. Например, у вас есть очень качественная статья на тему “Как правильно вести бизнес в “мордокниге”. Там вы очень подробно и профессионально расписываете все про фейсбук. В том числе и то, как там продвигать сообщества. Ваша статья – самая качественная, полезная и интересная в интернете на эту тему. Никто и рядом с вами не валялся. Но вам это все равно не поможет.
Почему качественные статьи вылетают из ТОПа
Представьте, что на ваш сайт зашел не робот, а живой проверяльщик (асессор) с Яндекса. Он понял, что у вас самая классная статья. И рукам поставил вас на первое место в выдаче по запросу “Продвижение сообщества в фейсбук”.
Знаете, что произойдет дальше? Вы оттуда все равно очень скоро вылетите. Потому что по вашей статье, даже на первом месте, никто не будет кликать. Люди вводят запрос “Продвижение сообщества в фейсбук”, а у вас заголовок – “Как правильно вести бизнес в “мордокниге”. Оригинально, свежо, забавно, но… не под запрос. Люди хотят видеть именно то, что они искали, а не ваш креатив.
Соответственно, ваша статья будет вхолостую занимать место в ТОП выдачи. И живой асессор, горячий поклонник вашего творчества, может сколько угодно умолять начальство оставить вас хотя бы в ТОП-10. Но не поможет. Все первые места займут пустые, как шелуха от семечек, статейки, которые друг у друга переписали вчерашние школьники.
Зато у этих статей будет правильный “релевантный” заголовок – “Продвижение сообщества в фейсбук с нуля” (по шагам, за 5 шагов, от А до Я, бесплатно и пр.) Обидно? Еще бы. Ну так боритесь против несправедливости. Давайте составим грамотное семантическое ядро, чтобы ваши статьи занимали заслуженные первые места.
Еще одна причина начать составлять СЯ прямо сейчас
Есть еще одна вещь, о которой почему-то люди мало задумываются. Вам надо писать статьи часто – как минимум каждую неделю, а лучше 2-3 раза в неделю, чтобы набрать побольше трафика и побыстрее.
Все это знают, но почти никто этого не делает. А все потому, что у них “творческий застой”, “никак не могут себя заставить”, “просто лень”. А на самом деле вся проблема именно в отсутствие конкретного семантического ядра.
Наше СЯ – это как контент-план для социальных сетей. То есть там написано конкретно, что мы будем делать в ближайшие 2-3 месяца. Нам не надо будет садиться с утра и начать выдумывать тему для нового поста. У нас все придумано, продумано и прочитано.
Именно это и спасет вас от так называемого “творческого кризиса”. Когда вы точно знаете, что вам делать – становится гораздо легче. Поэтому ни в коем случае не пропускайте этап создания семантического ядра (каким бы муторным вам это дело не показалось). Потом вам все равно придется подбирать темы и запросы, но только потратите вы на это в десять раз больше времени и сил.
А теперь. собственно, давайте разберем, как правильно составить семантическое ядро с нуля.
Как использовать готовое семантическое ядро на практике
Чтобы иметь хоть какие-то ориентиры в вашей SEO работе, лучше предварительно проверить релевантность сайтов из ТОП выдачи по конкретным запросам.
Например, если вы пишите текст по низкочастотной фразе «недорогое продвижение сайта ссылками», то сначала просто введите ее в поиске и оцените ТОП-5 сайтов в выдаче с помощью сервиса оценки релевантности.
Если сервис показал, что сайты из ТОП-5 по запросу «недорогое продвижение сайта ссылками» имеют релевантность от 18% до 30%, то вам нужно ориентироваться на эти же процентные показатели. Еще лучше – создать уникальный текст с ключевыми словами и релевантностью примерно 35-50%. Немного обойдя конкурентов на данном этапе, вы заложите неплохую основу дальнейшего продвижения.
ВАЖНО: использование семантического ядра на практике подразумевает, что одно фразе соответствует одна уникальная страница ресурса. Максимум здесь – это 2 запроса на одну статью
Чем полнее раскроется семантическое ядро, тем информативней будет ваш проект. Но если вы не готовы к длительной работе и тысячам новых статей, не нужно браться за широкие тематические ниши. Даже узкая специализированная область, раскрытая на 100%, принесет больше трафика, чем недоделанный большой сайт.
Например, вы могли бы взять за основу сайта не высокочастотный ключ «продвижение сайта» (где колоссальная конкуренция), а фразу с частотой поменьше и специализацией поуже – «статейное продвижение сайта» или «продвижение ссылками», но раскрыть эту тему по максимуму во всех статьях виртуальной площадки! Эффект при этом будет выше.

Сервисы для парсинга и кластеризации семантического ядра
Для сбора и кластеризации семантики есть много платных и бесплатных инструментов. Мы уже упоминали несколько сервисов и сейчас остановимся на них подробнее.
Key Collector
Автоматизированный сервис для подбора семантического ядра. Умеет собирать ключи через «Яндекс.Вордстат», парсить поисковые подсказки, выгружать данные с Google Ads и сервисов аналитики, чистить семантику от стоп-слов, дублей и сезонных запросов, делать фильтрацию по частотности. Частотность Key Collector собирает в Yandex Direct, Google Ads, LiveInternet, Rambler Adstat и APIShop.com.
Главные достоинства Key Collector — разнообразные источники парсинга, большая глубина сбора, возможность группировки собранной базы. Из минусов SEO специалисты отмечают медленную работу, особенно при увеличенной глубине сбора, и необходимость покупки антикапч.

Интерфейс Key Collector
Программа платная, работает по лицензии. Стоимость лицензии зависит от статуса покупателя: физическому лицу бессрочная лицензия обойдется в 2 200 рублей, организации придется заплатить 2 300 рублей.
MOAB.Tools Семантика
Это онлайн-сервис, который парсит до четырех миллионов фраз в час и собирает для семантического ядра запросы из Wordstat и подсказок, в том числе запросы с длинным полным хвостом спецификаторов. При поиске нет проблем с капчей, можно выбрать регионы, найти ультранизкочастотные запросы и интегрировать результат с Key Collector. Удобно, что сервис сразу проверяет частотность.

Работа парсера MOAB.Tools
Инструмент платный, но в тарифе Free первые 5 000 фраз можно собрать бесплатно. Тариф Mini стоит 1 299 рублей и рассчитан на ядро до 50 000 фраз. Для крупных проектов разработан тариф Pro, с которым за 6 099 рублей можно найти до 500 000 фраз.
«Словоеб»
Сервис позиционируется как бесплатная альтернатива Key Collector. У программы похожий интерфейс и принцип работы, но возможности парсинга ограничены результатами «Вордстат», Rambler.Adstat и поисковыми подсказками «Яндекс» и Google. Частотность фраз программа тоже проверяет только по «Вордстат».

Работа программы «Словоеб»
По сути, «Словоеб» выполняет базовую работу по сбору семантики в «Яндекс.Вордстат», но в автоматическом режиме. За 10-15 минут он собирает несколько тысяч запросов, что в разы быстрей ручного сбора.
Yandex Wordstat Assistant
Браузерное расширение для упрощения работы с «Вордстат». Бесплатный сервис, который копирует и сохраняет ключевые слова из «Яндекс.Вордстат» в таблицы Excel. Умеет сортировать запросы по частотности, алфавиту или порядку добавления. Автоматически ищет дубли и позволяет добавлять ключи вручную.

Составление семантического ядра с помощью браузерного расширения
Расширение бесплатное, устанавливается для Google Chrome, Opera, Mozilla Firefox и «Яндекс.Браузер».
Serpstat
Мультиинструментальный сервис для работы с семантическим ядром, кластеризации и SEO анализа.

Интерфейс сервиса Serpstat
При сборе семантики учитывает частотность и конкурентность запросов по шкале от 1 до 100, показывает сложность продвижения. Может работать с региональной выдачей и сравнивать результаты с сайтами конкурентов. Особенно удобно, что Serpstat группирует ключевые слова по страницам и рекламным кампаниям с учетом однородности.
У сервиса есть бесплатная версия с ограниченным функционалом. Подписки оформляются на месяц или год. Самая недорогая стоит 55$ в месяц.
Rush Analytics
Сервис автоматизации парсинга и кластеризации семантического ядра. Собирает запросы и показывает их частотность на основе данных «Яндекс.Вордстат» и Google Ads, ищет подсказки в «Яндекс», Google и YouTube. Умеет кластеризовать ключевые слова методом Soft и Hard, автоматически создает структуру сайта.

Интерфейс Rush Analytics
Бесплатная версия с ограниченным функционалом доступна семь дней. Минимальный тариф стоит 500 рублей в месяц.
Готовое ядро выглядит как электронная таблица, где по каждой ключевой фразе указана базовая (по всем вариантам использования ключевого слова) и точная (без словоформ) частотность, а для каждого кластера — продвигаемая страница.
Данные в таком формате можно сразу использовать для SEO и контекстной рекламы:
- Разрабатывать или оптимизировать структуру сайта.
- Отбирать перспективные запросы с низкой стоимостью клика и запускать контекстную рекламу с дешевым целевым трафиком.
- Составлять контент-план на несколько лет или месяцев.
- Делать технические задания для контентного наполнения или оптимизации текущего контента.
Группировка семантического ядра для информационного сайта
При группировке семантического ядра я руководствуюсь здравой логикой, сравнивая её с выдачей.
Для информационных сайтов я не вижу смысла прибегать к кластеризации и четко следовать её требованиям. Поисковая система постоянно обучается и совершенствуется. Сегодня она показывает, что запросы “черный хлеб” и “ржаной хлеб” это разные продукты, а завтра покажет правильно, что это одно и тоже.
Итак, в KeyCollector у нас есть чистенький список запросов и мы собрали по нему данные из поисковой выдачи. Чтобы облегчить работу, группируем ядро средствами KeyCollector.
Заходим в анализ групп, ставим по поисковой выдаче Яндекс, сила 2. Обновляем группировку и экспортируем результаты в Excel. Таким способом у нас получилась группировка исходя из данных поисковой системы Яндекс. Но, как я писал уже выше, что надо следовать преимущественно логике и свои предположения проверять в поисковой системе, поэтому в некоторых группах могут быть запросы, которые вообще никак к ней не относятся. Их надо все пересмотреть и доработать.
Таким способом у нас получилась группировка исходя из данных поисковой системы Яндекс. Но, как я писал уже выше, что надо следовать преимущественно логике и свои предположения проверять в поисковой системе, поэтому в некоторых группах могут быть запросы, которые вообще никак к ней не относятся. Их надо все пересмотреть и доработать.
Чтобы легче было дорабатывать, лучше всего оставить несколько столбцов только с нужными данными. Обычно я оставляю: базовую частотность, точную, KEI по полноте охвата, конкуренцию.
Покажу группировку на примере, чтобы было наглядно. Например, мы создаем сайт посвященный рецептам блинов. Мы увидели, что есть множество запросов связанные с молоком. Решаем, что будем делать отдельную рубрику “Рецепты блинов на молоке”. На примере этой рубрики и рассмотрим группировку.
Смотрим первую группу: Видим, что в группу “простого рецепта” попал общий запрос “тесто для блинов на молоке рецепт” – этим запросом человек не обязательно хочет найти простой рецепт. По логике, лучше всего этот запрос перенести в общую группу, которая будет вести на категорию со всеми рецептами блинов на молоке.
Видим, что в группу “простого рецепта” попал общий запрос “тесто для блинов на молоке рецепт” – этим запросом человек не обязательно хочет найти простой рецепт. По логике, лучше всего этот запрос перенести в общую группу, которая будет вести на категорию со всеми рецептами блинов на молоке.
Но так же следует и глянуть выдачу в яндексе, что там вообще находится. Смотрим и видим, что действительно в выдаче по этому запросу есть пара страниц, которые ведут не на один рецепт, а на множество. Так же видим, что в выдаче большинство страниц ведут на один рецепт, при этом на рецепты тонких блинов. Но это же тупо, человек не обязательно хочет тонкие блины. Если бы он хотел тонкие блины, то он ввёл это в запрос. А у нас общий запрос, мы должны показать ему общую страницу, а он уже на ней должен определиться какие блины он хочет на молоке – с простым рецептом или тонкие блины или в дырочку или еще какие-то. В общем я мыслю так.
Переносим лишний запрос в другую группу, а точнее создаем выше новую “Рубрика рецепты блинов на молоке” отмечаем её другим цветом, потому что это рубрика, а в неё уже будут входить рецепты в нашем случае “простой рецепт блинов на молоке”. Тем самым у нас создается структура внутри семантики.
Все данные по группе суммируем. Бюджет можно выводить средним числом, так как это взаимодополняемые запросы, вы все их продвигаете на одной странице, а не по отдельности.
KEI1 (полнота охвата) выводим по уже известной нам формуле:
/*100
Получается вот такая красота: Данные по «рубрике рецепты блинов на молоке» еще не суммируем, потому что скорее всего туда добавятся еще запросы. Но и не исключено, что в “простой рецепт блинов на молоке” тоже еще добавятся запросы.
Данные по «рубрике рецепты блинов на молоке» еще не суммируем, потому что скорее всего туда добавятся еще запросы. Но и не исключено, что в “простой рецепт блинов на молоке” тоже еще добавятся запросы.
К тому же тут еще и затесался запрос с “тонкие блины”. Его тоже отдельно, он будет страницей к рубрике “рецепт блинов на молоке и воде”
И таким вот способом перерабатываем все ядро, в итоге получается вот так: Красным шрифтом помечены дополнительные фразы, которые имеют приставки фото, видео. Для нас это не совсем актуальные фразы. Эти фразы конкурируют с сервисами поисковых систем и трафику по ним очень мало. Но эти фразы подходят по нашему смыслу, поэтому мы их добавляем в группу.
Красным шрифтом помечены дополнительные фразы, которые имеют приставки фото, видео. Для нас это не совсем актуальные фразы. Эти фразы конкурируют с сервисами поисковых систем и трафику по ним очень мало. Но эти фразы подходят по нашему смыслу, поэтому мы их добавляем в группу.
Каждая группа помечена своим цветом. Цвет является структурой сайта, то есть уровнем вложенности страницы.
Например, если бы у нас был запрос “простой рецепт блинов на скисшем молоке”. То он бы уже шёл, как подгруппа к группе “блины на скисшем молоке” и естественно был бы выделен другим цветом. Выглядело бы это вот так: Думаю, идея с цветом понятна. Вот так создается семантика и удобная, понятная структура сайта, где все логично и имеет свой уровень вложенности.
Думаю, идея с цветом понятна. Вот так создается семантика и удобная, понятная структура сайта, где все логично и имеет свой уровень вложенности.
Новые или измененные рубрики добавляем в нашу структуру в xmind.
В общем, чтобы нормально разгруппировать ядро необходимо мыслить логически, вставать на место посетителя, отвечать на вопрос – что он хочет увидеть, введя этот запрос? А также смотреть выдачу по этому запросу и принимать решение, как поступить наилучшим образом.
