30+ парсеров для сбора данных с любого сайта
Содержание:
- Почему нельзя собрать бесплатно и вручную
- Принципы форматирования#
- Парсеры сайтов в зависимости от используемой технологии
- Как попасть в поисковые подсказки Яндекс?
- Парсеры поисковых систем#
- Примеры запросов#
- Примеры запросов#
- Пошаговая инструкция по работе с Yandex Wordstat
- Другие эксперименты с дизайном
- Знакомство с сервисом Yandex Wordstat
- Сетевые истории
- Сбор поисковых подсказок Яндекса и Гугла
- Варианты разбора
- Как подпасть в подсказки Яндекс: «белые методы»
- Варианты вывода результатов#
- Заключение
Почему нельзя собрать бесплатно и вручную
Теоретически собрать подсказки можно и бесплатно, и вручную, но зачем так мучиться?
Если из Яндекс.Вордстата запросы можно вносить в эксель по принципу «копировать-вставить», то с поисковыми подсказками так не получится. При попытке выделить что-то из списка выделяется набранный вами запрос. Остается только вручную переписывать все запросы, а это просто адский труд. Особенно, когда нужны сотни и тысячи ключевых слов и фраз.
Сбор ключевых слов и фраз происходит «в облаке», не нужно ничего скачивать и устанавливать. Во время парсинга даже можно закрыть браузер, все идет в фоновом режиме. Капчи и фейковые аккаунты тоже не нужны.
Главное преимущество инструмента от Click.ru перед конкурентами – стоимость сбора подсказок в 3–5 раз дешевле, чем у конкурентов.
Принципы форматирования#
После того как парсер собрал данные в простых результатах и массивах, их необходимо отобразить(сохранить в файл) в нужном формате. Для удобства и функциональности в A-Parser’е используется Шаблонизатор Template Toolkit. Разберем часто используемые конструкции, для этого воспользуемся инструментом Тестирование шаблонов. Выберем проект для парсера SE::Google:

На скриншоте представлены 3 поля:
- JSON — внутреннее представление данных в парсере
- Шаблон — шаблон, по которому происходит форматирование результата
- Результат — непосредственно преобразованные данные по указанному шаблону, именно в таком виде результат будет записан в файл
Изменяя шаблон мы можем менять вид результата, рассмотрим следующий шаблон:
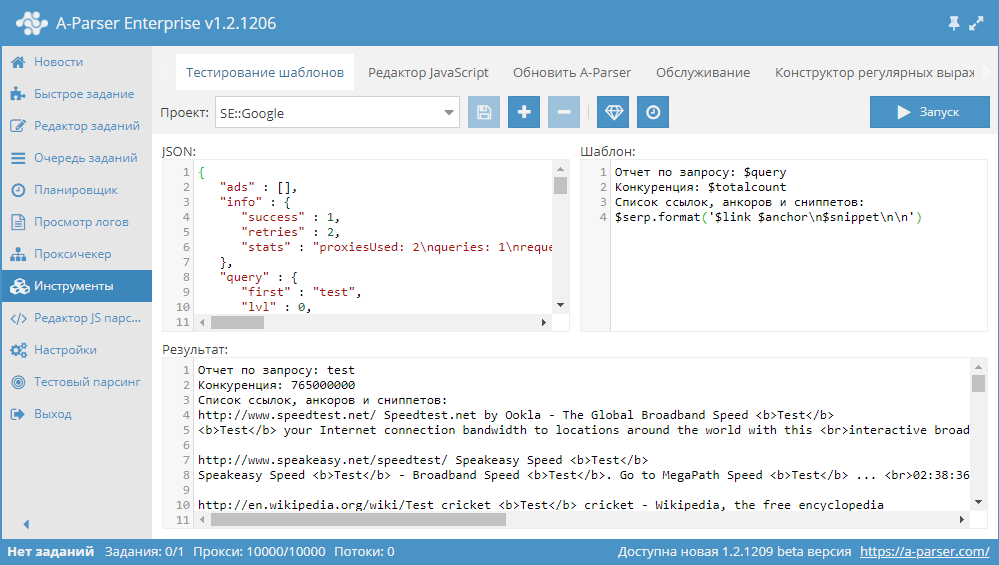
Текст в поле Шаблон:
Отчет по запросу: $query
Конкуренция: $totalcount
Список ссылок, анкоров и сниппетов:
$serp.format(‘$link $anchor\n$snippet\n\n’)
Скопировать
Выделим основные правила:
- Обычный текст выводится в результат как есть, без изменений
- Для вывода простых результатов необходимо в нужном месте вывести переменную содержащую нужный результат с префиксом
- Для форматирования массивов используется метод , о нем немного ниже
- отвечает за перенос строки
Форматирование массивов
Форматирование массивов, разберем конструкцию:
$serp.format(‘$link $anchor\n$snippet\n\n’)
Скопировать
Данная запись означает что для массива необходимо вызвать метод с параметром . Метод соединяет в строку все элементы массива по шаблону, указанному в параметре, сам шаблон означает: для каждого элемента массива вывести ссылку и анкор через пробел, затем с новой строки вывести сниппет, после чего идет еще два переноса строки, в результате образующих пустую строку между результатами.
Для использования шаблонизатора нужно вставить теги , и внутри тегов ввести логику которую нужно выполнить.
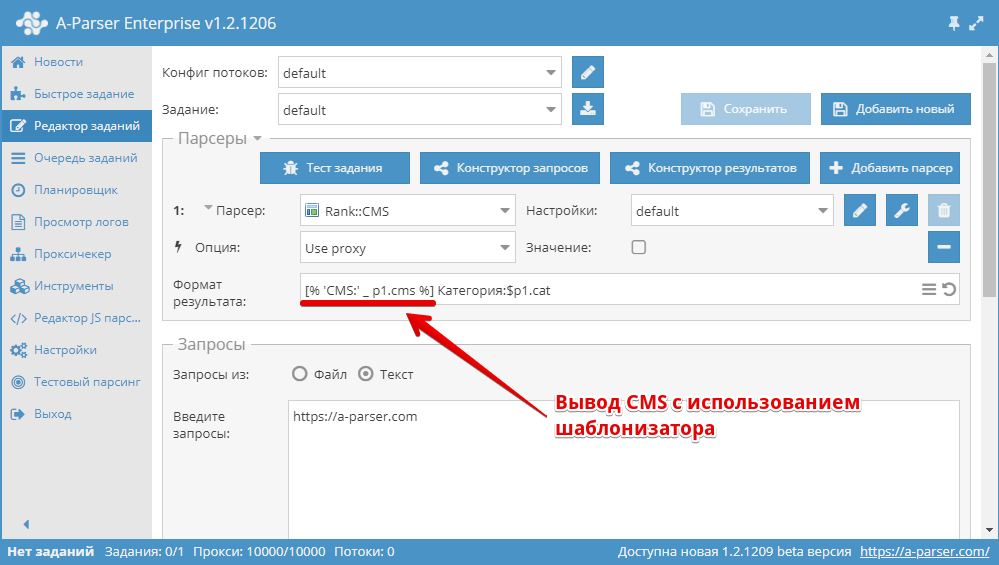
Проход по массиву
Для вывода элементов массива нужно использовать конструкцию :
Скопировать
Парсеры сайтов в зависимости от используемой технологии
Парсеры на основе Python и PHP
Такие парсеры создают программисты. Без специальных знаний сделать парсер самостоятельно не получится. На сегодня самый популярный язык для создания таких программ Python. Разработчикам, которые им владеют, могут быть полезны:
- библиотека Beautiful Soup;
- фреймворки с открытым исходным кодом Scrapy, Grab и другие.
Заказывать разработку парсера с нуля стоит только для нестандартных задач. Для большинства целей можно подобрать готовые решения.
Парсеры-расширения для браузеров
Парсить данные с сайтов могут бесплатные расширения для браузеров. Они извлекают данные из html-кода страниц при помощи языка запросов Xpath и выгружают их в удобные для дальнейшей работы форматы — XLSX, CSV, XML, JSON, Google Таблицы и другие. Так можно собрать цены, описания товаров, новости, отзывы и другие типы данных.
Примеры расширений для Chrome: Parsers, Scraper, Data Scraper, kimono.
Парсеры сайтов на основе Excel
В таких программах парсинг с последующей выгрузкой данных в форматы XLS* и CSV реализован при помощи макросов — специальных команд для автоматизации действий в MS Excel. Пример такой программы — ParserOK. Бесплатная пробная версия ограничена периодом в 10 дней.
Парсинг при помощи Google Таблиц
В Google Таблицах парсить данные можно при помощи двух функций — importxml и importhtml.
Функция IMPORTXML импортирует данные из источников формата XML, HTML, CSV, TSV, RSS, ATOM XML в ячейки таблицы при помощи запросов Xpath. Синтаксис функции:
IMPORTXML("https://site.com/catalog"; "//a/@href")
IMPORTXML(A2; B2)
Расшифруем: в первой строке содержится заключенный в кавычки url (обязательно с указанием протокола) и запрос Xpath.
Знание языка запросов Xpath для использования функции не обязательно, можно воспользоваться опцией браузера «копировать Xpath»:
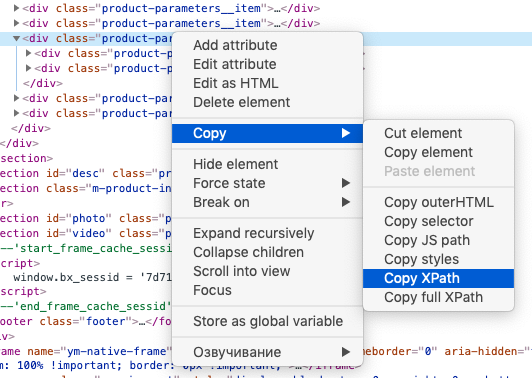
Вторая строка указывает ячейки, куда будут импортированы данные.
IMPORTXML можно использовать для сбора метатегов и заголовков, количества внешних ссылок со страницы, количества товаров на странице категории и других данных.
У IMPORTHTML более узкий функционал — она импортирует данные из таблиц и списков, размещенных на странице сайта. Синтаксис функции:
IMPORTHTML("https://https://site.com/catalog/sweets"; "table"; 4)
IMPORTHTML(A2; B2; C2)
Расшифруем: в первой строке, как и в предыдущем случае, содержится заключенный в кавычки URL (обязательно с указанием протокола), затем параметр «table», если хотите получить данные из таблицы, или «list», если из списка. Числовое значение (индекс) означает порядковый номер таблицы или списка в html-коде страницы.
Как попасть в поисковые подсказки Яндекс?
При формировании подсказок, поисковик учитывает следующие факторы:
1. Язык и геолокацию
Для каждого гео набор подсказок будет отличаться. А язык, который пользователь использует для ввода запроса, определяет семантическое ядро. Также Яндекс формирует группу наиболее популярных пользовательских запросов для каждого региона и показывает их снизу строки. Поэтому набор подсказок для Москвы и Воронежа при одинаковом запросе будет разной.
2. Персонализация
На набор подсказок влияет и опция Яндекса — «Мои находки». Запросы, которые чаще всего вводит пользователь, выделены другим цветом. Это говорит о предпочтениях человека.
3. Поисковые фильтры
Яндекс фильтрует все пользовательские запросы, удаляя из них нецензурную лексику, неточности и низкочастотные ключи. Аудитории доступен набор из 20 миллионов вариантов, которые делятся на группы по семантике и объединяются в синонимы или близкие по смыслу выражения. Например: «новости», «новости России», «новости в мире».

4. Контент
Поисковики учитывают не только количество прямых вхождений слов в запросы, но и как часто фраза встречается внутри контента. Еще индийским блогером Риши Сакхани был проведен эксперимент для Google. Им было сформировано два запроса в Твиттере: «Rishi Sakhani ROFL» и «Rishi Sakhani ha ha ha». Блогер попросил своих подписчиков сделать репосты фраз. В итоге первый вариант оказался в подсказках, второй — нет. Яндекс использует точно такой же алгоритм при формировании набора запросов.
6. Популярность
Яндекс обновляет набор подсказок ежедневно. Те, которые теряют популярность, отсеиваются. У поисковика также есть «быстрые подсказки». Ключевые фразы формируются на основе многочисленных запросов большей части аудитории. Яндекс отслеживает каждые полчаса, какой контент имеет больший охват и предлагает его другим пользователям.
Парсеры поисковых систем#
| Название парсера | Описание |
|---|---|
| SE::Google | Парсинг всех данных с поисковой выдачи Google: ссылки, анкоры, сниппеты, Related keywords, парсинг рекламных блоков. Многопоточность, обход ReCaptcha |
| SE::Yandex | Парсинг всех данных с поисковой выдачи Yandex: ссылки, анкоры, сниппеты, Related keywords, парсинг рекламных блоков. Максимальная глубина парсинга |
| SE::AOL | Парсинг всех данных с поисковой выдачи AOL: ссылки, анкоры, сниппеты |
| SE::Bing | Парсинг всех данных с поисковой выдачи Bing: ссылки, анкоры, сниппеты, Related keywords, Максимальная глубина парсинга |
| SE::Baidu | Парсинг всех данных с поисковой выдачи Baidu: ссылки, анкоры, сниппеты, Related keywords |
| SE::Baidu | Парсинг всех данных с поисковой выдачи Baidu: ссылки, анкоры, сниппеты, Related keywords |
| SE::Dogpile | Парсинг всех данных с поисковой выдачи Dogpile: ссылки, анкоры, сниппеты, Related keywords |
| SE::DuckDuckGo | Парсинг всех данных с поисковой выдачи DuckDuckGo: ссылки, анкоры, сниппеты |
| SE::MailRu | Парсинг всех данных с поисковой выдачи MailRu: ссылки, анкоры, сниппеты |
| SE::Seznam | Парсер чешской поисковой системы seznam.cz: ссылки, анкоры, сниппеты, Related keywords |
| SE::Yahoo | Парсинг всех данных с поисковой выдачи Yahoo: ссылки, анкоры, сниппеты, Related keywords, Максимальная глубина парсинга |
| SE::Youtube | Парсинг данных с поисковой выдачи Youtube: ссылки, название, описание, имя пользователя, ссылка на превью картинки, кол-во просмотров, длина видеоролика |
| SE::Ask | Парсер американской поисковой выдачи Google через Ask.com: ссылки, анкоры, сниппеты, Related keywords |
| SE::Rambler | Парсинг всех данных с поисковой выдачи Rambler: ссылки, анкоры, сниппеты |
| SE::Startpage | Парсинг всех данных с поисковой выдачи Startpage: ссылки, анкоры, сниппеты |
Примеры запросов#
write essay
Football
Waterfall
Speak in english
Cats and dogs
forex
cheap essay
Скопировать
Подстановки запросов
Вы можете использовать для автоматической подстановки подзапросов из файлов, например мы хотим к кажому запросу добавить какой-то список других слов, укажем несколько основных запросов:
essay
article
thesis
Скопировать
В формате запросов укажем макрос подстановки дополнительных слов из файла Keywords.txt, данный метод позволяет увеличить вариативность запросов многократно:
{subs:Keywords} $query
Скопировать
Данный макрос создаст столько же дополнительных запросов сколько их находится в файле на каждый исходный поисковый запрос, что в сумме даст в результате работы макроса.
Например, если в файл Keywords.txt будет содержать:
buy
cheap
Скопировать
В итоге макрос подстановок превратит 3 основных запроса в 6:
buy essay
cheap essay
buy article
cheap article
buy thesis
cheap thesis
Скопировать
Примеры запросов#
write essay
Football
Waterfall
Speak in english
Cats and dogs
forex
cheap essay
Скопировать
Подстановки запросов
Вы можете использовать для автоматической подстановки подзапросов из файлов, например мы хотим к кажому запросу добавить какой-то список других слов, укажем несколько основных запросов:
essay
article
thesis
Скопировать
В формате запросов укажем макрос подстановки дополнительных слов из файла Keywords.txt, данный метод позволяет увеличить вариативность запросов многократно:
{subs:Keywords} $query
Скопировать
Данный макрос создаст столько же дополнительных запросов сколько их находится в файле на каждый исходный поисковый запрос, что в сумме даст в результате работы макроса.
Например, если в файл Keywords.txt будет содержать:
buy
cheap
Скопировать
В итоге макрос подстановок превратит 3 основных запроса в 6:
buy essay
cheap essay
buy article
cheap article
buy thesis
cheap thesis
Скопировать
Пошаговая инструкция по работе с Yandex Wordstat
Для грамотного использования Яндекс Вордстат необходимо:
- Зарегистрироваться и войти в свою почту (аккаунт) на Яндексе;
- Записать в поле запрос и кликнуть «Подобрать».
Если вы не залогинились в своем аккаунте, то Yandex Wordstat при заходе в него предложит вам сделать это.
Давайте пробежимся по функционалу интерфейса.
Под основной строкой для ввода ключевого слова есть три флажка:
- «По словам»;
- «По регионам»;
- «История запросов».
Подробнее работу с каждым из них мы рассмотрим далее.
Справа ссылка «Все регионы» — позволит выбрать и посмотреть статистику ключевика по заданному региону.
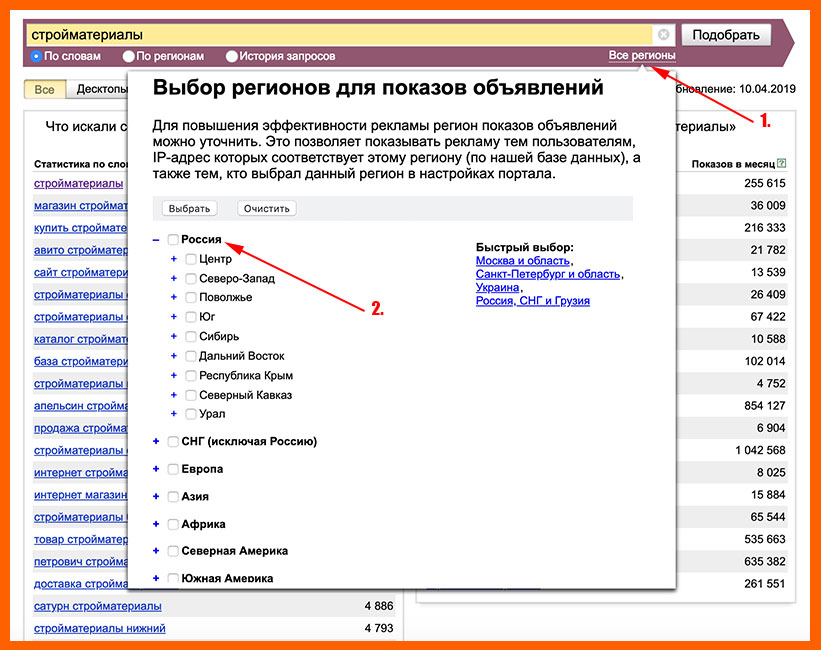
Сбор запросов по словам
Как видно из вышеприведенного скриншота в Яндекс Вордстат этот вариант стоит «по умолчанию». Он показывает статистику запросов по региону, если тот выбран, если нет, то статистика показывается по всем регионам.
Давайте введем в основное поле фразу «Стройматериалы» и посмотрим, что покажет нам Wordstat. Возможно, вам придется ввести капчу. У меня обошлось без этого.
Система выдаст две колонки, которые будут содержать различные вариации заданного ключевого слова.
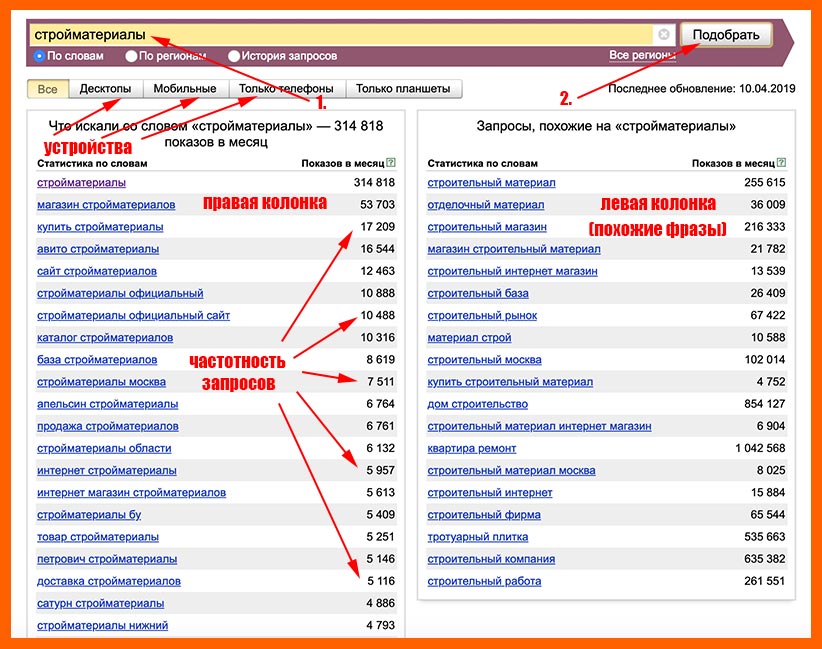
В левом столбце Яндекс Вордстат будут все прямые и непрямые вхождения. Правый — отобразит похожие запросы — «стройматериалы», «строительные материалы», «строительный рынок» и т.д. Т.е. отсюда можно выбрать достаточно интересные ключи для продвижения и этим не стоит пренебрегать.
Цифры, расположенные справа от запросов — это количество показов в месяц. Но это всего лишь прогнозируемый Яндексом результат, который вычисляется из статистики поисковика. Т.е. реальный результат может быть больше или меньше прогнозируемого. Но в принципе, плюс/минус Яша всегда показывает «правду».
Еще можно посмотреть статистику отдельно для десктопов, мобильников и т.п., просто переключив флажок в соответствующее поле, под основным полем ввода исследуемой фразы.
Сбор ключевых слов по регионам
При просмотре ключей по регионам на выбор предлагается 3 вкладки:
- Регионы;
- Города;
- Все вместе.
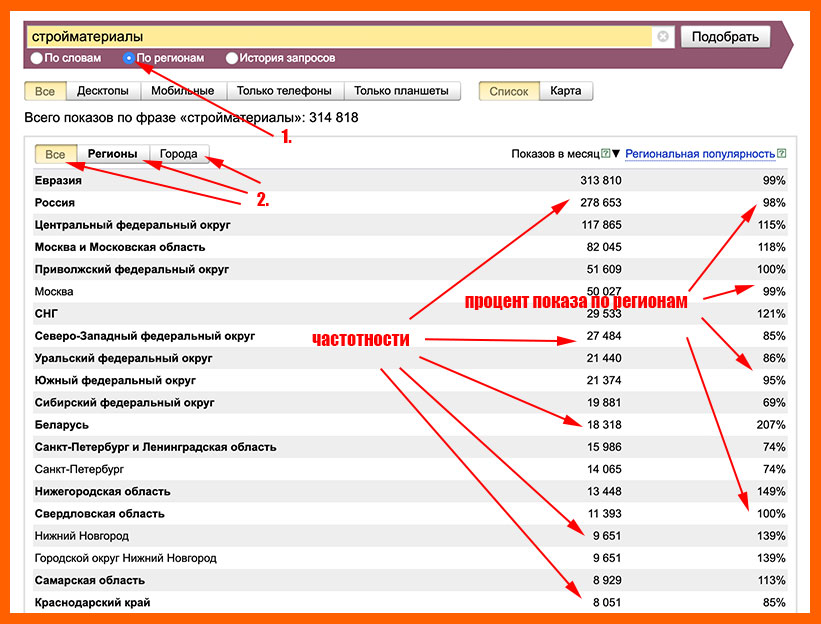
Справа, напротив каждого запроса мы видим соотношение популярности ключа к тому или иному региону. Если кликнуть на соответствующую ссылку, то можно отсортировать запросы по региональной популярности.
Можно посмотреть частотности ключевых слов, показываемые на том или ином устройстве: смартфоне, планшете, ПК и т.д.
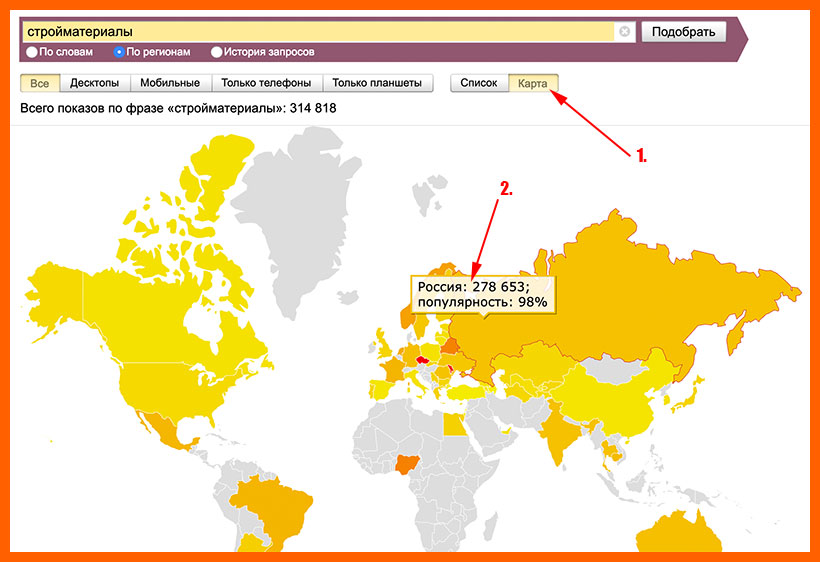
Кликнув по вкладке «Карта» откроется интерактивная карта. Наведя мышку на интересующую область, отобразится статистика по этому региону. Желтые области на карте относятся к наиболее популярным, красные к менее популярным.
Как посмотреть историю запросов
Установив флажок в поле «История запросов» можно посмотреть частоту показа этого запроса в определенный период времени (неделя, месяц, год). Таким образом определяются сезонные фразы.
Что это значит? Сезонные запросы – это те запросы, которые пользователи вбивают только в определенное время. Например, фраза «купить велосипед» будет вводиться в поиске Яндекса гораздо чаще весной и летом, чем осенью и зимой. Думаю, что вы со мной согласитесь.
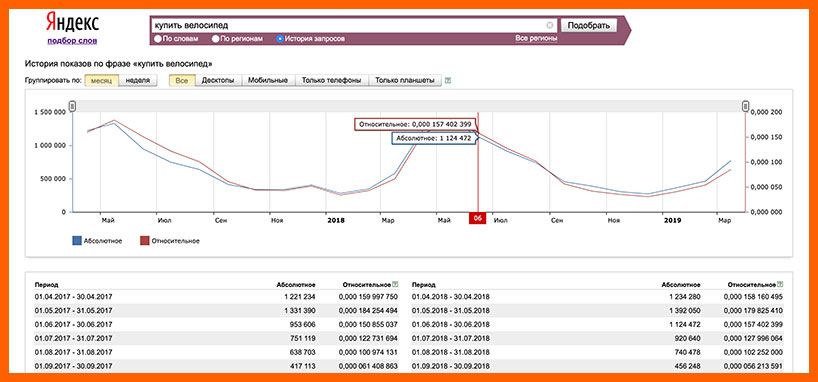
График показывает наглядное изменение количества вводимых фраз за период с 2018 года по 2019. Здесь же можно сделать группировку по неделям и месяцам и выбрать требуемое устройство, как и на предыдущей вкладке.
На графике показаны две кривые – с абсолютным и относительным значениями. Абсолютное показывает значение в данный момент, а относительное – отношение реального количества к общему числу показов за неделю или за месяц. Это общая популярность фразы.
Специальные операторы
Например, вам надо, чтобы сервис показал только определенные фразы в точной словоформе, падеже, числе и тому подобное. Для этого надо обрамить фразу в кавычки и поставить перед каждым словом восклицательный знак. Например, «!жилье !за !границей».
| Оператор | Значение |
| — | Если фраза содержит знак минус, то это слово удаляется. |
|
+ |
Если фраза содержит знак плюс, то показываются только те запросы, которые содержат это слово. |
|
«» |
Фраза в кавычках показывает все слова из данного запросов в любом порядке и словоформе. |
| «!» | Точное вхождение. |
Например, если мы ищем «жилье за -границей», то нам будут показаны только фразы с «жилье за». Слово «граница» не будет учитываться.
Другие эксперименты с дизайном
Когда стало ясно, что дизайнерские изменения в поисковых подсказках способны существенно влиять на метрики, фантазию было уже не остановить.
Для начала, попробуем усилить эффект от полнотекстовых подсказок. Если все пословные вытянуть в одну линию (с возможность скролла), для полнотекстовых подсказок будет больше места и, возможно, ввод станет ещё более быстрым.
С другой стороны, можно попробовать что-либо совсем уж странное. Давайте всегда подсказывать вероятные продолжения для наиболее вероятного следующего слова в отдельном столбце! Так родился вариант, который мы называем «саджест в виде графа»:
Саджест в виде графа производил фурор на всех UX-исследованиях. Все пользователи, впервые увидевшие его, говорили буквально следующее: «оооо, наконец-то мне помогают вводить запрос!». Тот, кто до сих пор не подозревал, что в поиске присутствуют подсказки, наконец их замечал. Тот, кто знал об их существовании, начинал пользоваться ими чаще.
Помимо этого, мы ещё пробовали изменять размер кнопок в пословных подсказках и их цвет. В целом, мысль была понятной: нужно как-то увеличить заметность подсказок, ведь они полезны и ими нужно чаще пользоваться!
Однако при проверке в онлайне обе гипотезы были отброшены. Тут же выяснились различия между метриками «доля использований саджеста» и «скорость ввода». К сожалению, слишком заметные подсказки вредят пользователям: они начинают слишком часто перескакивать глазами между саджестом и клавиатурой, а в результате вводят слишком медленно. Кроме того, это был один из редких случаев, когда тотальный успех на UX-исследованиях сопровождается столь же провальным выступлением в онлайне.
Знакомство с сервисом Yandex Wordstat
Предназначение сервиса
Поисковая система Яндекс является одним из двух гигантов в Рунете, который дает различную информацию практически на любой вопрос своих пользователей
Знание этих вопросов (поисковых запросов) дает много важной и полезной информации для успешной реализации следующих задач:
- анализ запросов для создания структуры веб-ресурса;
- поиск ключевых слов для семантического ядра интернет-сайта;
- анализ популярности тематики в интернет-маркетинге;
- поиск запросов для рекламной компании в Яндекс Директе.
Благодаря статистике поисковых фраз Вордстата, любой блоггер и вебмастер может получить исчерпывающую информацию для решение вышеперечисленных задач. Именно поэтому Wordstat является одним из самых популярных сервисов в сети. Куда уж без него…
Особенности Вордстата
Регистрация. Сейчас без регистрации никуда — любой нормальный сервис или онлайн-инструмент требует внесения персональных данных. «Подбор Слов» не исключение — для его использования требуется настоящий аккаунт в поисковике Яндекс.
Блокировка. Есть такая неприятная вещь — при неправильной работе с сервисом, Яндекс может заблокировать аккаунт пользователя. Это случается в двух случаях:
- при нарушении «Лицензии на использование поисковой системы»;
- при заражении Вашего компьютера вирусом;
Первый случай понятен — что-то делаем в разрез правил — получаем бан. Второй же вариант событий происходит из-за того, что появившийся вирус на нашем компьютере создает огромную нагрузку на сервис.
Кстати, таким же «вирусом» может быть одна из программ для сбора семантики — профессиональный парсер «Key Collector» или бесплатный софт «Словоеб». Каждая из них по требованию пользователя может парсить огромное число поисковых запросов в Яндекс Вордстате. Что при неправильном подходе может дать колоссальную нагрузку на сервис.
Капча. Это такая картинка (как правило — с цифрами), которая блокирует дальнейшую работу с Вордстатом. Она может появиться в следующих случаях:
- если в нашем браузере закрыты куки (файлы с данными сайтов, которые мы посещяли);
- если в нашем браузере отключены альтернативные куки (Flash);
- если в нашем браузере отключена поддержка языка JavaScript;
- если по определению IP компьютера мы не в зоне СНГ.
Для решения последней проблемы есть отличный вариант (его подсказал постоянный читатель моего блога, Руслан Цвиркун) — расширение friGate для браузера.
Возможности Подбора Слов
Статистика Вордстат — это не только просто большой склад поисковых запросов. С помощью этого сервиса можно узнать:
- примерный прогноз выбранных фраз на месяц;
- сезонность поисковых запросов в течение года;
- популярность тематик для информационных сайтов;
- оценку популярности фразы в конкретном регионе.
Все эти возможности тем или образом могут пересекаться. Особенно это часто возникает при формировании стратегии раскрутки коммерческих сайтов
Для информационных проектов важно увидеть в статистике запросов популярность тематик. Также это важно, когда нам нужно создать новый сайт, но есть вопросы по выбору популярной темы ресурса
Сетевые истории
Мы уже поняли, что скорость ввода складывается из качества данных и качества представления. Однако оказалось, что есть ещё один аспект проблемы – сетевой.
Исторически источник поисковых подсказок жил на домене , к которому поисковая вёрстка осуществляла асинхронные запросы в процессе пользовательского ввода.
К концу лета 2016 года стало понятно, что эта схема устарела. Многие сервисы уже жили за «единым доменом» : например, картинки , видео и так далее. Зачем? Чтобы экономить сетевые взаимодействия. У нас один единый балансер для всех сервисов, доступных на домене . Это означает, что, не покидая этого домена, пользователю достаточно лишь однажды установить сетевое соединение. В случае с саджестом это было не так: для похода за саджестом с домена требовалось установить новое сетевое соединение, что на 2G-интернете иногда стоило нескольких секунд ожидания.
Другим интересным моментом является поведение блокировщиков рекламы. Оказалось, некоторые из них блокируют кросс-доменные запросы. В нашем случае это привело к тому, что у некоторых пользователей саджест на несколько дней оказался полностью нефункциональным!
Поэтому мы решили провести эксперимент, в котором саджест переносится за единый для сервисов Яндекса балансер.
Тут стоит отметить, чем саджест отличается от других сервисов. Дело в том, что каждый поисковый запрос требует приблизительно столько же запросов в саджестовый источник, сколько в нём символов. Поэтому неудивительно, что типиный RPS для саджестового источника на порядки превосходит RPS других сервисов, в т.ч. большого Поиска. 100k RPS – это норма, саджест является одним из самых высоконагруженных сервисов Яндекса, непосредственно взаимодействующих с пользователями (некоторые внутренние сервисы выдерживают миллионы RPS).
Для единого балансера это означает очень существенный рост нагрузки, так что для удовлетворения нужд поисковых подсказок пришлось значительно вложиться в железо, и мы не хотели этого делать без подтверждения гипотезы о пользе для пользователей.
В результате эксперимент оказался одним из самых успешных за всё время. Его крутизна проявлялась даже в том, что пользователи начинали чаще задавать запросы в поисковую систему, не говоря уже о росте используемости саджеста и скорости ввода на единицы процентов.
Сбор поисковых подсказок Яндекса и Гугла
Сейчас в Интернете есть сервисы и программы, которые осуществляют сбор поисковых подсказок Яндекса и Гугла. Далее, нами будут рассмотрены такие сервисы и программа:
- Пиксель Тулс;
- Раш Аналитикс;
- Программа Кей Коллектор.
Парсер поисковых подсказок выглядит в Яндексе таким образом (Скрин 1).

Например, мы введём поисковый запрос – «заработок в Интернете». И если нажать на клавиатуре кнопку «Пробел» можно получить сразу ещё 9 таких аналогичных подсказок. Тоже самое дело обстоит и с Гуглом (Скрин 2).

Правда он больше подходит для продвижения иностранных ресурсов, чем сайтов, блогов русскоязычного Интернета. Веб-мастера в основном «упираются» на Яндекс, но о Гугле не забывают.
Варианты разбора
- Решать задачу в лоб, то есть анализировать посимвольно входящий поток и используя правила грамматики, строить АСД или сразу выполнять нужные нам операции над нужными нам компонентами. Из плюсов — этот вариант наиболее прост, если говорить об алгоритмике и наличии математической базы. Минусы — вероятность случайной ошибки близка к максимальной, поскольку у вас нет никаких формальных критериев того, все ли правила грамматики вы учли при построении парсера. Очень трудоёмкий. В общем случае, не слишком легко модифицируемый и не очень гибкий, особенно, если вы не имплементировали построение АСД. Даже при длительной работе парсера вы не можете быть уверены, что он работает абсолютно корректно. Из плюс-минусов. В этом варианте все зависит от прямоты ваших рук. Рассказывать об этом варианте подробно мы не будем.
- Используем регулярные выражения! Я не буду сейчас шутить на тему количества проблем и регулярных выражений, но в целом, способ хотя и доступный, но не слишком хороший. В случае сложной грамматики работа с регулярками превратится в ад кромешный, особенно если вы попытаетесь оптимизировать правила для увеличения скорости работы. В общем, если вы выбрали этот способ, мне остается только пожелать вам удачи. Регулярные выражения не для парсинга! И пусть меня не уверяют в обратном. Они предназначены для поиска и замены. Попытка использовать их для других вещей неизбежно оборачивается потерями. С ними мы либо существенно замедляем разбор, проходя по строке много раз, либо теряем мозговые клеточки, пытаясь измыслить способ удалить гланды через задний проход. Возможно, ситуацию чуть улучшит попытка скрестить этот способ с предыдущим. Возможно, нет. В общем, плюсы почти аналогичны прошлому варианту. Только еще нужно знание регулярных выражений, причем желательно не только знать как ими пользоваться, но и иметь представление, насколько быстро работает вариант, который вы используете. Из минусов тоже примерно то же, что и в предыдущем варианте, разве что менее трудоёмко.
- Воспользуемся кучей инструментов для парсинга BNF! Вот этот вариант уже более интересный. Во-первых, нам предлагается вариант типа lex-yacc или flex-bison, во вторых во многих языках можно найти нативные библиотеки для парсинга BNF. Ключевыми словами для поиска можно взять LL, LR, BNF. Смысл в том, что все они в какой-то форме принимают на вход вариацию BNF, а LL, LR, SLR и прочее — это конкретные алгоритмы, по которым работает парсер. Чаще всего конечному пользователю не особенно интересно, какой именно алгоритм использован, хотя они имеют определенные ограничения разбора грамматики (остановимся подробнее ниже) и могут иметь разное время работы (хотя большинство заявляют O(L), где L — длина потока символов). Из плюсов — стабильный инструментарий, внятная форма записи (БНФ), адекватные оценки времени работы и наличие записи БНФ для большинства современных языков (при желании можно найти для sql, python, json, cfg, yaml, html, csv и многих других). Из минусов — не всегда очевидный и удобный интерфейс инструментов, возможно, придется что-то написать на незнакомом вам ЯП, особенности понимания грамматики разными инструментами.
- Воспользуемся инструментами для парсинга PEG! Это тоже интересный вариант, плюс, здесь несколько побогаче с библиотеками, хотя они, как правило, уже несколько другой эпохи (PEG предложен Брайаном Фордом в 2004, в то время как корни BNF тянутся в 1980-е), то есть заметно моложе и хуже выглажены и проживают в основном на github. Из плюсов — быстро, просто, часто — нативно. Из минусов — сильно зависите от реализации. Пессимистичная оценка для PEG по спецификации вроде бы O(exp(L)) (другое дело, для создания такой грамматики придется сильно постараться). Сильно зависите от наличия/отсутствия библиотеки. Почему-то многие создатели библиотек PEG считают достаточными операции токенизации и поиска/замены, и никакого вам AST и даже привязки функций к элементам грамматики. Но в целом, тема перспективная.
Как подпасть в подсказки Яндекс: «белые методы»
Как только Яндекс запустил опцию с подсказками, оптимизаторы оценили выгоду для продвижения от этого апдейта. Примерно три года назад форумы и группы для SEO-специалистов буквально были переполнены предложениями попасть в подсказки. Некоторые агентства и фрилансеры до сих пор предлагают услугу:

Все эти предложения — варианты «черного SEO»: дешево, быстро и неэффективно. Накрутка происходит при помощи 50-100 фрилансеров, которые набирают в поисковой строке по 100 и больше раз одну фразу. Либо используются боты, эмулирующие действия человека.
Поисковик формирует подсказки по степени популярности, релевантности и «свежести». То есть, результаты массовой атаки вчера, могут обнуляться на следующий день. Это связано с тем, что Яндекс ежедневно фильтрует семантику. Веб-мастеру придется постоянно оплачивать услуги фрилансеров или запускать программный скрипт. И это будет замечено Яндексом. Такие действия могут стать причиной наложения санкций на сайт. Ресурс потеряет позиции и 100% вылетит из подсказок надолго.
Поэтому лучше выбирать «белые методы», чтобы не рисковать площадкой и вложенным раннее бюджетом в раскрутку. Попасть в подсказки можно при помощи грамотной медиа стратегии. Помимо релевантной запросам и потребностям аудитории контент-стратегии, можно сотрудничать с блогерами, подключить комьюнити-менеджера для работы с сообществами и рассмотреть варианты офлайн-рекламы. Это делается для того, чтобы увеличить узнаваемость бренда. Офлайн-реклама помогает продвинуть локальный бизнес, но метод дорогой, поэтому может не окупиться, если у компании специфическая ниша.
В 2020 году Яндекс облегчил жизнь оптимизаторам, представив новый апдейт — запуск контекстной рекламы под поисковой строкой. Опция называется «Баннер над подсказками». Это вариант нативной рекламы, приносящий неплохую конверсию.

Подтверждают эффективность рекламного метода и исследования Яндекса. По результатам теста, CTR баннера — 16%, а прибавка к трафику — 5%. Если сайт вышел в ТОП-3 и рекламируется таким способом, то у него будут одновременно два места на первой странице в SERP: баннер под строкой и позиция в поисковой выдаче.
Также можно использовать и тизерную рекламу, если хватит бюджета. Хотя веб-мастера относятся скептически, но метод парадоксально работает и привлекает пользователей на сайт.
Яндекс подсказки помогают продвигать сайт, улучшая посещаемость и CTR. Но повлиять на алгоритмы поисковика сложно за счет фильтров популярности и релевантности. Агентства, обещающие попадание в подсказки, используют накрутку. Это чревато санкциями и дополнительными расходами на восстановление позиций.
Чтобы увеличить вероятность попадания в подсказки, работайте над качеством контента на сайте, привлекайте к сотрудничеству блогеров, попробуйте тизерную и офлайн-рекламу. Кроме того, можно продвигаться при помощи новой опции Яндекса — «Баннер над подсказками».
Варианты вывода результатов#
A-Parser поддерживает гибкое форматирование результатов благодаря встроенному шаблонизатору Template Toolkit, что позволяет ему выводить результаты в произвольной форме, а также в структуированной, например CSV или JSON
Сохранение в формате SQL
Формат результата:
%FOREACH p1.results;»INSERT INTO serp VALUES(‘» _ query _ «‘, ‘»; suggest _ «‘)\n»;END%
Скопировать
Пример результата:
INSERTINTO serp VALUES(‘write essay’,’write essays online telegra.ph’)
INSERTINTO serp VALUES(‘write essay’,’write essay bot’)
INSERTINTO serp VALUES(‘write essay’,’write essay telegra.ph’)
INSERTINTO serp VALUES(‘write essay’,’write essays for money telegra.ph’)
INSERTINTO serp VALUES(‘write essay’,’write essay english telegra.ph’)
INSERTINTO serp VALUES(‘write essay’,’write essays for cash’)
INSERTINTO serp VALUES(‘write essay’,’write essay service’)
INSERTINTO serp VALUES(‘write essay telegra.ph’,’writer essay telegra.ph’)
INSERTINTO serp VALUES(‘write essay telegra.ph’,’persuasive essay write telegra.ph’)
…
Скопировать
Заключение
Самое главное – не перестарайтесь с SEO-оптимизацией. В первую очередь вы должны писать для людей, и лишь во вторую очередь для машин. Создавайте авторский контент, ориентируясь на предпочтения своей аудитории. Наполняйте контент пользой – от простых советов до пошаговых инструкций. И обязательно общайтесь со своей аудиторией, собирайте обратную связь.
Не забывайте, что самые большие результаты дает комплексное продвижение. Каждый канал работает эффективнее, когда его усиливают другие.
Google рассказал в своем блоге, что в самое ближайшие время начнёт удалять больше разновидностей поисковых подсказок. Это нововведение призвано обезопасить пользователей от шокирующего или оскорбительного контента.
Сразу Вас успокою, данные новости никак не коснутся нормальных подсказок и Вы можете их продвигать как и раньше, наоборот данное сообщение в очередной раз напрямую доказывает, что на появление подсказок может оказывать прямое воздействие.

Функция автозаполнения в поиске Google неоднократно становилась объектом недовольства общественности. Неоднократно, пользователи жаловались на ксенофобские и расистские подсказки. Результаты, выдаваемые этим функционалом очень часто попадали в судебные разбирательства по всему миру.
Несмотря на все вышеперечисленное, Google продолжает доказывать, что эти результаты являются лишь результатом большого количества определенных запросов пользователей. При этом компания не отказывается от их модерации, устанавливая определенные рамки, а также удаляя ужасные подсказки в ручном режиме.
На этой неделе в Google в очередной раз заявили, что функционал подсказок основан на информации «реальных поисковых сессий и возвращает распространённые и трендовые запросы, релевантные тем символам, которые были набраны, а также местоположению и истории поиска пользователя».
