Обновление версий postgresql, или как не уронить базу при update?
Содержание:
- А как насчёт мониторинга?
- Postgres на Linux и Postgres на Windows: что лучше
- EMS Studio
- What is PostgreSQL?
- Data Definition Language (DDL)
- Описание таблицы
- 1.1. Предыстория
- 2. Postgres: общие сведения
- Второй раунд
- Настройка прав PostgreSQL
- Хранение данных
- 2.3. Xранение и восстановление на основе журнала
- Расширения базы данных
- SQL
- NAVICAT
- Partitioning & Inheritance
- Истории успеха
- Кому надо переходить на Postgres
- Установка RedHat Enterprise Linux 8 (RHEL 8.4). Подключение RHEL8 к домену Active Directory. Запуск терминального клиента.
- Возможности обработки
- Путь поиска
- Разработка
А как насчёт мониторинга?
В современной разработке любой микросервис или инфраструктурный компонент должен быть поставлен на мониторинг, то есть непрерывно отдавать метрики — ключевые показатели, позволяющие определить, как ведёт себя система в данный момент времени.
PostgreSQL не имеет встроенной интеграции с системами мониторинга наподобие Prometheus (или Zabbix). Вместо этого он полагается на использование внешних агентов — экспортеров. Мы у себя активно используем postgres_exporter, позволяющий добавлять свои собственные sql-запросы и кастомные метрики на их основе:
После запуска скрипта экспортер будет доступен на порту и отдавать метрики в формате Prometheus:
Разумеется, для полноценной постановки на мониторинг нужно ещё поднять сам Prometheus + Grafana, а так же загрузить подходящий dashboard, но это уже выходит за рамки данной статьи. Более того, если ваша служба информационной безопасности исповедует Zero Trust, то экспортер придётся прикрыть с помощью nginx и настроить mTLS…
Postgres на Linux и Postgres на Windows: что лучше
Сами удивились, сами себя похвалили, какие мы молодцы, что 5 лет назад сделали крутой выбор. Но встречаем очень часто вопрос: стоит ли переходить на Postgres.10 на Windows.
Тот самый злополучный баг Postgres, когда система замирала на 15 секунд из-за недоступности файла статистика исправлен в версии Postgres 10.4.1. Говорю об этом отдельно, потому что эта версия на данный момент 1С не поддерживается. Она есть только на сайте Postgres Pro, мы ее поставили и запустили ради этой конференции. Что получили? При 10 потоках все почти одинаково, что на Postgres версии 9, что на Postgres версии 10. При 20 потоках Postgres.10 в 3 раза быстрее. Я бы даже сказал иначе: Postgres.9 на Windows в 3 раза медленнее, потому что возникает та самая блокировка, замирание на 15 секунд. Причем, оно рандомное, то есть вы не угадаете, это будут замирания один раз в минуту или у вас будет секунда работы, 15 секунд замирание и так тысячу раз.
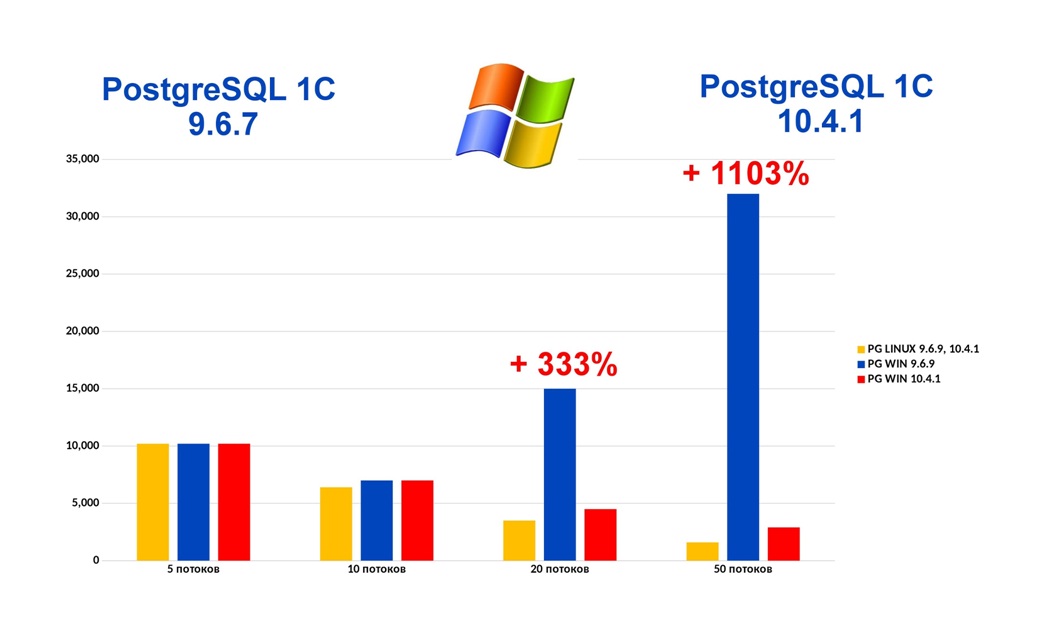
При 50 потоках Postgres.9 медленнее в 11 раз. При 100 потоках мы не дождались завершения операции. Данные я не привожу. Нам надоело: мы неделю ждали.
Второй самый популярный вопрос, стоит ли переходить на Linux? Да, стоит переходить! По нашим данным, а они у нас достаточно релевантные – 15 терабайт и 400 баз, Postgres работает почти в 2 раза быстрее.

Почему? Не потому что Postgres такой плохой на Windows, а потому что файловая система Windows не способна обрабатывать такое большое количество файлов. Тут вся фишка в том, как Postgres и MS хранят файлы. Если MS хранит по умолчанию всю вашу базу данных в двух файлах (это файл данных mdf и файл журнала транзакций lgf), то Postgres хранит каждую таблицу в отдельном файле и каждый индекс в отдельном файле.
Типовая база бухгалтерии содержит 6 тысяч таблиц и 20 тысяч индексов. Значит, одна база будет в Postgres представлена 26 тысячами файлов. На наших серверах мы примерно делаем по 60 баз на один instant Postgres, это в районе 2 миллионов файлов. С таким количеством файлов Linux управляется, как мы видим, почти в 2 раза быстрее, чем Windows.
Поэтому если вы уже всерьез на Postgres, а всерьез – это наличие хотя бы 20 сессий, начинайте подумывать о переходе на Linux. Причем, не обязательно железный, можете на этой же винде, если сильно страшно, то поднимите hyper-v, поднимите виртуалку, на эту виртуалку ставьте Linux, ставьте Postgres, и получите отличный эффект. Проверено!
EMS Studio
 EMS Studio, похоже, работает только под Windows. Это его главный недостаток, потому что, как известно PostgreSQL очень редко используют под виндой.
EMS Studio, похоже, работает только под Windows. Это его главный недостаток, потому что, как известно PostgreSQL очень редко используют под виндой.
До кучи там зачем-то сделан визуальный конструктор запросов. Где вместо того, чтобы текстом написать , надо нажать мышкой несколько кнопок и понавыбирать из выпадающего списка. Тем, кто знает SQL — это не нужно, тем кто не знает — это не поможет.
Фичи, которые называют как удобные: auto-complete с алиасами, экспорт результата выполнения запроса в SQL формате (insert), удобный GUI для экпорта базы, возможность выполнять только выделенную часть SQL.
Умеет дебаг pl/pgsql. В общем, много чего умеет, но какой-то выдающейся особенности, что отличало бы от других, я не могу назвать.
What is PostgreSQL?
PostgreSQL is a powerful, open source object-relational database system that uses and extends the SQL language combined with many features that safely store and scale the most complicated data workloads. The origins of PostgreSQL date back to 1986 as part of the POSTGRES project at the University of California at Berkeley and has more than 30 years of active development on the core platform.
PostgreSQL has earned a strong reputation for its proven architecture, reliability, data integrity, robust feature set, extensibility, and the dedication of the open source community behind the software to consistently deliver performant and innovative solutions. PostgreSQL runs on all major operating systems, has been ACID-compliant since 2001, and has powerful add-ons such as the popular PostGIS geospatial database extender. It is no surprise that PostgreSQL has become the open source relational database of choice for many people and organisations.
Getting started with using PostgreSQL has never been easier — pick a project you want to build, and let PostgreSQL safely and robustly store your data.
Data Definition Language (DDL)
| 14 | 13 | 12 | 11 | 10 | 9.6 | 9.5 | 9.4 | 9.3 | 9.2 | 9.1 | 9.0 | 8.4 | 8.3 | 8.2 | 8.1 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
|
ALTER object IF EXISTS |
Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | No | No | No | No | No | No |
|
ALTER TABLE … ADD UNIQUE/PRIMARY KEY USING INDEX |
Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | No | No | No | No | No |
|
ALTER TABLE … SET LOGGED / UNLOGGED |
Yes | Yes | Yes | Yes | Yes | Yes | Yes | No | No | No | No | No | No | No | No | No |
|
Changing column types (ALTER TABLE .. ALTER COLUMN TYPE) |
Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes |
|
CREATE ACCESS METHOD |
Yes | Yes | Yes | No | No | No | No | No | No | No | No | No | No | No | No | No |
|
CREATE TABLE … (LIKE) with foreign tables, views and composite types |
Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | No | No | No | No | No | No |
|
DROP object IF EXISTS |
Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | No |
|
ON COMMIT clause for CREATE TEMPORARY TABLE |
Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes |
| Yes | Yes | Yes | No | No | No | No | No | No | No | No | No | No | No | No | No | |
|
Stored Generated Columns |
Yes | Yes | Yes | No | No | No | No | No | No | No | No | No | No | No | No | No |
|
Typed tables |
Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | No | No | No | No |
Описание таблицы
Если таблица создана какое-то время назад. Вы могли уже забыть, какие конкретно столбцы она содержит.
Для описания таблицы используется команда \d
\d booking_sites
Table «public.booking_sites»
Column | Type | Collation | Nullable | Default
—————-+————————+————+———-+——————————————-
id | bigint | | not null | nextval(‘booking_sites_id_seq’::regclass)
company_name | character varying(50) | | not null |
origin_country | character varying(50) | | not null |
age | character varying(3) | | not null |
date_of_birth | date | | not null |
website_url | character varying(50) | | |
Indexes:
«booking_sites_pkey» PRIMARY KEY, btree (id)
1.1. Предыстория
2. Postgres: общие сведения
†
- Поддержка АТД в системе баз данных
- Сложные объекты (т. е. вложенные данные или данные не первой нормальной формы (non-first-normal form — NF2))*
- Пользовательские абстрактные типы данных и функции*
- Расширяемые методы доступа для новых типов данных*
- Оптимизированная обработка запросов с дорогостоящими пользовательскими функциями
- Активные базы данных и системы правил (триггеры, предупреждения)*
- Правила, реализованные в виде перезаписи запроса†
- Правила, реализованные как триггеры уровня записи†
- Хранение и восстановление на основе журнала
- Код восстановления с уменьшенной сложностью, рассматривающий журнал как данные*, использование энергонезависимой памяти для состояния фиксации†
- Хранилище без перезаписи и темпоральные запросы†
- Поддержка новых технологий глубокого хранения данных, в особенности оптических дисков*
- Поддержка мультипроцессоров и специализированных процессоров*
- Поддержка различных языковых моделей
- Минимальные изменения реляционной модели и поддержка декларативных запросов*
- Доступ к «быстрому пути» из внутренних API в обход языка запросов†
- Многоязычность†
Второй раунд
Тут уже практически пользовательская нагрузка. Операция, на которой проводится тестирование, – восстановление последовательности партионного
учета управленческих партий. Это последняя УПП на момент тестирования, код типовой. Также типовой клиент, у которого итоги рассчитаны на полгода назад. Я не знаю, почему у клиентов такая амнезия по поводу этой регламентной операции, но никто не хочет следить за итогами. Почему, никто объяснить тоже не может. Поэтому берем типовой код, типового клиента, в самих партиях за месяц 150 тысяч документов, а строк в документах около 2 миллионов.
Все это делаем в 10 потоков. Это уже чуть-чуть не типовой этап, сделана определенная обработка, но внутри все запросы типовые.
В результате у нас получилось, что Postgres всего на 4% лучше. Делалось все очень долго – порядка 18 часов. И бухгалтеры будут вынуждены весь день не работать, чтобы дождаться результатов.

Поскольку результат получился не очень большой, плюс 4%, решили вместо
мельдония использовать что-нибудь похлеще. Второй в рейтинге вредных советов интернета на запрос «1С + Postgres тормозит» оказалась рекомендация отключить autovacuum. Отключили.
Результат получился еще хуже – примерно на 5%. То есть если бы мы изначально настроили систему с помощью этого вредного совета, мы бы вообще раунд полностью проиграли, было бы минус 0,6%.
На этом хочу остановиться чуть подробнее. Что за зверь такой autovacuum, зачем он нужен. И почему разработчики Postgres на каждой конференции твердят: «Не отключайте autovacuum!», но народ упорно его отключает. Попытаюсь объяснить, как говорят, на пальцах.
Чтобы понять, для чего нужен autovacuum, нужно понять, как Postgres работает с данными. Операция insert – записали строчку. Помимо строчки, пишется еще два служебных параметры x min и x max. В x min записывается номер транзакции, которая выполнила этот insert. Операция delete на самом деле ничего не удаляет, она просто в служебное поле строки x max записывает номер транзакции, которая ее удалила. Потом идет самая прикольная операция update. На самом деле нет такой операции, это просто delete + insert.

А в мире 1С, к сожалению, просто обожают работать задним числом: для пользователей не вопрос перевести месяц или год. То есть апдейтов миллионы. У нас не столько растут данные с помощью insert, сколько с помощью update, мы постоянно что-то обновляем. Из-за этого база имеет эффект распухания. Ладно, пусть раздувается, скажем админам, что это их проблемы, пусть увеличивают диски. Они увеличат. Но если было бы все так просто, никто не заморачивался бы. Проблема в том, что данные хранятся не где-то в сферическом вакууме, они хранятся в страницах. И когда у вас в страницах хранится куча мертвых данных, а в Postgres есть такое страшное понятие, как мертвые строчки, и когда вы делаете запрос базе данных, движок вынужден поднять все страницы с данными, отфильтровать данные, в которых x max пустой, и только с ними потом работать. Вы каждый раз заставляете Postgres ставить олимпийские рекорды по поднятию данных с дисков, чтобы выдать вам выборку.

Что делает autovacuum? Autovacuum – это своеобразный пылесос, он циклически и периодически идёт к каждой таблице вашей базы данных и делает выборку всех данных, где x max не пустой и чистит их физически. Теперь туда insert возможен, у вас на страницах будет больше живых данных, чем мертвых. Эффект – вам проще поднимать страницы. Это первое.
Второе. Помимо чистого autovacuum, есть еще такой фоновый процесс autovacuum analyze. Это аналог фонового обновления статистики в MS SQL. Без него планировщик никогда не узнает, что вы в таблицу добавили данные. Было в таблице 100 записей, добавили вы миллион записей, но планировщик свято уверен, что там их 100. И при любом запросе не парится и не ищет никакие индексы. Он просит TableScan, ему его дают, а там миллион записей. И вы сидите и ждете несколько минут.
Поэтому никогда не выключайте autovacuum. Надо его правильно настраивать, но ни в коем случае не отключать. Он имеет кучу настроек, и если у вас autovacuum настроен достаточно агрессивно, то есть он срабатывает на очень маленьком проценте изменения данных в таблицах, то вам не нужны даже ночные и недельные регламенты над базой данных, которые имеются у MS SQL. Ничего не надо делать, просто ничего. Кое-что делают только админы, если точно знают, что в этой таблице недавно удалили огромный массив данных, и ее нужно, грубо говоря, сжать. Тогда делается autovacuum full – это реструктуризация таблицы в понятиях 1С. Рядом создается табличка, куда и копируются данные.
В других случаях вам никакие регламенты, ни ночные, ни недельные, не нужны. Autovacuum все сделает за вас. Только настраивайте его правильно.
Настройка прав PostgreSQL
На сервере PostgreSQL нам необходимо:
- Задать пароль для пользователя postgres.
- Создать пользователя, пароль для которого мы будем хранить в Vault.
- Разрешить подключение к базе данных для postgres и созданного пользователя.
- Открыть порт 5432 для удаленного подключения.
- Проверить доступы.
Рассмотрим действия по шагам.
1. Задаем пароль для postgres
Данные действия необходимы, если мы не задавали пароль для пользователя postgres или мы не знаем данный пароль.
Стоит иметь ввиду, что данный пользователь может использоваться другими приложениями — таким образом, смена пароля приведет к потере их работоспособности. В этом случае, стоит уточнить текущий пароль и использовать его.
Заходим под пользователем postgres и подключаемся к СУБД:
su — postgres
$ psql
Вводим:
=# ALTER USER postgres PASSWORD ‘password’;
* в данном примере мы задаем пароль password для пользователя postgres.
2. Создаем нового пользователя
На данном шаге мы создадим пользователя, для которого и будем хранить секрет в Vault. В рамках примера мы не будем его предоставлять никаких доступов. Для нас достаточно, чтобы мы могли подключиться и удостовериться, что пароль будет меняться.
В той же командной оболочке postgresql вводим:
=# CREATE USER dmosk WITH PASSWORD ‘myPassword’;
* с помощью данной команды мы создадим пользователя dmosk с паролем myPassword.
3. Разрешаем подключение к СУБД
Нам необходимо разрешить подключаться к базе данных пользователю dmosk (создали на шаге 2) с локального компьютера и пользователю postgres с сервера Vault. Это делается посредством редактирования файла pg_hba.conf.
Но размещение этого файла может быть разным — это зависит от версии установленного PostgreSQL. Вводим команду:
=# SHOW config_file;
Данная команда нам покажет место размещения конфигурационного файла postgresql.conf — в этом же каталоге находятся и другие конфигурационные файлы. Например, если команда показала:
—————————————-
/var/lib/pgsql/11/data/postgresql.conf
(1 row)
… то значит нужный нам файл в каталоге /var/lib/pgsql/11/data.
Выходим из командной оболочки psql:
=# \q
Разлогиниваемся из-под пользователя postgres:
$ exit
И вводим:
vi /var/lib/pgsql/11/data/pg_hba.conf
* где /var/lib/pgsql/11/data — путь, который мы получили с помощью sql-команды SHOW config_file.
В данном файле мы должны добавить 2 строки:
…
# «local» is for Unix domain socket connections only
local all dmosk md5
…
# IPv4 local connections:
host all postgres 192.168.1.20/32 md5
…
* где 192.168.1.20 — IP-адрес предполагаемого сервера Vault, с которого мы будем подключаться под пользователем postgres.
Открываем конфигурационный файл:
vi /var/lib/pgsql/11/data/postgresql.conf
Приводим опцию listen_addresses к виду:
listen_addresses = ‘*’
* в данном примере мы настроили, чтобы postgresql слушал запросы на всех сетевых интерфейсах. При необходимости. мы можем ограничить их число вводом конкретного адреса.
Перезапускаем службу СУБД:
systemctl restart postgresql
* команда для перезапуска PostgreSQL может отличаться и зависит от версии СУБД.
4. Настраиваем межсетевой экран
Для подключения к серверу баз данных по сети, нам необходимо открыть порт 5432.
Как правило, в CentOS используется firewalld, как средство управления брандмауэром. Вводим:
firewall-cmd —permanent —add-port=5432/tcp
firewall-cmd —reload
5. Делаем проверку
Убедимся, что наши учетные записи имеют права для подключения к базе данных.
На сервере с СУБД вводим:
psql -Udmosk -W template1
* в данном примере мы подключаемся к локальному хосту под пользователем dmosk.
Система запросит пароль — вводим тот, что задали при создании нашего пользователя. Мы должны попасть в оболочку psql.
Теперь подключаемся по SSH на сервер Vault. Нам придется установить на него клиента postgresql.
а) На системы RPM (Rocky Linux, CentOS):
yum install postgresql
б) На Deb (Ubuntu, Debian):
apt install postgresql
После установки можно подключаться к нашему серверу с помощью команды psql.
Вводим:
psql -h192.168.1.15 -Upostgres -W
* в данном примере мы подключимся к серверу 192.168.1.15 под учетной записью postgres.
Консоль у нас запросит пароль — вводим тот, что задали для пользователя postgres. В итоге мы должны подключиться к серверу:
postgres=#
Выходим из SQL-оболочки:
postgres=# \q
… и переходим к настройке Vault.
Хранение данных
MySQL
MySQL — это реляционная база данных, для хранения данных в таблицах используются различные движки, но работа с движками спрятана в самой системе. На синтаксис запросов и их выполнение движок не влияет. Поддерживаются такие основные движки MyISAM, InnoDB, MEMORY, Berkeley DB. Они отличаются между собой способом записи данных на диск, а также методами считывания.
Postgresql
Postgresql представляет из себя объектно реляционную базу данных, которая работает только на одном движке — storage engine. Все таблицы представлены в виде объектов, они могут наследоваться, а все действия с таблицами выполняются с помощью объективно ориентированных функций. Как и в MySQL все данные хранятся на диске, в специально отсортированных файлах, но структура этих файлов и записей в них очень сильно отличается.
2.3. Xранение и восстановление на основе журнала
К сожалению, PostgreSQL все еще не особенно быстро обрабатывает транзакции: использование в нем журнала упреждающей записи несколько половинчато. Как ни странно, команда PostgreSQL сохранила много служебной информации, хранимой вместе с кортежами в Postgres, для обеспечения многоверсионности, что никогда не было целью проекта Postgres в Беркли. Результатом является система хранения, которая может эмулировать изоляцию снимков (snapshot isolation) Oracle с изрядным объемом дополнительных накладных расходов ввода-вывода, но которая не следует первоначальной мысли Стоунбрейкера о темпоральных запросах или простом восстановлении.Майк Олсон (Mike Olson) отмечает, что его первоначальное намерение состояло в том, чтобы заменить реализацию B-дерева Postgres своей собственной реализацией B-дерева из проекта Berkeley DB, который разрабатывался в Беркли в эпоху Postgres. Но Олсон так и не нашел на это времени. Когда годы спустя Berkeley DB получила поддержку транзакций в Sleepycat Corp., Олсон попытался убедить (тогдашнее) сообщество PostgreSQL использовать его для восстановления вместо хранилища «без перезаписи». Они отказались: в проекте был программист, который отчаянно хотел построить систему с многоверсионностью (MVCC), и поскольку он был готов выполнить работу, он выиграл спор.Медленно работающее хранилище PostgreSQL не является внутренне присущим системе. В Greenplum ветка PostgreSQL в качестве интересной альтернативы интегрировала высокопроизводительное сжатое хранилище. Оно было разработано Мэттом МакКлином (Matt McCline)—ветераном команды Джима Грея (Jim Gray) в компании Tandem. Оно также не поддерживало темпоральных запросов.
Расширения базы данных
К базам данных PostgreSQL можно подключать расширения.
Подключение расширений к базе данных
К каждой базе данных расширения подключаются отдельно.
Чтобы подключить расширение, в панели управления:
- Перейдите в раздел Облачная платформа ⟶ Базы данных.
- Выберите нужный кластер и на его странице откройте вкладку Базы данных.
- В карточке нужной базы данных в блоке Расширения нажмите кнопку Добавить.
- Выберите в списке расширение и сохраните изменения.
Зависимые расширения
Некоторые расширения зависят от других (являются зависимыми) — они не будут работать, если не подключить расширения, от которых они зависят. При подключении к базе данных зависимого расширения автоматически будет подключено то, от которого оно зависит.
Зависимое расширение можно удалить отдельно. Чтобы удалить расширение, от которого зависит другое, нужно сначала удалить зависимое.
Зависимые расширения указаны в списке ниже.
Список расширений
Доступные расширения, в том числе зависимые:
- address_standardizer;
- address_standardizer_data_us;
- ;
- bloom;
- btree_gin;
- btree_gist;
- citext;
- cube;
- dict_int;
- dict_xsyn;
- earthdistance, зависит от расширения cube;
- fuzzystrmatch;
- hstore;
- intarray;
- isn;
- jsquery;
- lo;
- ltree;
- ;
- pg_partman;
- pg_repack;
- pg_stat_kcache, зависит от расширения pg_stat_statements;
- pg_stat_statements;
- pg_trgm;
- pgcrypto;
- pgrouting, зависит от расширения postgis;
- pgrowlocks;
- postgis;
- , зависит от расширения postgis;
- postgis_topology, зависит от расширения postgis;
- postgres_fdw;
- seg;
- tablefunc;
- unaccent;
- uuid-ossp;
- xml2;
- ip4r;
- pgTAP;
- prefix;
- rum.
SQL
| 14 | 13 | 12 | 11 | 10 | 9.6 | 9.5 | 9.4 | 9.3 | 9.2 | 9.1 | 9.0 | 8.4 | 8.3 | 8.2 | 8.1 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Yes | Yes | No | No | No | No | No | No | No | No | No | No | No | No | No | No | |
| Yes | Yes | Yes | Yes | Yes | Yes | Yes | No | No | No | No | No | No | No | No | No | |
|
INSERT/UPDATE/DELETE RETURNING |
Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | No |
|
LATERAL clause |
Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | No | No | No | No | No | No | No |
|
Multirow VALUES |
Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | No |
|
ORDER BY NULLS FIRST/LAST |
Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | No | No |
|
Recursive Queries |
Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | No | No | No |
|
Row-wise comparison |
Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | No |
|
SELECT FOR NO KEY UPDATE/SELECT FOR KEY SHARE lock modes |
Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | No | No | No | No | No | No | No |
| Yes | Yes | Yes | No | No | No | No | No | No | No | No | No | No | No | No | No | |
|
SQL standard interval handling |
Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | No | No | No |
|
TABLE statement |
Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | No | No | No |
|
Upsert (INSERT … ON CONFLICT DO …) |
Yes | Yes | Yes | Yes | Yes | Yes | Yes | No | No | No | No | No | No | No | No | No |
|
Window functions |
Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | No | No | No |
| Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | No | No | No | No | No | No | No | No | |
| Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | No | No | No | No | No | No | No | No | |
|
WITH Queries (Common Table Expressions) |
Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | No | No | No |
|
Writable WITH Queries (Common Table Expressions) |
Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | No | No | No | No | No |
NAVICAT
 Navicat — это, наверное, самая богатая фичами программа. Она умеет всё, что умеют другие GUI для БД: дизайнер объектов, просмотрщик таблиц, автокомплит, инструменты проектирования базы, отладка pl/pgsql, импорт/экспорт и так далее.
Navicat — это, наверное, самая богатая фичами программа. Она умеет всё, что умеют другие GUI для БД: дизайнер объектов, просмотрщик таблиц, автокомплит, инструменты проектирования базы, отладка pl/pgsql, импорт/экспорт и так далее.
Поистине всеобъемлющий софт, который работает практически на любой ОС. Навскидку, намного удобнее EMS Studio.
Киллер-фичей, на мой взгляд, является сравнение баз. Т.е. можно взять две базы, узнать, чем они отличаются по структуре и сформировать запросы для синхронизации.
Ценник, правда, что называется, «конский» — в два раза дороже, чем EMS. Но тут, похоже, это полностью оправдано.
Partitioning & Inheritance
| 14 | 13 | 12 | 11 | 10 | 9.6 | 9.5 | 9.4 | 9.3 | 9.2 | 9.1 | 9.0 | 8.4 | 8.3 | 8.2 | 8.1 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Yes | Yes | Yes | Yes | Yes | No | No | No | No | No | No | No | No | No | No | No | |
|
Default Partition |
Yes | Yes | Yes | Yes | No | No | No | No | No | No | No | No | No | No | No | No |
|
Foreign Key references for partitioned tables |
Yes | Yes | Yes | No | No | No | No | No | No | No | No | No | No | No | No | No |
|
Foreign table inheritance |
Yes | Yes | Yes | Yes | Yes | Yes | Yes | No | No | No | No | No | No | No | No | No |
|
Logical Replication for Partitioned Tables |
Yes | Yes | No | No | No | No | No | No | No | No | No | No | No | No | No | No |
|
Partitioning by a hash key |
Yes | Yes | Yes | Yes | No | No | No | No | No | No | No | No | No | No | No | No |
|
Support for PRIMARY KEY, FOREIGN KEY, indexes, and triggers on partitioned tables |
Yes | Yes | Yes | Yes | No | No | No | No | No | No | No | No | No | No | No | No |
|
Table Partitioning |
Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes |
|
UPDATE on a partition key |
Yes | Yes | Yes | Yes | No | No | No | No | No | No | No | No | No | No | No | No |
Истории успеха
PostgreSQL используется во многих отраслях, например телекоммуникации, медицина, географические приложения и электронная коммерция. Есть много компаний, оказывающих коммерческие консультационные услуги, например в переходе с коммерческой РСУБД на PostgreSQL с целью уменьшения лицензионных платежей. Такие компании часто оказывают влияние на развитие PostgreSQL, разрабатывая новые средства. Перечислим несколько компаний, применяющих PostgreSQL:
- в Skype PostgreSQL используется для хранения чатов и истории действий. Компания Skype разработала для PostgreSQL много инструментов под общим названием SkyTools;
- Instagram — социальная сеть для обмена фотографиями;
- Американское химическое общество (ACS) использует PostgreSQL для хранения архивов журнала объемом свыше терабайта.
- Помимо этих компаний, PostgreSQL используется в HP, VMware и Heroku, а также многими научными обществами и организациями, в частности NASA.
Кому надо переходить на Postgres

И теперь, наверное, самое важное: кому точно надо переходить на Postgres?
-
Если у вас проходит новая инсталляция продуктовой системы. Если вы ставите новую систему, я бы рекомендовал перейти хотя бы на бесплатный Postgres. Рекомендую сразу это делать на Linux. Можно и на Windows, но тут проблема не столько в том, что Postgres плохой или Windows плохой – плохо работает их связка в части файловой системы. Опять же из-за наших структур баз данных, где у нас по 30 тыс. элементов в одной таблице (7 тыс. таблиц, 25 тыс. индексов). С таким количеством файлов винда работает плохо, а Postgres хранит каждый элемент системы в отдельном файле – более того, он эти файлы разбивает по 1 Гб, для каждого файла есть отдельные служебные файлы. И так на одну базу может получиться 100-300 тысяч файлов. Когда заходишь в папку, а там 300 тыс. файлов, можете оценить скорость этой работы. Linux же с этим работает прекрасно. Поэтому, если у вас новая инсталляция продукта, надо пробовать Postgres на Linux.
-
Разработчикам 1С. В идеале, на всех ваших ноутбуках и рабочих ПК должен стоять бесплатный Postgres. И вы в идеале должны разворачивать себе клиент-серверную систему 1С. Да, возникнут вопросы, что серверные ключи для 1С дорогие. Ну купите мини-сервер на пять пользователей за 15 тыс. рублей. Почему надо? Очень часто сталкиваемся с тем, что разрабатываете вы для клиент-серверной системы. а разработка идет в файловой системе. А потом начинается… Так что разрабатывать надо на такой же системе, в которой планируете работать.
-
Если вы делаете переход с файловой. До этого мы обсуждали, что переходить на бесплатный Express бессмысленно, поскольку у вас база не влезет. Если вы разрабатываете базу с объемом в 100 Гб, и вам нужны данные для разработки, то переход на Express бессмысленен. На Postgres переходите и работаете – в том числе и на бесплатный.
-
Если вы работаете под Минкомсвязью, вам нужно брать ПО только из реестра Минкомсвязи – вам переход на PostgreSQL, причем только платный Postgres Pro. Других вариантов нет.
-
Причина, по которой в свое время моя команда перешла на Postgres – потому что я был смелый и любознательный патриот. Мы решили попробовать, реально ли наши умеют писать СУБД. Оказалось, умеют и круто. Более того, работать с техподдержкой Postgres Pro – одно удовольствие. Все люди говорят на русском, работают круглосуточно, подключаются быстро. Я такой техподдержки до сих пор ни у кого не видел. Кто хоть раз писал на v8@1c.ru знают, какой может быть техподдержка на русском языке. А это прямо небо и земля.
Но обычно у тех, кому надо переходить на PostgreSQL, у тех и не особо болит после перехода. А кому на Postgres не надо, но они переходят – те потом начинают говорить, что ничего не работает. Ну да, если ты не готов, то, наверное, и не работает.
Установка RedHat Enterprise Linux 8 (RHEL 8.4). Подключение RHEL8 к домену Active Directory. Запуск терминального клиента.
Операционная система – это один из краеугольных камней в фундаменте организации. От нее напрямую зависит надежность и безопасность корпоративной IT-инфраструктуры. Red Hat Enterprise Linux разработана с учетом всех требований и особенностей коммерческой эксплуатации Linux в производственной среде. Она проста в администрировании и управлении при развертывании приложений в физических, виртуальных и облачных средах. Обеспечивает высокую производительность и доступность приложений, а также обладает достаточной гибкостью, чтобы поддерживать рост организации и внедрение новых решений. Red Hat Enterprise Linux ценят за надежность, безопасность, стабильность, высокую производительность и масштабируемость, которые платформа предоставляет организациям. Клиентские решения Red Hat Enterprise Linux переносят эти инновации на рабочий стол.
Возможности обработки
Из предыдущего пункта выплывают и другие отличия postgresql от mysql, это возможности обработки данных и ограничения. Естественно, соответствие более новым стандартам дает более новые возможности.
MySQL
При выполнении запроса MySQL загружает весь ответ сервера в память клиента, при больших объемах данных это может быть не совсем удобно. В основном по функциям Postgresql превосходит Mysql, дальше рассмотрим в каких именно.
Postgresql
Postgresql поддерживает использование курсоров для перемещения по полученным данным. Вы получаете только указатель, весь ответ хранится в памяти сервера баз данных. Этот указатель можно сохранять между сеансами. Здесь поддерживается построение индексов сразу для нескольких столбцов таблицы. Кроме того, индексы могут быть различных типов, кроме hash и b-tree доступны GiST и SP-GiST для работы с городами, GIN для поиска по тексту, BRIN и Bloom.
Postgresql поддерживает регулярные выражения в запросах, рекурсивных запросов и наследования таблиц. Но тут есть несколько ограничений, например, вы можете добавить новое поле только в конец таблицы.
Путь поиска
Так называемое “Квалифицированное имя” состоит из явно указанной схемы и имени объекта (как абсолютный путь в файловой системе). Например: <схема.имя>.
Если мы не указываем схему, то нужно понять, в какой схеме искать или создавать объект. Определяют схему с помощью пути поиска, который задается параметром search_path.
В параметре search_path можно через запятую перечислить схемы, в которых нужно искать объект, если мы не указываем схему явно. search_path это что-то вроде переменной окружения PATH в Linux, для поиска команд.
Из search_path исключаются:
- несуществующие схемы;
- схемы к которым нет доступа.
А некоторые схемы всегда добавляются в search_path, даже если мы их туда не запишем. Например pg_catalog.
Реальное значение search_path показывает функция current_schemas().
postgres@postgres=# SELECT current_schemas(true);
current_schemas
---------------------
{pg_catalog,public}
(1 row)
Time: 1,945 ms
При создании нового объекта, он будет помещаться в первую указанную в search_path схему. Если посмотреть пример выше, то так как у нас нет права писать в схему pg_catalog, объекты будут создаваться в public.
Разработка
Оба проекта имеют открытый исходный код, но развиваются по-разному. Развитие MySQL нравится далеко не всем. И в этом сравнение mysql и postgresql дает много отличий.
MySQL
База данных MySQL разрабатывается компанией Oracle и ходят слухи, что компания намерено тормозит развитие движка. Было создано очень много форков проекта, в том числе форк MariaDB от разработчика оригинальной MySQL. Но все же развитие остается медленным.
Postgresql
Как было сказано в начале статьи разработка началась в университете Беркли. Затем перешла в коммерческую компанию. Сейчас программа разрабатывается независимой группой программистов и советом нескольких компаний. Новые версии выпускаются достаточно активно и получают все новые и новые функции.
