Как работают кодировки текста. откуда появляются «кракозябры». принципы кодирования. обобщение и детальный разбор
Содержание:
- Пометка порядка байтов
- Как исправить иероглифы Windows 10 путем изменения кодовых страниц
- Кодировки в windows / песочница / хабр
- Таблица Windows-1251
- Решение проблемы
- Решения проблемы с кодировкой в CMD. 1 Способ.
- Как сменить кодировку в консоли windows?
- Чем отличаются utf-8 и windows 1251
- Что такое кодировка UTF-8
- Зачем нужна кодировка
- Консоль Внедренца v.3.6.2
- Откуда взялась статья?
- Решения проблемы с кодировкой в CMD. 1 Способ.
- Методика оптимизации программного кода 1С: проведение документов
- Кодовая страница ANSI
- Чем отличаются utf-8 и windows 1251
- Навигатор по конфигурации базы 1С 8.3 Промо
- Подробное описание
- Конфликт кодировок
- Задания¶
- Особенности
- Причины отображения иероглифов вместо русских букв
- Распространенные причины проблемы с кодировкой
- Почему до сих пор используется 1251
Пометка порядка байтов
Символ-пометка (BOM) — это сигнатура в Юникоде в первых нескольких байтах файла или текстового потока, указывающих, какая кодировка Юникода используется для данных. Дополнительные сведения см. в документации по метке порядка байтов .
в Windows PowerShell любая кодировка юникода, за исключением , всегда создает спецификацию. По умолчанию PowerShell Core имеет значение для всех текстовых выходных данных.
Для обеспечения оптимальной совместимости Избегайте использования спецификаций в файлах UTF-8. платформы unix и служебные программы unix-heritage, также используемые на платформах Windows, не поддерживают спецификации.
Аналогичным образом следует избегать кодирования. UTF-7 не является стандартной кодировкой Юникода и записывается без спецификации во всех версиях PowerShell.
создание сценариев PowerShell на платформе, похожем на Unix, или использовании кросс-платформенного редактора на Windows, например Visual Studio Code, приводит к созданию файла, закодированного с помощью . эти файлы прекрасно работают в PowerShell Core, но могут нарушить работу Windows PowerShell если файл содержит символы, отличные от Ascii.
Если в скриптах необходимо использовать символы, отличные от ASCII, сохраните их как UTF-8 с помощью BOM. без спецификации Windows PowerShell правильно интерпретирует скрипт как закодированный в устаревшей кодовой странице ANSI. И наоборот, файлы, имеющие СПЕЦИФИКАЦИю UTF-8, могут быть проблематичными для платформ, подобных Unix. Многие средства UNIX, такие как ,, и некоторые редакторы, например, не узнают, как обрабатывать спецификацию.
Как исправить иероглифы Windows 10 путем изменения кодовых страниц
Кодовые страницы представляют собой таблицы, в которых определенным байтам сопоставляются определенные символы, а отображение кириллицы в виде иероглифов в Windows 10 связано обычно с тем, что по умолчанию задана не та кодовая страница и это можно исправить несколькими способами, которые могут быть полезны, когда требуется не изменять язык системы в параметрах.
С помощью редактора реестра
Первый способ — использовать редактор реестра. На мой взгляд, это самый щадящий для системы метод, тем не менее, рекомендую создать точку восстановления прежде чем начинать. Совет про точки восстановления относится и ко всем последующим способам в этом руководстве.
Обычно, это исправляет проблему с отображением русских букв. Вариация способа с помощью редактора реестра (но менее предпочтительная) — посмотреть на текущее значение параметра ACP (обычно — 1252 для изначально англоязычных систем), затем в том же разделе реестра найти параметр с именем 1252 и изменить его значение с c_1252.nls на c_1251.nls.

Путем подмена файла кодовой страницы на c_1251.nls
Второй, не рекомендуемый мной способ, но иногда выбираемый теми, кто считает, что правка реестра — это слишком сложно или опасно: подмена файла кодовой страницы в C:\ Windows\ System32 (предполагается, что у вас установлена западно-европейская кодовая страница — 1252, обычно это так. Посмотреть текущую кодовую страницу можно в параметре ACP в реестре, как было описано в предыдущем способе).
После перезагрузки Windows 10 кириллица должна будет отображаться не в виде иероглифов, а как обычные русские буквы.
Источник
Кодировки в windows / песочница / хабр
В данной статье пойдёт речь о кодировках в Windows. Все в жизни хоть раз использовали и писали консольные приложения как таковые. Нету разницы для какой причины. Будь-то выбивание процесса или же просто написать «Привет!!! Я не могу сделать кодировку нормальной, поэтому я смотрю эту статью!».
Тем, кто ещё не понимает, о чём проблема, то вот Вам:

А тут было написано:
Но никто ничего не понял.
В любом случае в Windows до 10 кодировка BAT и других языков, не использует кодировку поддерживающую Ваш язык, поэтому все русские символы будут писаться неправильно.
1. Настройка консоли в батнике
Сразу для тех, кто пишет chcp 1251 лучше написать это:
Первый способ устранения проблемы, это
Notepad
. Для этого Вам нужно открыть Ваш батник таким способом:

Не бойтесь, у Вас откроется код Вашего батника, а затем Вам нужно будет сделать следующие действия:

Если Вам ничего не помогло, то преобразуйте в UTF-8 без BOM.
2. Написание консольных программНередко люди пишут консольные программы(потому что на некоторых десктопные писать невозможно), а кодировка частая проблема.
Первый способ непосредственно Notepad , но а если нужно сначала одну кодировку, а потом другую?
Сразу для использующих chcp 1251 пишите это:
Второй способ это написать десктопную программу, или же использовать Visual Studio. Если же не помогает, то есть первое: изменение кодировки вывода(Пример на C ).
Если же не сработает:
3. Изменение chcp 1251
Если же у Вас батник, то напишите в начало:
Теперь у Нас будет нормальный вывод в консоль. На других языках (С ):
4. Сделать жизнь мёдом
При использовании данного способа Вы не сможете:
- Разрабатывать приложения на Windows ниже 10
- Спасти мир от данной проблемы
- Думать о других людях
- Разрабатывать десктопные приложения, так как Вам жизнь покажется мёдом
- Сменить Windows на версию ниже 10
- Ну и понимать людей, у которых Windows ниже 10
Установить Windows 10. Там кодировка консоли специально подходит для языка страны, и Вам больше не нужно будет беспокоиться об этой проблеме. Но у Вас появится ещё 6 проблем, и вернуться к предыдущей лицензионной версии Windows Вы не сможете.
Таблица Windows-1251
Windows-1251 (cp1251) — это стандартная 8-битная кодировка, разработанная компанией Microsoft. Она содержит практически все символы, которые Вы можете встретить на стандартной русской клавиатуре. Также 1251 имеет символы для таких языков, как белорусский, украинский, болгарский и сербский.
|
DEC |
HEX |
СИМВ |
DEC |
HEX |
СИМВ |
DEC |
HEX |
СИМВ |
|
000 |
00 |
NOP |
086 |
56 |
V |
171 |
AB |
|
|
001 |
01 |
SOH |
087 |
57 |
W |
172 |
AC |
¬ |
|
002 |
02 |
STX |
088 |
58 |
X |
173 |
AD |
|
|
003 |
03 |
ETX |
089 |
59 |
Y |
174 |
AE |
|
|
004 |
04 |
EOT |
090 |
5A |
Z |
175 |
AF |
Ї |
|
005 |
05 |
ENQ |
091 |
5B |
176 |
B0 |
° |
|
|
006 |
06 |
ACK |
092 |
5C |
177 |
B1 |
± |
|
|
007 |
07 |
BEL |
093 |
5D |
178 |
B2 |
І |
|
|
008 |
08 |
BS |
094 |
5E |
^ |
179 |
B3 |
і |
|
009 |
09 |
Табуляция |
095 |
5F |
_ |
180 |
B4 |
ґ |
|
010 |
0A |
LF |
096 |
60 |
` |
181 |
B5 |
µ |
|
011 |
0B |
VT |
097 |
61 |
a |
182 |
B6 |
¶ |
|
012 |
0C |
FF |
098 |
62 |
b |
183 |
B7 |
· |
|
013 |
0D |
CR |
099 |
63 |
c |
184 |
B8 |
Ё |
|
014 |
0E |
SO |
100 |
64 |
d |
185 |
B9 |
№ |
|
015 |
0F |
SI |
101 |
65 |
e |
186 |
BA |
Є |
|
016 |
10 |
DLE |
102 |
66 |
f |
187 |
BB |
|
|
017 |
11 |
DC1 |
103 |
67 |
g |
188 |
BC |
ј |
|
018 |
12 |
DC2 |
104 |
68 |
h |
189 |
BD |
Ѕ |
|
019 |
13 |
DC3 |
105 |
69 |
i |
190 |
BE |
Ѕ |
|
020 |
14 |
DC4 |
106 |
6A |
j |
191 |
BF |
Ї |
|
021 |
15 |
NAK |
107 |
6B |
k |
192 |
C0 |
А |
|
022 |
16 |
SYN |
108 |
6C |
l |
193 |
C1 |
Б |
|
023 |
17 |
ETB |
109 |
6D |
m |
194 |
C2 |
В |
|
024 |
18 |
CAN |
110 |
6E |
n |
195 |
C3 |
Г |
|
025 |
19 |
EM |
111 |
6F |
o |
196 |
C4 |
Д |
|
026 |
1A |
SUB |
112 |
70 |
p |
197 |
C5 |
Е |
|
027 |
1B |
ESC |
113 |
71 |
q |
198 |
C6 |
Ж |
|
028 |
1C |
FS |
114 |
72 |
r |
199 |
C7 |
З |
|
029 |
1D |
GS |
115 |
73 |
s |
200 |
C8 |
И |
|
030 |
1E |
RS |
116 |
74 |
t |
201 |
C9 |
Й |
|
031 |
1F |
US |
117 |
75 |
u |
202 |
CA |
К |
|
032 |
20 |
Пробел |
118 |
76 |
v |
203 |
CB |
Л |
|
033 |
21 |
119 |
77 |
w |
204 |
CC |
М |
|
|
034 |
22 |
120 |
78 |
x |
205 |
CD |
Н |
|
|
035 |
23 |
# |
121 |
79 |
y |
206 |
CE |
О |
|
036 |
24 |
$ |
122 |
7A |
z |
207 |
CF |
П |
|
037 |
25 |
% |
123 |
7B |
{ |
208 |
D0 |
Р |
|
038 |
26 |
& |
124 |
7C |
| |
209 |
D1 |
С |
|
039 |
27 |
‘ |
125 |
7D |
} |
210 |
D2 |
Т |
|
040 |
28 |
126 |
7E |
~ |
211 |
D3 |
У |
|
|
041 |
29 |
127 |
7F |
212 |
D4 |
Ф |
||
|
042 |
2A |
128 |
80 |
Ђ |
213 |
D5 |
Х |
|
|
043 |
2B |
+ |
129 |
81 |
Ѓ |
214 |
D6 |
Ц |
|
044 |
2C |
, |
130 |
82 |
‚ |
215 |
D7 |
Ч |
|
045 |
2D |
— |
131 |
83 |
ѓ |
216 |
D8 |
Ш |
|
046 |
2E |
132 |
84 |
„ |
217 |
D9 |
Щ |
|
|
047 |
2F |
133 |
85 |
… |
218 |
DA |
Ъ |
|
|
048 |
30 |
134 |
86 |
† |
219 |
DB |
Ы |
|
|
049 |
31 |
1 |
135 |
87 |
‡ |
220 |
DC |
Ь |
|
050 |
32 |
2 |
136 |
88 |
€ |
221 |
DD |
Э |
|
051 |
33 |
3 |
137 |
89 |
‰ |
222 |
DE |
Ю |
|
052 |
34 |
4 |
138 |
8A |
Љ |
223 |
DF |
Я |
|
053 |
35 |
5 |
139 |
8B |
‹ |
224 |
E0 |
а |
|
054 |
36 |
6 |
140 |
8C |
Њ |
225 |
E1 |
б |
|
055 |
37 |
7 |
141 |
8D |
Ќ |
226 |
E2 |
в |
|
056 |
38 |
8 |
142 |
8E |
Ћ |
227 |
E3 |
г |
|
057 |
39 |
9 |
143 |
8F |
Џ |
228 |
E4 |
д |
|
058 |
3A |
144 |
90 |
Ђ |
229 |
E5 |
е |
|
|
059 |
3B |
145 |
91 |
‘ |
230 |
E6 |
ж |
|
|
060 |
3C |
< |
146 |
92 |
’ |
231 |
E7 |
з |
|
061 |
3D |
= |
147 |
93 |
“ |
232 |
E8 |
и |
|
062 |
3E |
> |
148 |
94 |
” |
233 |
E9 |
й |
|
063 |
3F |
149 |
95 |
• |
234 |
EA |
к |
|
|
064 |
40 |
@ |
150 |
96 |
– |
235 |
EB |
л |
|
065 |
41 |
A |
151 |
97 |
— |
236 |
EC |
м |
|
066 |
42 |
B |
152 |
98 |
237 |
ED |
н |
|
|
067 |
43 |
C |
153 |
99 |
238 |
EE |
о |
|
|
068 |
44 |
D |
154 |
9A |
љ |
239 |
EF |
п |
|
069 |
45 |
E |
155 |
9B |
› |
240 |
F0 |
р |
|
070 |
46 |
F |
156 |
9C |
њ |
241 |
F1 |
с |
|
071 |
47 |
G |
157 |
9D |
ќ |
242 |
F2 |
т |
|
072 |
48 |
H |
158 |
9E |
ћ |
243 |
F3 |
у |
|
073 |
49 |
I |
159 |
9F |
џ |
244 |
F4 |
ф |
|
074 |
4A |
J |
160 |
A0 |
245 |
F5 |
х |
|
|
075 |
4B |
K |
161 |
A1 |
Ў |
246 |
F6 |
ц |
|
076 |
4C |
L |
162 |
A2 |
ў |
247 |
F7 |
ч |
|
077 |
4D |
M |
163 |
A3 |
Ј |
248 |
F8 |
ш |
|
078 |
4E |
N |
164 |
A4 |
¤ |
249 |
F9 |
щ |
|
079 |
4F |
O |
165 |
A5 |
Ґ |
250 |
FA |
ъ |
|
080 |
50 |
P |
166 |
A6 |
¦ |
251 |
FB |
ы |
|
081 |
51 |
Q |
167 |
A7 |
§ |
252 |
FC |
ь |
|
082 |
52 |
R |
168 |
A8 |
Ё |
253 |
FD |
э |
|
083 |
53 |
S |
169 |
A9 |
254 |
FE |
ю |
|
|
084 |
54 |
T |
170 |
AA |
Є |
255 |
FF |
я |
|
085 |
55 |
U |
Решение проблемы
В реестре Windows нужно открыть ветку HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Control\Nls\CodePage, найти в ней параметры «1250», «1252» и «1253» и установить для каждого из них значение «c_1251.nls». Сделать это можно несколькими способами:
Способ 1
1) открыть «Редактор реестра». Для этого нужно нажать на клавиатуре кнопку «Windows» (обычно с изображением логотипа Windows, находится в нижнем ряду, слева, между кнопками Ctrl и Alt) и, удерживая ее, нажать кнопку «R» (в русской раскладке «К»). Появится окно запуска программ. В нем нужно написать regedit и нажать кнопку «ОК»; 2) последовательно открывая соответствующие папки в левой части «Редактора реестра», зайти в ветку HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Control\Nls\CodePage. Это значит, что нужно открыть сначала папку «HKEY_LOCAL_MACHINE», в ней открыть папку «SYSTEM», в ней – «CurrentControlSet» и т.д.; 3) когда доберетесь до раздела «CodePage» и выделите его в левой части «Редактора реестра», в его правой части появится довольно большой список параметров. Нужно отыскать среди них параметры «1250», «1252» и «1253». 4) дважды щелкнуть мышкой по параметру «1250». Откроется окно «Изменение строкового параметра». В нем содержание поля «Значение» нужно изменить на «c_1251.nls» и нажать кнопку «ОК» (см.рис.). Затем аналогичным образом изменить на «c_1251.nls» значение параметров «1252» и «1253». 5) закрыть окно редактора реестра и перезагрузить компьютер. После перезагрузки проблема с неправильным отображением шрифтов должна исчезнуть.
Способ 2
Все указанные выше изменения в системный реестр можно внести немного проще, используя соответствующий REG-файл. REG-файлы (их часто называют твиками реестра) — это такие специальные файлы, при открытии которых все предусмотренные в них изменения вносятся в реестр автоматически. Вам остается только подтвердить эти изменения и перезагрузить компьютер. Открывать REG-файлы необходимо от имени администратора компьютера. Подробнее об этом читайте . Чтобы получить архив с REG-файлом, осуществляющим описанные выше действия, нажмите сюда.
В этой статье рассмотрено, почему вместо русских букв, возникают квадратики, непонятные символы, кракозябры, вопросительные знаки, точки, каракули или кубики в windows 7, vista, XP?
Что делать, чтобы избавиться от этих явлений? Универсального рецепта — нет. Много зависит от версии виндовс, да и самой сборки.
Первая причина, почему такое происходит – сбой кодировок. Нарушается целостность реестра, и происходят сбои. Только не всегда это основной источник.
Часто бывает, что даже на ново установленной операционной системе, после запуска некоторых программ вместо русских букв возникают квадратики, непонятные символы, крякозябры, вопросительные знаки, точки, каракули или кубики.
Если же проблема с цифрами, тогда она быстро , а избавиться от знаков вопросов вместо нормальных букв поможет эта инструкция.

Особенно часто такое случается после установки русификаторов. Народные «умельцы», не учитывают все, а возможно и переводы делают только под одну операциоку.
Возможно и не это главное, если учесть, что все заключаться в кодировке. Может программа, просто не поддерживает определенные буквы.
Хотя это и удивительно, но по умолчанию операционная система windows 7 вместо русских букв в некоторых программа отображает квадратики, непонятные символы, кракозябры, вопросительные знаки, точки, каракули или кубики.
Я всегда после переустановки вношу изменения в реестр, даже если все работает нормально. В будущем проблем с непонятными символами не возникает.
Решения проблемы с кодировкой в CMD. 1 Способ.
Для решения проблемы нужно просто использовать текстовой редактор, с помощью которого можно сохранить текст в кодировке «866». Для этих целей прекрасно подходит «Notepad++
» (Ссылку для загрузки Вы можете найти в моём Twitter-e).
Скачиваем и устанавливаем на свой компьютер «Notepad++
После запуска «Notepad++
» запишете в документ те же строки, которые мы уже ранние записывали в стандартный блокнот.
Теперь осталось сохранить документ с именем «2.bat» в правильной кодировке. Для этого идём в меню «Кодировки
>Кодировки >Кириллица >OEM-866 »

и теперь сохраняем файл с именем «2.bat» и запускаем его! Поле запуска результат на лицо.

Как видим, текст на Русском в CMD отобразился, как положено.
Как сменить кодировку в консоли windows?
Файл должен выводиться в utf-8, а в консоли – 866, в итоге в браузере отображаются ромбы.
После команды chcp 65001 ничего не поменялось.
Но у меня в CodePage таких файлов нет. Есть типы REG.SZ по умолчанию и 4 файла с номерами 932 936 949 950
Вариант постоянно изменять в консоли chcp не подходит, но и не работает. Lucida console подключен в консоли. Cygwin64 Terminal и Gitbash не запускает python server
Какие-то ещё есть варианты?
generate.py
horoscope.py
При запуске кода (python generate_all.py из командной строки или Ctrl B в саблайме) в этой же папке генерируется файл index.html, и, если поднять сервер в этой же директории (python -m http.server) из консоли win, то в браузере ромбы.
Чем отличаются utf-8 и windows 1251
UTF-8 — это много-байтовая кодировка, а Windows- 1251 однобайтовая. И более того, отличие только в кириллице.
Количество байтов кириллицы в UTF-8 будет в 2 раза больше, чем 1). латиницы в UTF-8 и 2). латиницы + кириллицы в Windows- 1251 → пример
Главное отличие кодировок – это используемый набор символов. В UTF-8 гораздо больше количество символов возможно представить, чем в Windows- 1251. Кодировка Windows- 1251 однобайтовая, т.е. представить в ней можно только 255 символов. Для кириллицы, впрочем, этого вполне достаточно, именно поэтому однобайтовые кодировки до сих пор так массово применяются.
Что такое кодировка UTF-8
UTF-8 – в настоящее время распространённая кодировка, реализующая представление Юникода, совместимое с 8-битным кодированием текста. Нашла широкое применение в операционных системах и веб-пространстве. Текст, состоящий только из символов Юникода с номерами меньше 128, при записи в UTF-8 превращается в обычный текст ASCII. Остальные символы Юникода изображаются последовательностями длиной от 2 до 6 байт.
Символ в кодировке UTF-8 может кодироваться аж 6 байтами (пока используется только 4 и больше не планируется). Для русского языка, например, символ занимает 2 байта. Все символы, которые есть в таблице символов – поддерживаются этой кодировкой. К примеру, если вам нужен знак копирайта (), то вам не нужно искать особый шрифт или же изображать символов в графическом формате.
Скопировать ссылку
Зачем нужна кодировка
Кодировка (Charset) — способ отображения кода на экране, соответствие набора символов набору числовых значений. О ней сообщает строка Content-Type и сервер в header запросе.

Студентка списывала реферат с формулами, а на сайте слетела кодировка. Реальная история
Google рекомендует всегда указывать сведения о кодировке, чтобы текст точно корректно отображался в браузере пользователя.
Кодировка влияет на SEO?
Разберемся, как кодировка на сайте влияет на индексацию в Яндекс и Google.
Яндекс четко заявляет:
Позиция Google такая же. Поисковики не рассматривают Charset как фактор ранжирования или сигнал для индексирования, тем не менее, она косвенно влияет на трафик и позиции.
Если кодировка сервера не совпадает с той, что указана на сайте, пользователи увидят нечитабельные символы вместо контента. На таком сайте сложно что-либо понять, так что скорее всего пользователи сбегут, а на сайте будут расти отказы.

Пример страницы со слетевшей кодировкой
Поэтому она важна для SEO, хоть и влияет на него косвенно через поведенческие. Пользователи должны видеть читабельный текст на человеческом языке, чтобы работать с сайтом.
Консоль Внедренца v.3.6.2
Идея данной обработки заключается в создании простого, функционального и универсального инструментария для внедренцев и программистов 1С, который будет работать как в толстом клиенте на обычных и на управляемых формах, так и в тонком клиенте. Интерфейс и логика работы максимально идентичны у обычных форм и управляемых. Инструментарий включает в себя: Консоль кода, Консоль запросов, Консоль отчетов (СКД), Универсальную обработку объектов, Средства для работы с таблицами базы данных 1С, Редактирование регистров сведений базы, Инструмент по работе с табличными документами — загрузка данных из табличного документа.
1 стартмани
Откуда взялась статья?
Одним из важных составляющих в области ИИ является обработка текстов на естественном языке. В процессе изучения данной тематики я начал задавать себе вопросы, которые в конечном итоге привели меня к изучению кодировок, представлению текстов в памяти, как они преобразуются, приводятся к нормальной форме. Я плохо понимал эту тему в начале, потребовалось немало времени и мозгового ресурса, чтобы понять, принять и запомнить некоторые вещи. Написанием данной статьи я хочу облегчить жизнь людям, которые столкнутся с необходимостью чтения и обработки текстов на Python и самому закрепить изученное. А некоторыми полезными поинтами своего изучения я постараюсь поделиться в данной статье.
Важная ремарка: я не являюсь специалистом в области обработки текстов. Изложенный материал является результатом исключительно любительского изучения.
Решения проблемы с кодировкой в CMD. 1 Способ.
Для решения проблемы нужно просто использовать текстовой редактор, с помощью которого можно сохранить текст в кодировке «866». Для этих целей прекрасно подходит «Notepad++
» (Ссылку для загрузки Вы можете найти в моём Twitter-e).
Скачиваем и устанавливаем на свой компьютер «Notepad++
После запуска «Notepad++
» запишете в документ те же строки, которые мы уже ранние записывали в стандартный блокнот.
Теперь осталось сохранить документ с именем «2.bat» в правильной кодировке. Для этого идём в меню «Кодировки
>Кодировки >Кириллица >OEM-866 »

и теперь сохраняем файл с именем «2.bat» и запускаем его! Поле запуска результат на лицо.

Как видим, текст на Русском в CMD отобразился, как положено.
Методика оптимизации программного кода 1С: проведение документов
Описание простого метода анализа производительности программного кода 1С, способов его оптимизации и оценки результатов в виде числовых показателей прироста производительности. Не требует сторонних программных продуктов, используются только типовые возможности платформ 1С.
Методика проверена на линейке платформ начиная с 1С:Предприятие 8.2 (обычные формы, управляемые формы). Позволяет ускорить проведение проблемных документов в 3 и более раз, провести проверку корректности формирования проводок оптимизированным кодом и подтвердить результаты оптимизации реальными замерами производительности в режиме предприятия.
К публикации приложены демонстрационные базы для режимов обычного и управляемого приложения на платформе 1С:Предприятие 8.3 (8.3.9.2033).
1 стартмани
Кодовая страница ANSI
| Псевдоним (а) | ANSI (неверное название) |
|---|---|
| Стандарт | Стандарт кодирования WHATWG |
| Расширяется | US-ASCII |
| Предшествует | ISO 8859 |
| Преемник | Юникод UTF-16 (в Win32 API) |
Кодовые страницы ANSI (официально называемые «кодовыми страницами Windows» после того, как Microsoft приняла неправильное употребление первого термина) используются для приложений, не поддерживающих Unicode (скажем, ориентированных на байты ), использующих графический пользовательский интерфейс в системах Windows. Термин «ANSI» является неправильным, потому что эти кодовые страницы Windows не соответствуют ни одному стандарту ANSI; Кодовая страница 1252 была основана на раннем проекте ANSI, который стал международным стандартом ISO 8859-1 , который добавляет еще 32 управляющих кода и пространство для 96 печатаемых символов. Среди других отличий кодовые страницы Windows выделяют печатаемые символы в дополнительное пространство управляющего кода, что делает их в лучшем случае неразборчивыми для совместимых со стандартами операционных систем.)
Большинство устаревших кодовых страниц «ANSI» имеют номера кодовых страниц в шаблоне 125x. Тем не менее, (тайский) и восточноазиатские многобайтовые кодовые страницы ANSI ( , , , ), все из которых также используются в качестве кодовых страниц OEM, пронумерованы для соответствия аналогичным (но не идентичным) кодовым страницам IBM. кодировки. Хотя кодовая страница 1258 также используется как кодовая страница OEM, она является оригинальной для Microsoft, а не расширением существующей кодировки. IBM присвоила свои собственные, разные номера вариантам Microsoft, они приведены для справки в приведенных ниже списках, где это применимо.
Все кодовые страницы Windows 125x, а также 874 и 936, помечены Internet Assigned Numbers Authority (IANA) как « номер Windows», хотя «Windows-936» рассматривается как синоним « GBK ». Кодовая страница Windows 932 вместо этого помечена как «Windows-31J».
Кодовые страницы ANSI Windows, и особенно кодовая страница , были так названы, поскольку они якобы были основаны на черновиках, представленных или предназначенных для ANSI. Однако ANSI и ISO не стандартизировали ни одну из этих кодовых страниц. Вместо этого они либо:
- Надмножества стандартных наборов, таких как ISO 8859 и различных национальных стандартов (например, Windows-1252 и ISO-8859-1 ),
- Основные их модификации (делающие их несовместимыми в разной степени, например, Windows-1250 и ISO-8859-2 )
- Отсутствие параллельного кодирования (например, Windows-1257 против ISO-8859-4 ; ISO-8859-13 был введен намного позже). Кроме того, Windows-1251 не следует ни ISO-стандартизированному ISO-8859-5, ни преобладающему в то время KOI-8 .
Microsoft присвоила около двенадцати типографских и деловых символов (включая, в частности, знак евро , €) в CP1252 кодовые точки 0x80–0x9F, которые в ISO 8859 присвоены управляющим кодам C1 . Эти назначения также присутствуют во многих других кодовых страницах ANSI / Windows в тех же кодовых точках. Windows не использовала управляющие коды C1, поэтому это решение не имело прямого влияния на пользователей Windows. Однако при включении в файл, передаваемый на совместимую со стандартами платформу, такую как Unix или MacOS, информация была невидимой и потенциально опасной.
Чем отличаются utf-8 и windows 1251
UTF-8 — это много-байтовая кодировка, а Windows- 1251 однобайтовая. И более того, отличие только в кириллице.
Количество байтов кириллицы в UTF-8 будет в 2 раза больше, чем 1). латиницы в UTF-8 и 2). латиницы + кириллицы в Windows- 1251 → пример
Главное отличие кодировок – это используемый набор символов. В UTF-8 гораздо больше количество символов возможно представить, чем в Windows- 1251. Кодировка Windows- 1251 однобайтовая, т.е. представить в ней можно только 255 символов. Для кириллицы, впрочем, этого вполне достаточно, именно поэтому однобайтовые кодировки до сих пор так массово применяются.
Навигатор по конфигурации базы 1С 8.3 Промо
Универсальная внешняя обработка для просмотра метаданных конфигураций баз 1С 8.3.
Отображает свойства и реквизиты объектов конфигурации, их количество, основные права доступа и т.д.
Отображаемые характеристики объектов: свойства, реквизиты, стандартные рекизиты, реквизиты табличных частей, предопределенные данные, регистраторы для регистров, движения для документов, команды, чужие команды, подписки на события, подсистемы.
Отображает структуру хранения объектов базы данных, для регистров доступен сервис «Управление итогами».
Платформа 8.3, управляемые формы. Версия 1.1.0.83 от 24.06.2021
3 стартмани
Подробное описание
Юникод — это мировой стандарт кодировки символов. Система использует Юникод исключительно для обработки символов и строк. Подробное описание всех аспектов Юникода см. в стандарте Юникода.
Windows поддерживает юникод и традиционные кодировки. традиционные кодировки, такие как Windows кодовые страницы, используют 8-разрядные значения или сочетания 8-разрядных значений для представления символов, используемых в параметрах определенного языка или географического региона.
По умолчанию PowerShell использует набор символов Юникода. Однако несколько командлетов имеют параметр кодирования , который может указывать кодировку для другой кодировки. Этот параметр позволяет выбрать конкретную кодировку символов, необходимую для взаимодействия с другими системами и приложениями.
Следующие командлеты имеют параметр Encoding :
- Microsoft.PowerShell.Management
- Add-Content
- Get-Content
- Set-Content
- Microsoft.PowerShell.Utility
- Export-Clixml
- Export-Csv
- Export-PSSession
- Format-Hex
- Import-Csv
- Out-File
- Select-String
- Send-MailMessage
Конфликт кодировок
Полностью локализованная консоль в идеале должна поддерживать все мыслимые и немыслимые кодировки приложений, включая свои собственные команды и команды Windows, меняя «на лету» кодовые страницы потоков ввода и вывода. Задача нетривиальная, а иногда и невозможная — кодовые страницы DOS (CP437, CP866) плохо совмещаются с кодовыми страницами Windows и Unicode.
История кодировок здесь: О кодировках и кодовых страницах / Хабр (habr.com)
Исторически кодовой страницей Windows является CP1251 (Windows-1251, ANSI, Windows-Cyr), уверенно вытесняемая 8-битной кодировкой Юникода CP65001 (UTF-8, Unicode Transformation Format), в которой выполняется большинство современных приложений, особенно кроссплатформенных. Между тем, в целях совместимости с устаревшими файловыми системами, именно в консоли Windows сохраняет базовые кодировки DOS — CP437 (DOSLatinUS, OEM) и русифицированную CP866 (AltDOS, OEM).
Поскольку в консоли постоянно происходит передача управления от приложений к собственно командному процессору и обратно, регулярно возникает «конфликт кодировок», наглядно иллюстрируемый таблица 1 и 2, сформированных следующим образом:
Были запущены три консоли — CMD, PS и WPS. В каждой консоли менялась кодовая страница с помощью команды CHCP, выполнялась команда Echo c двуязычной строкой в качестве параметра (табл. 1), а затем в консоли запускалось тестовое приложение, исходные файлы которого были созданы в кодировке UTF-8 (CP65001): первая строка формируется и направляется в поток главным модулем, вторая вызывается им же, формируется в подключаемой библиотеке классов и направляется в поток опять главным модулем, третья строка полностью формируется и направляется в поток подключаемой библиотекой.
Командную часть задания все консоли локализовали практически без сбоев во всех кодировках, за исключением: в WPS неверно отображена русскоязычная часть команды во всех кодировках.
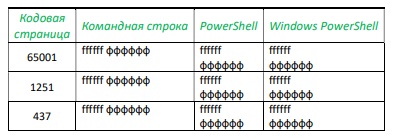 Табл. 1. Результат выполнения команды консоли Echo ffffff фффффф
Табл. 1. Результат выполнения команды консоли Echo ffffff фффффф
Вывод тестового приложения локализован лишь в 50% испытаний, как показано в табл.2.
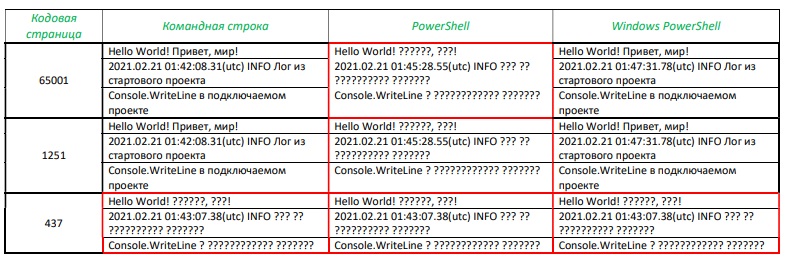 Табл. 2. Результат запуска приложения LoggingConsole.Test
Табл. 2. Результат запуска приложения LoggingConsole.Test
По умолчанию Windows устанавливает для консоли кодовые страницы DOS. Чаще всего CP437, иногда CP866. Актуальные версии командной строки cmd.exe способны локализовать приложения на основе русифицированной кодовой страницы 866, но не 437, отсюда и изначальный конфликт кодировок консоли и приложения. Поэтому
Задания¶
-
Доработайте прототип чата из прошлого урока таким образом, чтобы он корректно работал с русским языком (используйте методы кодирования и декодирования байтовых строк).
2. Напишите функцию для шифрования файла шифром Цезаря.
Расшифруйте:
key = 2 s = 'Oquv uvctu ctg qdugtxgf vq dg ogodgtu qh dkpctb uvct ubuvgou'
3. Напишите функцию для шифрования файла шифром пар.
Расшифруйте:
d_1 = 109, 122, 106, 115, 100, 99, 105, 120, 110, 98, 121, 118, 107 d_2 = 112, 103, 108, 104, 111, 102, 119, 117, 97, 101, 116, 113, 114 s = 'A hynk wh na nhykdadpwfnj delbfy fdahwhywaz dc n jxpwadxh hmsbkdwo dc mjnhpn sbjo ydzbysbk et wyh dia zknqwyt.'
Особенности
Windows-1251 выгодно отличается от других 8‑битных кириллических кодировок (таких как CP866, KOI8-R и ISO 8859-5) наличием практически всех символов, использующихся в русской типографике для обычного текста (отсутствует только значок ударения); Она также содержит все символы для других славянских языков: украинского, белорусского, сербского, македонского и болгарского.
Windows-1251 имеет два недостатка:
- строчная буква «я» имеет код 0xFF (255 в десятичной системе). Она является «виновницей» ряда неожиданных проблем в программах без поддержки чистого 8-го бита, а также (гораздо более частый случай) использующих этот код как служебный (в CP437 он обозначает «неразрывный пробел», в Windows-1252 — ÿ, оба варианта практически не используются; число же -1, в дополнительном коде длиной 8 бит представляющееся числом 255, часто используется в программировании как специальное значение). Тот же недостаток имеет и KOI8-R, но в ней 0xFF есть заглавный твердый знак, который применяется редко (только при написании одними лишь заглавными буквами).
- отсутствуют символы псевдографики, имеющиеся в CP866 и KOI8 (хотя для самих Windows, для которых она предназначена, в них не было нужды, это делало несовместимость двух использовавшихся в них кодировок заметнее).
Также как недостаток может рассматриваться отдельное расположение буквы «ё», тогда как остальные символы расположены строго в алфавитном порядке. Это усложняет программы лексикографического упорядочения.
Синонимы: CP1251; ANSI (только в русскоязычной ОС Windows).
Причины отображения иероглифов вместо русских букв
Обычно проблемы с кодировкой встречаются не во всех текстовых файлах и установщиках программного обеспечения сразу. Например, при открытии инсталлера ПО его название корректно, а вот содержимое неправильно отображается. Или при написании текста в «блокноте» появляются вопросы и кракозябры.

К причинам некорректного отображения кириллицы относят:
- Ошибка русификации приложений.
- Сбой обновлений.
- Использование английской версии операционной системы.
- Установка взломанной Windows 10.
Пользователи спешат исправить неполадки простой переустановкой ОС. Но это не всегда помогает. Особенно, если проблема заключается не в Виндовсе.
Частый вопрос от пользователей – почему в ОС Windows 10 в известной программе «Налогоплательщик ЮЛ» отображаются иероглифы и кракозябры. Данная проблема решается просто: в шрифтовую систему устанавливают MS Sans Serif.

Распространенные причины проблемы с кодировкой
Проблемы с кодировкой возникают, если кодировка VS Code в целом или вашего файла скрипта не совпадает с кодировкой, ожидаемой в PowerShell. В PowerShell нет способа автоматически определить кодировку файла.
Проблемы с кодировкой более вероятны при использовании символов не из 7-разрядной кодировки ASCII. Пример:
- Расширенные небуквенные символы, такие как длинное тире (), неразрывный пробел () или левая двойная кавычка ().
- Латинские символы с диакритикой (, )
- Нелатинские символы, такие как кириллица (, )
- Символы иероглифического письма (, , ).
Распространенные причины проблем с кодировкой:
- Параметры кодировок по умолчанию VS Code и PowerShell не были изменены. В версиях до PowerShell 5.1 (включительно) кодировка по умолчанию отличается от используемой в VS Code.
- Открыт другой редактор, и файл перезаписан в новой кодировке. Это часто происходит с интегрированной средой сценариев.
- Файл возвращается в систему управления версиями в кодировке, отличающейся от той, которая ожидается в VS Code или PowerShell. Это может произойти, когда участники совместной работы используют редакторы с различными конфигурациями кодировок.
Как определить наличие проблемы с кодировкой
Часто ошибки кодирования в скриптах представляются как ошибки синтаксического анализа. Если вы видите странные последовательности символов в скрипте, это может быть проблемой. В примере ниже тире () отображается в виде символов :
Эта проблема возникает, так как VS Code кодирует символ в UTF-8 как байты . Если эти байты декодируются в кодировке Windows-1252, они интерпретируются как символы .
Некоторые странные последовательности символов, которые можно видеть:
- вместо .
- вместо .
- вместо .
- вместо (неразрывный пробел);
- вместо .
Этот удобный справочник перечисляет распространенные шаблоны, которые указывают на проблему между кодировками UTF-8 и Windows-1252.
Почему до сих пор используется 1251
Существует несколько причин, почему 1251 продолжает пользоваться большой популярностью среди разработчиков онлайн ресурсов:
- Многие программисты php используют стандартную кодировку, поскольку OC Windows ее поддерживает в режиме по умолчанию. И хотя в последнее время разработчики стали активно внедрять UTF-8, все же 1251 пока не сдает свои активные позиции
- Если брать для примера старую версию MySQL до четвертой, то стоит отметить, что при включении даже тестового режима, вылезало множество ошибок в UTF-8. Только после выпуска 4.1 многие «глюки» были исправлены. Существует категория программистов, которая вовсе остается верна 1251, а их последователи рьяно берут с них пример и даже не собираются использовать нечто другое
- Поскольку один символ в системе 1251 весит меньше (один байт), то вполне логично, что возникает некая экономия в отличие от последнего варианта.
По сравнению с данной кодировкой, UTF-8 считается более оптимальным вариантом, поскольку она может распознать большее количество символов.
- Возможно включение любых знаков из набора Юникода. Кроме того, вполне логично, что здесь поддерживается 100 000 символов против 256. Здесь можно найти от стандартных смайликов до апострофа абсолютно все. Их использование возможно в любом документе. Кроме того, их можно прочитать даже в редакторе, что исключает вероятность появления нечитабельных знаков
- Ранее существовало мнение о том, что современный utf занимает больше места. В итоге оказалось, что символы также весят всего лишь байт. Значит, стоит сделать вывод о том, что увеличение веса странички не происходит и ее использование такое же легкое. Однако, если используется только русский алфавит, то в таком случае размер будет увеличен вдвое, поскольку изначально кириллица не включена в систему
- Система считается одной из самых универсальных, которые уже смогли достать. В таком случае можно создавать сайты для любого населения мира. Можно уже не думать о том, какая кодировка используется, поскольку Юникод является универсальной вещью
- UTF – это оптимальный вариант работы с php страницами.
Важно отметить, что изначально многие разработчики стали использовать 1251. И хотя сейчас тенденции поменялись, последователей именно этой кодировки осталось, а значит она продолжает пользоваться большой популярностью среди пользователей. ,
,
И хотя сейчас тенденции поменялись, последователей именно этой кодировки осталось, а значит она продолжает пользоваться большой популярностью среди пользователей. ,
Кто-то считает, что универсальная utf – это неплохое решение, которое устанавливается для современных ресурсов, но 1251 – это проверенный алгоритм для стран, использующих кириллицу.
Стоит отметить, что в большинстве случаев используют автоматические переключение. Так, например, если понадобится прочитать информацию на иностранном языке или на русском, достаточно просто переключить кодировку на актуальный формат.
Вероятно, что в будущем 1251 станет еще меньше востребованной, а на смену придут новые проверенные системы. Однако сегодня многие все же используют именно ее.
Также важно принять на заметку, что для работы с utf знание английского языка является обязательным условием
