Что такое кодировка utf-8? руководство для непрограммистов
Содержание:
- Время действия документа и кэш
- C0 Controls
- Символы UTF-8 в веб-разработке
- Кодировки стандарта UNICODE
- Definition and Usage
- Другие Места, Где Кодирование Важно
- UTF-8 против UTF-16
- Что писать в теге meta description?
- What is meta charset?
- description (краткое описание)
- HTML Tags
- Разрешенные кодировки
- Важность кодирования символов
- Ссылки на символы
- UTF-8 Basic Latin
- Автоматический переход на другую страницу
- Первый способ: Скопировал в Таблице — Вставил там, где нужно.
- Как установить UTF-8 кодировку в PHP
Время действия документа и кэш
Пример:
<meta http-equiv=»expires» content=»Sun, 24 jan 2010 12:28:36 GMT+03:00″>
Для того чтобы ускорить загрузку страницы, а так же сэкономить трафик современные браузеры сохраняют посещаемые пользователем страницы в кэш (на жёсткий диск), и при повторном посещении загружают их не с сервера, а непосредственно с кэша. На самом деле такая функция хороша собой.. но есть одно «но», дело в том что в браузере может отображаться уже устаревшая информация, какой либо страницы. Представьте, к примеру, Ваш сайт представляет собой некое периодическое новостное интернет издание, а пользователь получит, вместо самых свежих новостей, уже устаревшую информацию, ту которая хранится у него в кэше!! и не разобравшись в чем «беда» примет Ваш сайт за «мертвый» заброшенный и никем не обновляемый.
Для того чтобы принудительно заставить браузер загружать ту или иную страницу не с жёсткого диска, а с сервера необходим мета тег с данным синтаксисом, где указывается день недели, число месяц год время (чч:мм:сс) и часовой пояс(GMT+03:00 — время Московское + три часа). День недели и время дня можно не указывать. Теперь при чтении страницы браузером страница будет грузится с сервера, если указанная дата и время настало или просрочено, и напротив из кэша если указанное время еще не наступило.
Ниже на всякий случай приведены таблицы сокращений от Английских слов на месяцы и дни недели
|
|
Атрибуту content можно присвоить значение «0» <meta http-equiv=»Expires» content=»0″> в этом случае страница всегда будет загружаться с сервера.
И еще.. некоторые поисковые роботы могут отказаться индексировать документ с заведомо устаревшей датой. — не искушайте судьбу..
Пример:
<meta http-equiv=»pragma» content=»no-cache»>
А такая запись вовсе запретит браузеру кэшировать данную страницу.
C0 Controls
The control characters were originally designed to control
hardware devices.
Control characters (except horizontal tab, carriage return, and line feed)
have nothing to do inside an HTML document.
| Char | Dec | Hex | Description |
|---|---|---|---|
| NUL | 0000 | null character | |
| SOH | 1 | 0001 | start of header |
| STX | 2 | 0002 | start of text |
| ETX | 3 | 0003 | end of text |
| EOT | 4 | 0004 | end of transmission |
| ENQ | 5 | 0005 | enquiry |
| ACK | 6 | 0006 | acknowledge |
| BEL | 7 | 0007 | bell (ring) |
| BS | 8 | 0008 | backspace |
| HT | 9 | 0009 | horizontal tab |
| LF | 10 | 000A | line feed |
| VT | 11 | 000B | vertical tab |
| FF | 12 | 000C | form feed |
| CR | 13 | 000D | carriage return |
| SO | 14 | 000E | shift out |
| SI | 15 | 000F | shift in |
| DLE | 16 | 0010 | data link escape |
| DC1 | 17 | 0011 | device control 1 |
| DC2 | 18 | 0012 | device control 2 |
| DC3 | 19 | 0013 | device control 3 |
| DC4 | 20 | 0014 | device control 4 |
| NAK | 21 | 0015 | negative acknowledge |
| SYN | 22 | 0016 | synchronize |
| ETB | 23 | 0017 | end transmission block |
| CAN | 24 | 0018 | cancel |
| EM | 25 | 0019 | end of medium |
| SUB | 26 | 001A | substitute |
| ESC | 27 | 001B | escape |
| FS | 28 | 001C | file separator |
| GS | 29 | 001D | group separator |
| RS | 30 | 001E | record separator |
| US | 31 | 001F | unit separator |
| DEL | 127 | 007F | delete (rubout) |
❮ Previous
Next ❯
Символы UTF-8 в веб-разработке
UTF-8 – наиболее распространенный метод кодирования символов, используемый сегодня в Интернете, и набор символов по умолчанию для HTML5. Таким образом хранятся персонажи более 95% всех веб-сайтов, в том числе и ваш собственный. Кроме того, распространенные методы передачи данных через Интернет, такие как XML и JSON, кодируются стандартами UTF-8.
Поскольку теперь это стандартный метод кодирования текста в Интернете, все страницы вашего сайта и базы данных должны использовать UTF-8. Система управления контентом или конструктор веб-сайтов по умолчанию сохранят ваши файлы в формате UTF-8, но все же рекомендуется убедиться, что вы придерживаетесь этой передовой практики.
Текстовые файлы, закодированные с помощью UTF-8, должны указывать на это программному обеспечению, обрабатывающему их. В противном случае программа не сможет должным образом преобразовать двоичный код обратно в символы. В файлах HTML вы можете увидеть строку кода, подобную следующей, вверху:
Это сообщает браузеру, что файл HTML закодирован в UTF-8, чтобы браузер мог преобразовать его обратно в разборчивый текст.
Кодировки стандарта UNICODE
Юникод (англ. Unicode) — стандарт кодирования символов, позволяющий представить знаки почти всех письменностей мира, и специальных символов. Представляемые в юникоде символы кодируются целыми числами без знака. Юникод имеет несколько форм представления символов в компьютере: UTF-8, UTF-16 (UTF-16BE, UTF-16LE) и UTF-32 (UTF-32BE, UTF-32LE). (Англ. Unicode transformation format — UTF).UTF-8 — это в настоящее время распространённая кодировка, которая нашла широкое применение в операционных системах и веб-пространстве. Текст, состоящий из символов Unicode с номерами меньше 128 (область с кодами от U+0000 до U+007F), содержит символы набора ASCII с соответствующими кодами. Далее расположены области знаков различных письменностей, знаки пунктуации и технические символы. Под символы кириллицы выделены области знаков с кодами от U+0400 до U+052F, от U+2DE0 до U+2DFF, от U+A640 до U+A69F.
Кодировка UTF-8 является универсальной и имеет внушительный резерв на будущее. Это делает ее наиболее удобной кодировкой для использования в интернете.
HTML Символы
Кодирование URL
Definition and Usage
The tag defines metadata about an
HTML document. Metadata is data (information) about data.
tags always go inside the <head> element,
and are typically used to specify character set, page description,
keywords, author of the document, and viewport settings.
Metadata will not be displayed on the page, but is machine parsable.
Metadata is used by browsers (how to display content or reload page),
search engines (keywords), and other web services.
There is a method to let web designers take control over the viewport
(the user’s visible area of a web page), through the tag (See «Setting
The Viewport» example below).
Другие Места, Где Кодирование Важно
Нам не просто нужно учитывать кодировку символов при программировании. Тексты могут окончательно испортиться во многих других местах.
наиболее распространенной причиной проблем в этих случаях является преобразование текста из одной схемы кодирования в другую , что может привести к потере данных.
Давайте быстро рассмотрим несколько мест, где мы можем столкнуться с проблемами при кодировании или декодировании текста.
7.1. Текстовые Редакторы
В большинстве случаев текстовый редактор-это место, откуда исходят тексты. Существует множество текстовых редакторов в популярном выборе, включая vi, Блокнот и MS Word. Большинство из этих текстовых редакторов позволяют нам выбрать схему кодирования. Следовательно, мы всегда должны быть уверены, что они подходят для текста, с которым мы работаем.
7.2. Файловая система
После того, как мы создадим тексты в редакторе, нам нужно сохранить их в какой-то файловой системе. Файловая система зависит от операционной системы, на которой она работает. Большинство операционных систем имеют встроенную поддержку нескольких схем кодирования. Однако все еще могут быть случаи, когда преобразование кодировки приводит к потере данных.
7.3. Сеть
Тексты, передаваемые по сети с использованием протокола, такого как протокол передачи файлов (FTP), также включают преобразование между кодировками символов. Для всего, что закодировано в Юникоде, безопаснее всего передавать в двоичном виде, чтобы свести к минимуму риск потери при преобразовании. Однако передача текста по сети является одной из менее частых причин повреждения данных.
7.4. Базы данных
Большинство популярных баз данных, таких как Oracle и MySQL, поддерживают выбор схемы кодирования символов при установке или создании баз данных. Мы должны выбрать это в соответствии с текстами, которые мы ожидаем сохранить в базе данных. Это одно из наиболее частых мест, где повреждение текстовых данных происходит из-за преобразования кодировки.
7.5. Браузеры
Наконец, в большинстве веб-приложений мы создаем тексты и пропускаем их через различные слои с намерением просмотреть их в пользовательском интерфейсе, например в браузере
Здесь также важно, чтобы мы выбрали правильную кодировку символов, которая может правильно отображать символы. Большинство популярных браузеров, таких как Chrome, Edge, позволяют выбирать кодировку символов в своих настройках
UTF-8 против UTF-16
Как я уже упоминал, UTF-8 – не единственный метод кодирования символов Unicode – существует также UTF-16. Эти методы различаются количеством байтов, необходимых для хранения символа. UTF-8 кодирует символ в двоичную строку из одного, двух, трех или четырех байтов. UTF-16 кодирует символ Unicode в строку из двух или четырех байтов.
Это различие видно из их названий. В UTF-8 наименьшее двоичное представление символа составляет один байт или восемь битов. В UTF-16 наименьшее двоичное представление символа составляет два байта или шестнадцать бит.
И UTF-8, и UTF-16 могут переводить символы Unicode в двоичные файлы, удобные для компьютера, и обратно. Однако они несовместимы друг с другом. Эти системы используют разные алгоритмы для сопоставления кодовых точек с двоичными строками, поэтому двоичный вывод для любого заданного символа будет отличаться от обоих методов:
| символ | Двоичная кодировка UTF-8 | Двоичная кодировка UTF-16 |
| А | 01000001 | 01000001 11011000 00001110 11011111 |
| 𠜎 | 11110000 10100000 10011100 10001110 | 01000001 11011000 00001110 11011111 |
Кодировка UTF-8 предпочтительнее UTF-16 на большинстве веб-сайтов, потому что она использует меньше памяти. Напомним, что UTF-8 кодирует каждый символ ASCII всего одним байтом. UTF-16 должен кодировать эти же символы в двух или четырех байтах. Это означает, что текстовый файл на английском языке с кодировкой UTF-16 будет как минимум вдвое больше размера того же файла с кодировкой UTF-8.
UTF-16 более эффективен, чем UTF-8, только на некоторых неанглоязычных сайтах. Если веб-сайт использует язык с символами, находящимися дальше в библиотеке Unicode, UTF-8 будет кодировать все символы как четыре байта, тогда как UTF-16 может кодировать многие из тех же символов только как два байта. Тем не менее, если ваши страницы заполнены буквами ABC и 123, придерживайтесь UTF-8.
Что писать в теге meta description?
О том, как правильно составить description, на что заострить внимание, подробно разъясняют поисковые системы Яндекс и Google. Мы постарались обобщить доступную официальную информацию в следующий свод рекомендаций, которые помогут составить оптимальное мета-описание для вашего сайта
Как правильно заполнить meta description:
Уникальность. Для каждой страницы вашего сайта должен быть прописан уникальный по своему содержанию description. В противном случае поисковые системы при достаточной степени схожести контента на страницах, могут посчитать их за дубликаты. И оставить в поисковой выдаче только одну страницу;
Точность. Мета-описание должно точно характеризовать конкретный контент, расположенный на одной странице. Не нужно добавлять описание всего проекта целиком в каждом мета-теге;
Релевантность. Meta description должен соответствовать той информации, которая находится на странице
Не стоит стараться привлечь внимание пользователей, использую в своих мета-описаниях заголовки из желтой прессы;
Размер. Description не должен быть сильно коротким, он не должен состоять из нескольких слов или словосочетаний
Делайте мета-описания размером не менее 100 символов;
Читабельность. Помните, что ваш сниппет будут читать люди, поэтому описание в нем должно быть емким, но в то же время простым и понятным. Не нужно стараться добавить в meta description как можно больше ключевых слов, поисковые системы с большой вероятностью проигнорируют такое описание. Используйте тематически схожие слова и слова-синонимы, чтобы избежать тавтологий;
Ключевые фразы. Ключевые слова не просто могут, они должны присутствовать в мета-описании каждой страницы. 1-3 ключевых слова в description — хорошая практика. Основное ключевое слово старайтесь разместить в первом предложении.
Обобщение. Мета-описание должно обобщать всю самую ценную информацию на странице. Систематизируйте информацию, разбросанную по странице. Например, для карточки товара это может быть краткое описание товара, цена, производитель, состав, доступные характеристики. Для информационной статьи: основная тема, автор, дата публикации;
Формат. Description должен быть написан на том же языке, что и web-страница. Не стоит злоупотреблять заглавными буквами, спецсимволами, вызывающими лозунгами, знаками препинания.
Актуальность. Мета-описание должно соответствовать актуальной информации на странице. Если вы редактируете содержание странице, поддерживайте в актуальном состоянии и description.
Description — это ваша визитная карточка. При его составлении постарайтесь понять, почему пользователя должен заинтересовать именно ваш контент. Ответив себе, дайте ответ и пользователям.
Есть ли различия в составлении meta description для разных поисковых систем: Яндекс и Google? Давайте попробуем найти отличия в сниппетах и рекомендациях по составлению мета-описаний.
What is meta charset?
A charset or character set in full is essentially a set of characters recognized by the computer the same way the calculator can identify numbers. Each of these characters is represented by a number known as code point and this creates a communication channel for encoding and decoding content.
A character set, therefore, contains characters that serve a specific or particular purpose. The computer stores the characters as one or more bytes. An example is the ASCII character set which represents all English characters and special control characters with numbers from 0-127.
However, most character sets only work for specific languages and recognize limited characters and this makes the coding and encoding difficult or impossible. In modern times, however, the Unicode is the most reliable and universally accepted character set due to its ability to translate codes and numbers easily.
You can see the meta charset in the header of your html code
description (краткое описание)
Значение description используется для краткого описания содержимого, расположенного на текущей странице. Рекомендуемая максимальная длина такого описания не должна превышать 180 символов:
<meta name="description" content="Описание содержимого на данной странице">
Краткое описание страницы может быть использовано поисковыми система на странице с результатами поиска под названием страницы и URL-адреса:

Также краткое описание используется на сайтах некоторых соцсетей, при добавлении ссылки:

При составлении краткого описания следует учитывать следующие моменты:
- в описании нужно указывать именно ту информацию, которая отражает содержимое, опубликованное на данной странице;
- описание должно быть уникальным и не должно повторяться для разных страниц;
- старайтесь в описание страницы также включать необходимые ключевые слова, которые будут учитываться в поисковых запросах.
Примечание: краткое описание, расположенное под ссылкой на странице с результатами поиска, называется сниппетом.
HTML Tags
<!—><!DOCTYPE><a><abbr><acronym><address><applet><area><article><aside><audio><b><base><basefont><bdi><bdo><big><blockquote><body><br><button><canvas><caption><center><cite><code><col><colgroup><data><datalist><dd><del><details><dfn><dialog><dir><div><dl><dt><em><embed><fieldset><figcaption><figure><font><footer><form><frame><frameset><h1> — <h6><head><header><hr><html><i><iframe><img><input><ins><kbd><label><legend><li><link><main><map><mark><meta><meter><nav><noframes><noscript><object><ol><optgroup><option><output><p><param><picture><pre><progress><q><rp><rt><ruby><s><samp><script><section><select><small><source><span><strike><strong><style><sub><summary><sup><svg><table><tbody><td><template><textarea><tfoot><th><thead><time><title><tr><track><tt><u><ul><var><video>
Разрешенные кодировки
WHATWG Encoding Standard, на который ссылается последними стандарты HTML (текущий WHATWG HTML Living Standard, а также ранее конкурирующий W3C HTML 5.0 и 5.1) определяет список кодировок , которые должны поддерживать браузеры. Стандарты HTML запрещают поддержку других кодировок. Стандарт кодирования также предусматривает, что новые форматы, новые протоколы (даже когда используются существующие форматы) и авторы новых документов должны использовать исключительно UTF-8 .
Помимо UTF-8, следующие кодировки явно перечислены в самом стандарте HTML со ссылкой на стандарт кодирования:
- ISO-8859-2
- ISO-8859-7
- ISO-8859-8
- Окна-874
- Окна-1250
- Окна-1251
- Окна-1252
- Окна-1254
- Окна-1255
- Окна-1256
- Окна-1257
- Окна-1258
- GB18030
- Big5
- Shift JIS
- ISO-2022-JP
- EUC-KR
- UTF-16BE
- UTF-16LE
- x-определяемый пользователем
Следующие дополнительные кодировки перечислены в Стандарте кодирования, и поэтому также требуется их поддержка:
- Кодовая страница 866
- ISO-8859-3
- ISO-8859-4
- ISO-8859-5
- ISO-8859-6
- ISO-8859-8- I
- ISO-8859-10
- ISO-8859-13
- ISO-8859-14
- ISO-8859-15
- ISO-8859-16
- КОИ8-Р
- КОИ8-У / КОИ8-РУ
- Mac OS Роман
- Окна-1253
- Mac OS кириллица
- ГБК
- EUC-JP
Следующие кодировки указаны как явные примеры запрещенных кодировок:
- ЦЭСУ-8
- UTF-7
- BOCU-1
- ГКГУ
- EBCDIC
- UTF-32
Стандарт также определяет «замещающий» декодер, который отображает весь контент, помеченный как определенные кодировки, на заменяющий символ ( ), вообще отказываясь его обрабатывать. Это предназначено для предотвращения атак (например, межсайтовых сценариев ), которые могут использовать разницу между клиентом и сервером в поддерживаемых кодировках, чтобы замаскировать вредоносный контент. Хотя та же проблема безопасности относится к ISO-2022-JP и UTF-16 , которые также позволяют по-разному интерпретировать последовательности байтов ASCII, этот подход не рассматривался для них как выполнимый, поскольку они сравнительно чаще используются в развернутом контенте. Так обрабатываются следующие кодировки:
- ISO-2022-KR
- ISO-2022-CN
- ISO-2022-CN-EXT
- HZ-GB-2312
Важность кодирования символов
Нам часто приходится иметь дело с текстами, принадлежащими к нескольким языкам с различными письменными знаками, такими как латинский или арабский. Каждый символ в каждом языке должен быть каким-то образом сопоставлен с набором единиц и нулей. Действительно, удивительно, что компьютеры могут правильно обрабатывать все наши языки.
Чтобы сделать это правильно, нам нужно подумать о кодировке символов. Невыполнение этого требования часто может привести к потере данных и даже уязвимостям безопасности.
Чтобы лучше понять это, давайте определим метод декодирования текста на Java:
String decodeText(String input, String encoding) throws IOException {
return
new BufferedReader(
new InputStreamReader(
new ByteArrayInputStream(input.getBytes()),
Charset.forName(encoding)))
.readLine();
}
Обратите внимание, что вводимый здесь текст использует кодировку платформы по умолчанию. Если мы запустим этот метод с input как “Шаблон фасада-это шаблоны проектирования программного обеспечения.” и кодировка как “US-ASCII” , он выведет:
Если мы запустим этот метод с input как “Шаблон фасада-это шаблоны проектирования программного обеспечения.” и кодировка как “US-ASCII” , он выведет:
The fa��ade pattern is a software design pattern.
Ну, не совсем то, что мы ожидали.
Что могло пойти не так? Мы постараемся понять и исправить это в оставшейся части этого урока.
Ссылки на символы
Помимо собственных кодировок символов, символы также могут быть закодированы как ссылки на символы , которые могут быть ссылками на числовые символы ( десятичные или шестнадцатеричные ) или ссылками на символьные сущности . Ссылки на символьные сущности также иногда называют именованными сущностями или сущностями HTML для HTML. Использование символьных ссылок в HTML происходит от SGML .
Ссылки на символы HTML
Цифровая ссылка на символ в HTML относится к символу его универсальный набор символов / Unicode точки коды , и использует формат
или
где nnnn — это кодовая точка в десятичной форме, а hhhh — это кодовая точка в шестнадцатеричной форме. В XML-документах x должен быть в нижнем регистре. Нннн или хххх может быть любое количество цифр и может включать в себя ведущие нули. В hhhh могут смешиваться прописные и строчные буквы, хотя прописные буквы являются обычным стилем.
Не все веб-браузеры или почтовые клиенты, используемые получателями документов HTML, или текстовые редакторы, используемые авторами документов HTML, смогут отображать все символы HTML. Большинство современного программного обеспечения способно отображать большинство или все символы языка пользователя и рисовать прямоугольник или другой четкий индикатор для символов, которые они не могут отобразить.
Для кодов от 0 до 127, исходного 7-битного стандартного набора ASCII , большинство этих символов можно использовать без ссылки на символ. Все коды от 160 до 255 могут быть созданы с использованием символьных имен сущностей . Только несколько кодов с более высокими номерами могут быть созданы с использованием имен сущностей, но все они могут быть созданы с помощью ссылки на символ десятичного числа.
Ссылки на символьные сущности также могут иметь формат, в котором имя является чувствительной к регистру буквенно-цифровой строкой. Например, «λ» можно также закодировать, как в документе HTML. Упоминания характер сущности , , и предопределены в HTML и SGML, потому что , , и уже используются для разделения разметки. В частности, это не включало сущность XML (‘) до HTML5 . Список всех названных ссылок на символьные сущности HTML вместе с версиями, в которых они были представлены, см. В разделе Список ссылок на символьные сущности XML и HTML .
Ненужное использование ссылок на символы HTML может значительно снизить удобочитаемость HTML. Если кодировка символов для веб — страницы выбрана правильно, то ссылки HTML характер, как правило , требуется только для разметки символов разделителей , как упоминалось выше, и в течение нескольких специальных символов (или вообще если родной Unicode не кодирующая как UTF-8 используется ). Неправильное экранирование HTML-объекта может также открыть уязвимости безопасности для атак с использованием инъекций, таких как межсайтовый скриптинг . Если атрибуты HTML не заключены в кавычки, определенные символы, в первую очередь пробелы , такие как пробел и табуляция, должны быть экранированы с помощью сущностей. В других языках, связанных с HTML, есть свои методы экранирования символов.
Ссылки на символы XML
В отличие от традиционного HTML с его большим диапазоном ссылок на символьные сущности, в XML есть только пять предопределенных символьных ссылок на сущности. Они используются для экранирования символов, чувствительных к разметке в определенных контекстах:
- → & ( амперсанд , U + 0026)
- → <(знак «меньше», U + 003C)
- →> (знак больше, U + 003E)
- → «(кавычка, U + 0022)
- → ‘(апостроф, U + 0027)
Все остальные ссылки на символьные сущности должны быть определены до того, как их можно будет использовать. Например, использование (что дает é, латинскую строчную букву E с острым ударением, U + 00E9 в Unicode) в XML-документе приведет к ошибке, если объект еще не был определен. XML также требует, чтобы в шестнадцатеричных числовых ссылках использовались строчные буквы: например, а не . XHTML , являющийся XML-приложением, поддерживает набор сущностей HTML вместе с предопределенными сущностями XML.
UTF-8 Basic Latin
| Char | Dec | Hex | Entity | Name |
|---|---|---|---|---|
| 32 | 0020 | SPACE | ||
| ! | 33 | 0021 | EXCLAMATION MARK | |
| « | 34 | 0022 | " | QUOTATION MARK |
| # | 35 | 0023 | NUMBER SIGN | |
| $ | 36 | 0024 | DOLLAR SIGN | |
| % | 37 | 0025 | PERCENT SIGN | |
| & | 38 | 0026 | & | AMPERSAND |
| ‘ | 39 | 0027 | APOSTROPHE | |
| ( | 40 | 0028 | LEFT PARENTHESIS | |
| ) | 41 | 0029 | RIGHT PARENTHESIS | |
| * | 42 | 002A | ASTERISK | |
| + | 43 | 002B | PLUS SIGN | |
| , | 44 | 002C | COMMA | |
| — | 45 | 002D | HYPHEN-MINUS | |
| . | 46 | 002E | FULL STOP | |
| 47 | 002F | SOLIDUS | ||
| 48 | 0030 | DIGIT ZERO | ||
| 1 | 49 | 0031 | DIGIT ONE | |
| 2 | 50 | 0032 | DIGIT TWO | |
| 3 | 51 | 0033 | DIGIT THREE | |
| 4 | 52 | 0034 | DIGIT FOUR | |
| 5 | 53 | 0035 | DIGIT FIVE | |
| 6 | 54 | 0036 | DIGIT SIX | |
| 7 | 55 | 0037 | DIGIT SEVEN | |
| 8 | 56 | 0038 | DIGIT EIGHT | |
| 9 | 57 | 0039 | DIGIT NINE | |
| 58 | 003A | COLON | ||
| ; | 59 | 003B | SEMICOLON | |
| < | 60 | 003C | < | LESS-THAN SIGN |
| = | 61 | 003D | EQUALS SIGN | |
| > | 62 | 003E | > | GREATER-THAN SIGN |
| ? | 63 | 003F | QUESTION MARK | |
| @ | 64 | 0040 | COMMERCIAL AT | |
| A | 65 | 0041 | LATIN CAPITAL LETTER A | |
| B | 66 | 0042 | LATIN CAPITAL LETTER B | |
| C | 67 | 0043 | LATIN CAPITAL LETTER C | |
| D | 68 | 0044 | LATIN CAPITAL LETTER D | |
| E | 69 | 0045 | LATIN CAPITAL LETTER E | |
| F | 70 | 0046 | LATIN CAPITAL LETTER F | |
| G | 71 | 0047 | LATIN CAPITAL LETTER G | |
| H | 72 | 0048 | LATIN CAPITAL LETTER H | |
| I | 73 | 0049 | LATIN CAPITAL LETTER I | |
| J | 74 | 004A | LATIN CAPITAL LETTER J | |
| K | 75 | 004B | LATIN CAPITAL LETTER K | |
| L | 76 | 004C | LATIN CAPITAL LETTER L | |
| M | 77 | 004D | LATIN CAPITAL LETTER M | |
| N | 78 | 004E | LATIN CAPITAL LETTER N | |
| O | 79 | 004F | LATIN CAPITAL LETTER O | |
| P | 80 | 0050 | LATIN CAPITAL LETTER P | |
| Q | 81 | 0051 | LATIN CAPITAL LETTER Q | |
| R | 82 | 0052 | LATIN CAPITAL LETTER R | |
| S | 83 | 0053 | LATIN CAPITAL LETTER S | |
| T | 84 | 0054 | LATIN CAPITAL LETTER T | |
| U | 85 | 0055 | LATIN CAPITAL LETTER U | |
| V | 86 | 0056 | LATIN CAPITAL LETTER V | |
| W | 87 | 0057 | LATIN CAPITAL LETTER W | |
| X | 88 | 0058 | LATIN CAPITAL LETTER X | |
| Y | 89 | 0059 | LATIN CAPITAL LETTER Y | |
| Z | 90 | 005A | LATIN CAPITAL LETTER Z | |
| 91 | 005B | LEFT SQUARE BRACKET | ||
| \ | 92 | 005C | REVERSE SOLIDUS | |
| 93 | 005D | RIGHT SQUARE BRACKET | ||
| ^ | 94 | 005E | CIRCUMFLEX ACCENT | |
| _ | 95 | 005F | LOW LINE | |
| ` | 96 | 0060 | GRAVE ACCENT | |
| a | 97 | 0061 | LATIN SMALL LETTER A | |
| b | 98 | 0062 | LATIN SMALL LETTER B | |
| c | 99 | 0063 | LATIN SMALL LETTER C | |
| d | 100 | 0064 | LATIN SMALL LETTER D | |
| e | 101 | 0065 | LATIN SMALL LETTER E | |
| f | 102 | 0066 | LATIN SMALL LETTER F | |
| g | 103 | 0067 | LATIN SMALL LETTER G | |
| h | 104 | 0068 | LATIN SMALL LETTER H | |
| i | 105 | 0069 | LATIN SMALL LETTER I | |
| j | 106 | 006A | LATIN SMALL LETTER J | |
| k | 107 | 006B | LATIN SMALL LETTER K | |
| l | 108 | 006C | LATIN SMALL LETTER L | |
| m | 109 | 006D | LATIN SMALL LETTER M | |
| n | 110 | 006E | LATIN SMALL LETTER N | |
| o | 111 | 006F | LATIN SMALL LETTER O | |
| p | 112 | 0070 | LATIN SMALL LETTER P | |
| q | 113 | 0071 | LATIN SMALL LETTER Q | |
| r | 114 | 0072 | LATIN SMALL LETTER R | |
| s | 115 | 0073 | LATIN SMALL LETTER S | |
| t | 116 | 0074 | LATIN SMALL LETTER T | |
| u | 117 | 0075 | LATIN SMALL LETTER U | |
| v | 118 | 0076 | LATIN SMALL LETTER V | |
| w | 119 | 0077 | LATIN SMALL LETTER W | |
| x | 120 | 0078 | LATIN SMALL LETTER X | |
| y | 121 | 0079 | LATIN SMALL LETTER Y | |
| z | 122 | 007A | LATIN SMALL LETTER Z | |
| { | 123 | 007B | LEFT CURLY BRACKET | |
| | | 124 | 007C | VERTICAL LINE | |
| } | 125 | 007D | RIGHT CURLY BRACKET | |
| ~ | 126 | 007E | TILDE |
Автоматический переход на другую страницу
Пример:
<meta http-equiv=»Refresh» content=»10; URL=http://www.mysite/index.html»>
Если вдруг по каким либо причинам Вы задумаете поменять URL адрес Вашего сайта то хорошо было бы на старом месте оставить страницу вроде этой:
<html><head><meta http-equiv=»Content-Type» Content=»text/html; Charset=utf-8″><meta http-equiv=»Refresh» content=»10; URL=http://www.mysite/index.html»><title>Переадресация</title></head><body><font size=»+1″>Адрес сайта был изменен, через 10 секунд Ваш браузер будет автоматически перенаправлен по новому адресу:<br><a href=»http://www.mysite.ru/index.html»><b>http://www.mysite.ru/</b></a><br>Нажмите <a href=»http://www.mysite.ru/index.html»>здесь</a> для того чтобы выполнить переход немедленно.<br>Приносим извинения за доставленные неудобства.</font></body></html>
смотреть пример
Разберём и осмыслим строчку из примера:
<meta http-equiv=»Refresh» content=»10; URL=http://www.mysite/index.html»>meta http-equiv=»Refresh»content=»10;URL=http://www.mysite/index.html»
Пример:
<meta http-equiv=»Refresh» content=»30″>
А вот если в заголовке Refresh URL адрес упустить, как показано в примере, то тогда браузер будет постоянно через каждые 30 секунд (ну или не 30.. сколько пропишите через столько и будет..) обновлять содержимое данной страницы.
Такой метод широко используется в новостных лентах, где информация идет так сказать потоком и требует постоянного обновления.
Первый способ: Скопировал в Таблице — Вставил там, где нужно.
Мы копируем (не скачиваем, а именно копируем) символ в Таблице символов для того, чтобы временно поместить его в память компьютера (или аналогичного устройства). Такая временная память называется буфер обмена.
Такой буфер нужен для того, чтобы временно туда поместить символ, а потом вставить его из буфера туда, где мы хотим видеть этот символ. Таким образом, символ не скачивается на диск компьютера, а временно помещается в оперативную память компьютера, то есть, в буфер обмена. А из этого буфера пользователь может вставить символ туда, где потребуется.
Разберем на конкретном примере, как можно символ из Таблицы закинуть в буфер обмена, а потом достать его оттуда и разместить туда, где это необходимо.
Чтобы скопировать символ в память компьютера, нам надо его выделить . Для этого достаточно кликнуть по необходимому символу (цифра 1 на рис. 2).
Затем щелкаем по кнопке «Выбрать» (2 на рис. 2):
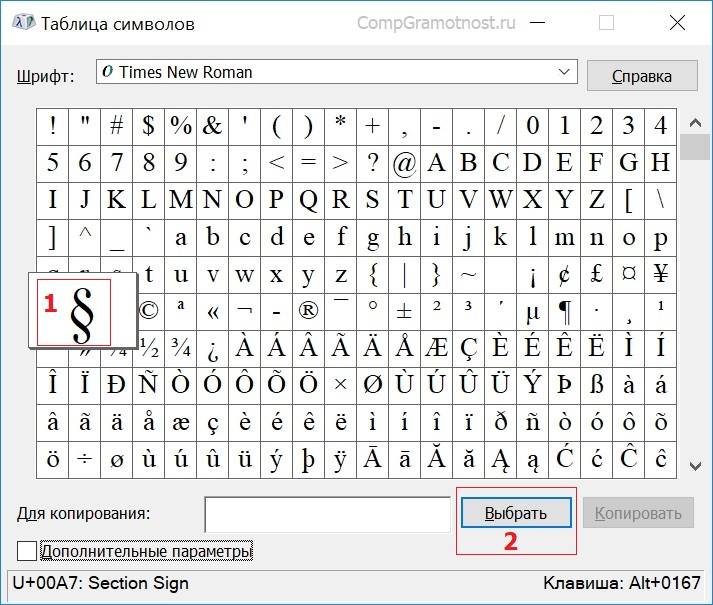
Рис. 2. Кликнуть по необходимому символу и нажать на кнопку “Выбрать”
В итоге символ попадет в строку “Для копирования” (1 на рис. 3). Для того, чтобы символ оказался в буфере обмена, надо кликнуть по кнопке «Копировать» (2 на рис. 3):
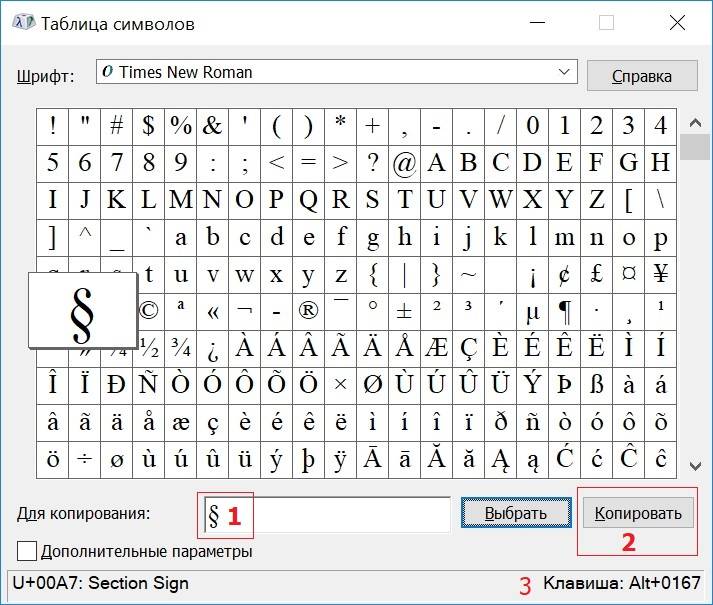
Рис. 3. Копируем символ из Таблицы в буфер обмена
Есть и быстрый вариант:
После этого остается перейти в соответствующее приложение (или в текстовый редактор) и вставить скопированный символ из буфера обмена.
Для этого надо поставить в приложении (в Блокноте, текстовом редакторе и т.п.) курсор в нужное место и нажать на две клавиши Ctrl+V (они выполняют команду “Вставить”).
Если не получается с клавишами Ctrl+V, тогда кликаем правой кнопкой мыши там, где должен быть помещен символ. Откроется меню, в котором щелкаем команду “Вставить”. После этого появится скопированный символ.
Заметим, что можно в Таблице символов в строку “Для копирования” поместить сразу несколько символов и одновременно все их скопировать. Тогда произойдет вставка сразу всех скопированных символов туда, где это требуется (в Блокнот, в какое-то приложение и т.п.)
Второй способ: копируем символ с помощью сочетания клавиш
Для каждого символа в Таблице имеется строго свое сочетание клавиш.
Справа в таблице символов Windows (3 на рис. 3) Вы можете увидеть, какую комбинацию клавиш нужно нажать, чтобы вставить выбранный символ в нужном Вам приложении.
Например, для знака параграфа § следует нажать сочетание клавиш Alt+0167, при этом можно использовать только цифры с малой цифровой клавиатуры.
Более подробно о том, как на практике проверить кодировку символов, используя малую цифровую клавиатуру, можно узнать ЗДЕСЬ. Такой способ ввода символов, которых нет на клавиатуре, требует определенных навыков и, думаю, что редко используется обычными пользователями.
Упражнение по компьютерной грамотности:
1) Откройте Таблицу символов Windows. Выберите шрифт, которым Вы чаще всего пользуетесь. Найдите два-три символа, которых нет на клавиатуре, выделите и скопируйте их в буфер обмена.
2) Откройте текстовый редактор (например, Блокнот) и вставьте из буфера обмена скопированные туда ранее символы.
Видео “Таблица символов Windows”
Также по теме:
1. Три способа задания параметров шрифта
2. Какие шрифты есть на моем компьютере?
3. Два шрифта без букв
4. Сравнение возможностей Word и Excel для работы с таблицами
Распечатать статью
Получайте актуальные статьи по компьютерной грамотности прямо на ваш почтовый ящик. Уже более 3.000 подписчиков
Важно: необходимо подтвердить свою подписку! В своей почте откройте письмо для активации и кликните по указанной там ссылке. Если письма нет, проверьте папку Спам
3 февраля 2011
Классическое приложение таблица символов используется для поиска и вставки символов, отсутствующих на клавиатуре в Windows 10. В большинстве случаев в необходимые символы имеют комбинации определённых клавиш, которые способны их быстро вызвать. Таким способом при необходимости можно поставить отсутствующие символы на клавиатуре.
Эта статья расскажет, как открыть таблицу символов в Windows 10. Она присутствует в операционной системе начиная ещё с первых версий. В сравнении с предыдущими версиями можно найти некоторые некритические изменения. В принципе процесс работы с таблицей символов не изменился даже после большого количества обновлений системы.
Как установить UTF-8 кодировку в PHP
В PHP скрипте для установки кодировки используется header, например:
header('Content-Type: charset=utf-8');
Обычно вместе с кодировкой также указывают тип содержимого (в примере вариант для HTML страницы):
header('Content-Type: text/html; charset=utf-8');
Ещё один вариант для RSS ленты:
header('Content-type: text/xml; charset=utf-8');
Помните, что функция header должна быть вызвана перед любым выводом в браузер. В противном случае (если вывод в браузер уже был сделан), то уже были отправлены и заголовки. Очевидно, что в этом случае их уже невозможно поменять. Если в браузер было выведено сообщение об ошибке, то заголовки также уже были отправлены и использование header вызовет ошибку. Для проверки, были ли уже отправлены заголовки, используйте headers_sent.
Описанный способ работает только когда PHP скрипт полностью генерирует содержимое страницы. Статические страницы (такие как html) вы должны сохранять в кодировке utf-8
Большинство веб серверов обратят внимание на кодировку файла и добавят соответствующий заголовок. На самом деле, сохранение PHP файла в кодировке utf-8 приведёт к такому же результату.
