Справочник
Содержание:
- Полезные строковые операции
- Кодировки
- Синтаксис регулярных выражений
- Python F-Строки: Детали
- Строковые операторы
- Узнайте, какие встроенные методы Python используются в строковых последовательностях
- Ljust (): как оставить – обосновать строку в Python
- Мир регулярных выражений
- Методы join(), split() и replace()
- Методы для работы со строками
- Вводная информация о строках
- Основы строки Python
- Методы строк
Полезные строковые операции
- f-string в Python – новый и лучший способ форматирования строки, представленный в Python 3.6.
- Подстрока в Python.
- Создать случайную строку.
- Строковый модуль в Python.
- Необработанная строка.
- Многострочная строка.
- Проверка равенства строк.
- Сравнение строк.
- Конкатенация строк.
- Нарезка строки.
- Перевернуть строку.
- Строка для datetime – strptime().
- Преобразовать String в int.
- Преобразовать строку в байты.
- Преобразовать String в float.
- Преобразовать список в строку.
- Класс шаблона строки.
- Проверить, является ли переменная String.
- Объединить строку и int.
- Удалить символ из строки.
- Как добавить строки.
- Найти строку в списке.
- Удалить пробелы из строки.
Кодировки
Другим любопытным моментом является то, что символы которые мы видим внутри строки на самом деле являются порядковыми номерами в таблице которая ставит в соответсвие этому номеру определенный сивол. Эти таблицы мы называем кодировками. Существует очень много кодировок, но возможно вы слышали названия некоторых из них: ASCII, Latin-1, КОИ-8, utf-8. По умолчанию, в Python используется стандарт «Юникод». И в том что каждому символу соответствует определенный код очень легко убедиться с помощью встроенных функций и :
Но к превеликому сожалению, это не только любопытно, но еще и очень печально. Представим себе, что наша программа должна обмениваться текстом с другой программой. Так как строки хранятся в виде байтов, то в нашу программу должна прилететь строка, которая может выглядеть, например, вот так . Что же с ней делать?:
Чтож, похоже что программа-отправитель использует какуюто другую кодировку. Допустим, мы смогли выяснить, что до того как эта строка стала набором байтов ее напечатали на русском языке. Русский язык поддерживают многие кодировки. Придется пробовать декодировать в каждую из них. Поехали…
Какя-то абракадабра. Пробуем следующую:
Как видите, байтовые строки не несут информации о своей кодировке, хотя в зависимости от происхождения, эта кодировка может быть какой угодно. Рассмотренная проблема встречается очень редко, но все же встречается. Многие научные программы до сих пор используют кодировку ascii по умолчанию, а некоторые операционные системы могут использовать какую-то другую кодировку. Вообще, кодировкой по умолчанию является кодировка операционной системы (можно узнать с помощью функции модуля sys). Так что, если вы создаете интернациональное приложение или сайт, или не знаете с какой операционкой придется работать вашей программе, то наверняка тоже встретитесь с этой проблемой. Повторюсь, проблема редкая, весьма специфичная и Python предоставляет относительно неплохие средства для ее преодоления.
Чтож, вот мы и познакомились со строками. Определение, которое мы дали в начале, могло показаться очень сложным и непонятным (я даже не совсем уверен в его правильности), но тем не менее, на деле, все оказалось довольно простым.
Синтаксис регулярных выражений
Каштан: P ** (YIYTIYTHIYTHO)? ** N, регулярные выражения состоят из операторов и операторов, выделенные жирным шрифтом являются операторами
Часто используемые операторы в регулярных выражениях
| оператор | Описание | Пример |
|---|---|---|
| . | Представляет любой одиночный символ | |
| Набор символов, дающий диапазон значений для одного символа | означает a, b, c, означает один символ от a до z, , означает W, K | |
| Не символьный набор, предоставляющий диапазон исключения для одного символа | обозначает единственный символ, отличный от a, b или c | |
| * | Расширить предыдущий символ 0 раз или неограниченное количество раз | abc *, что означает ab, abc, abcc, abcc и т. д. |
| + | Продлить предыдущий символ 1 раз или неограниченное количество раз | abc +, что означает abc, abcc, abccc и т. д. |
| ? | 0 или 1 расширение предыдущего символа | abc? означает ab, abc |
| | | Любое из левого и правого выражений | abc | def означает abc, def |
| {m} | Расширить предыдущий символ m раз | ab {2} c означает abbc |
| {m,n} | Продлить предыдущий символ с m до n раз (включая n) | ab {1,2} c означает abc, abbc |
| ^ | Соответствует началу строки | ^ abc означает abc и находится в начале строки |
| $ | Совпадение конца строки | abc $ означает abc и находится в конце строки |
| ( ) | Отметка группировки, только оператор | может использоваться внутри | (Abc) означает abc, (abc | def) означает abc, def |
| \d | Число, эквивалентное | |
| \w | Символ слова, эквивалентный |
Например:
| Регулярное выражение | Соответствующая строка |
|---|---|
| P(Y|YT|YTH|YTHO)?N | PN,PYN,PYTN,PYTHN,PYTHON |
| PYTHON+ | PYTHON,PYTHONN,PYTHONNN… |
| PYON | PYTON,PYHON |
| PY?ON | PYON, PYAaN, PYbON, PYcON … (без T / H) |
| PY{0:3}N | PN, PYN, PYYN, PYYYN |
Некоторые классические регулярные выражения
| ^+$ | Строка из 26 букв |
|---|---|
| ^+$ | Строка из 26 букв и цифр |
| ^-?\d+$ | Строка в целочисленной форме (может иметь отрицательные числа) |
| ^**$ | Строка в форме положительного целого числа ** (Если элемент в [] не имеет согласованного числа раз, он может повторяться неограниченное количество раз по умолчанию) ** |
| \d{5} | Почтовый индекс в Китае |
| Соответствие китайских иероглифов (использование utf-8 для согласования диапазона значений китайских иероглифов) | |
| \d{3}-\d{8}|\d{4}-\d{7} | Внутренний номер телефона 010-68913536 или 010-6891-3536 |
Регулярное выражение, соответствующее IP-адресу
IP-адрес состоит из 4 сегментов, каждый сегмент — от 0 до 255, разделенных знаком «.», Например 210.134.3.123.
первый шаг:, Независимо от длины
Второй шаг:Учитывайте длину
Шаг 3: Сегментация
0-99:
100-199:
200-249:
250-255:
сочетание:
Python F-Строки: Детали
На данный момент мы узнали почему f-строки так хороши, так что вам уже может быть интересно их попробовать в работе. Рассмотрим несколько деталей, которые нужно учитывать:
Кавычки
Вы можете использовать несколько типов кавычек внутри выражений. Убедитесь в том, что вы не используете один и тот же тип кавычек внутри и снаружи f-строки.
Этот код будет работать:
Python
print(f»{‘Eric Idle’}»)
# Вывод: ‘Eric Idle’
|
1 2 |
print(f»{‘Eric Idle’}») # Вывод: ‘Eric Idle’ |
И этот тоже:
Python
print(f'{«Eric Idle»}’)
# Вывод: ‘Eric Idle’
|
1 2 |
print(f'{«Eric Idle»}’) # Вывод: ‘Eric Idle’ |
Вы также можете использовать тройные кавычки:
Python
print(f»»»Eric Idle»»»)
# Вывод: ‘Eric Idle’
|
1 2 |
print(f»»»Eric Idle»»») # Вывод: ‘Eric Idle’ |
Python
print(f»’Eric Idle»’)
# Вывод: ‘Eric Idle’
|
1 2 |
print(f»’Eric Idle»’) # Вывод: ‘Eric Idle’ |
Если вам понадобиться использовать один и тот же тип кавычек внутри и снаружи строки, вам может помочь :
Python
print(f»The \»comedian\» is {name}, aged {age}.»)
# Вывод: ‘The «comedian» is Eric Idle, aged 74.’
|
1 2 |
print(f»The \»comedian\» is {name}, aged {age}.») # Вывод: ‘The «comedian» is Eric Idle, aged 74.’ |
Словари
Говоря о кавычках, будьте внимательны при работе со . Вы можете вставить значение словаря по его ключу, но сам ключ нужно вставлять в одиночные кавычки внутри f-строки. Сама же f-строка должна иметь двойные кавычки.
Вот так:
Python
comedian = {‘name’: ‘Eric Idle’, ‘age’: 74}
print(f»The comedian is {comedian}, aged {comedian}.»)
# Вывод: The comedian is Eric Idle, aged 74.
|
1 2 3 4 |
comedian={‘name»Eric Idle’,’age’74} print(f»The comedian is {comedian}, aged {comedian}.») # Вывод: The comedian is Eric Idle, aged 74. |
Обратите внимание на количество возможных проблем, если допустить ошибку в синтаксисе SyntaxError:
Python
>>> comedian = {‘name’: ‘Eric Idle’, ‘age’: 74}
>>> f’The comedian is {comedian}, aged {comedian}.’
File «<stdin>», line 1
f’The comedian is {comedian}, aged {comedian}.’
^
SyntaxError: invalid syntax
|
1 2 3 4 5 6 |
>>>comedian={‘name»Eric Idle’,’age’74} >>>f’The comedian is {comedian}, aged {comedian}.’ File»<stdin>»,line1 f’The comedian is {comedian}, aged {comedian}.’ ^ SyntaxErrorinvalid syntax |
Если вы используете одиночные кавычки в ключах словаря и снаружи f-строк, тогда кавычка в начале ключа словаря будет интерпретирован как конец строки.
Скобки
Чтобы скобки появились в вашей строке, вам нужно использовать двойные скобки:
Python
print(f»`74`»)
# Вывод: ‘{ 74 }’
|
1 2 3 |
print(f»`74`») |
Обратите внимание на то, что использование тройных скобок приведет к тому, что в строке будут только одинарные:
Python
print( f»{`74`}» )
# Вывод: ‘{ 74 }’
|
1 2 3 |
print(f»{`74`}») |
Однако, вы можете получить больше отображаемых скобок, если вы используете больше, чем три скобки:
Python
print(f»{{`74`}}»)
# Вывод: ‘`74`’
|
1 2 3 |
print(f»{{`74`}}») |
Бэкслеши
Как вы видели ранее, вы можете использовать бэкслеши в части строки f-string. Однако, вы не можете использовать бэкслеши в части выражения f-string:
Python
>>> f»{\»Eric Idle\»}»
File «<stdin>», line 1
f»{\»Eric Idle\»}»
^
SyntaxError: f-string expression part cannot include a backslash
|
1 2 3 4 5 |
>>>f»{\»Eric Idle\»}» File»<stdin>»,line1 f»{\»Eric Idle\»}» ^ SyntaxErrorf-stringexpression part cannot includeabackslash |
Вы можете проработать это, оценивая выражение заранее и используя результат в f-строк:
Python
name = «Eric Idle»
print(f»{name}»)
# Вывод: ‘Eric Idle’
|
1 2 3 4 |
name=»Eric Idle» print(f»{name}») |
Междустрочные комментарии
Выражения не должны включать комментарии с использованием символа #. В противном случае, у вас будет ошибка синтаксиса SyntaxError:
Python
>>> f»Eric is {2 * 37 #Oh my!}.»
File «<stdin>», line 1
f»Eric is {2 * 37 #Oh my!}.»
^
SyntaxError: f-string expression part cannot include ‘#’
|
1 2 3 4 5 |
>>>f»Eric is {2 * 37 #Oh my!}.» File»<stdin>»,line1 f»Eric is {2 * 37 #Oh my!}.» ^ SyntaxErrorf-stringexpression part cannot include’#’ |
Строковые операторы
| Оператор | Описание |
|---|---|
| + | Он известен как оператор конкатенации, используемый для соединения строк по обе стороны от оператора. |
| * | Известен как оператор повторения. Он объединяет несколько копий одной и той же строки. |
| [] | оператор среза. Он используется для доступа к подстрокам определенной строки. |
| оператор среза диапазона, используется для доступа к символам из указанного диапазона. | |
| in | Оператор членства. Он возвращается, если в указанной строке присутствует определенная подстрока. |
| not in | Также является оператором членства и выполняет функцию, обратную in. Он возвращает истину, если в указанной строке отсутствует конкретная подстрока. |
| r / R | Используется для указания необработанной строки. Необработанные строки применяются в тех случаях, когда нам нужно вывести фактическое значение escape-символов, таких как «C: // python». Чтобы определить любую строку как необработанную, за символом r или R следует строка. |
| % | Необходим для форматирования строк. Применяет спецификаторы формата, используемые в программировании на C, такие как %d или %f, для сопоставления их значений в python. Мы еще обсудим, как выполняется форматирование в Python. |
Рассмотрим следующий пример, чтобы понять реальное использование операторов Python.
str = "Hello"
str1 = " world"
print(str*3) # prints HelloHelloHello
print(str+str1)# prints Hello world
print(str) # prints o
print(str); # prints ll
print('w' in str) # prints false as w is not present in str
print('wo' not in str1) # prints false as wo is present in str1.
print(r'C://python37') # prints C://python37 as it is written
print("The string str : %s"%(str)) # prints The string str : Hello
Выход:
HelloHelloHello Hello world o ll False False C://python37 The string str : Hello
Узнайте, какие встроенные методы Python используются в строковых последовательностях
Строка — это последовательность символов. Встроенный строковый класс в Python представлен строками, использующими универсальный набор символов Unicode. Строки реализуют часто встречающуюся последовательность операций в Python наряду с некоторыми дополнительными методами, которые больше нигде не встречаются. На картинке ниже показаны все эти методы:
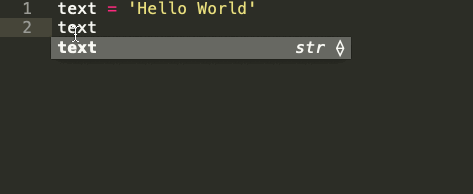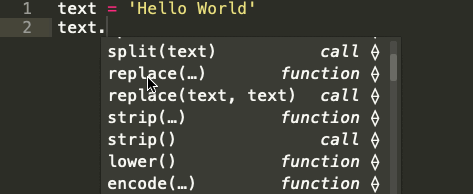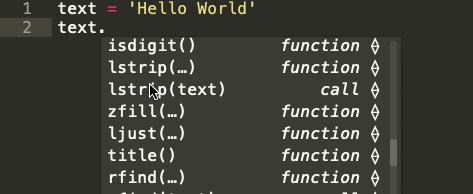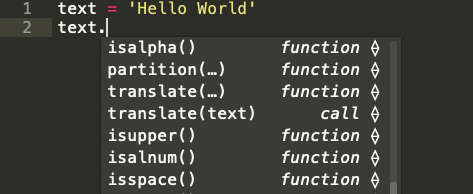 Встроенные строковые функции в Python
Встроенные строковые функции в Python
Давайте узнаем, какие используются чаще всего
Важно заметить, что все строковые методы всегда возвращают новые значения, не меняя исходную строку и не производя с ней никаких действий
Код для этой статьи можно взять из соответствующего репозитория Github Repository.
1. center( )
Метод выравнивает строку по центру. Выравнивание выполняется с помощью заданного символа (пробела по умолчанию).
Синтаксис
, где:
- length — это длина строки
- fillchar—это символ, задающий выравнивание
Пример

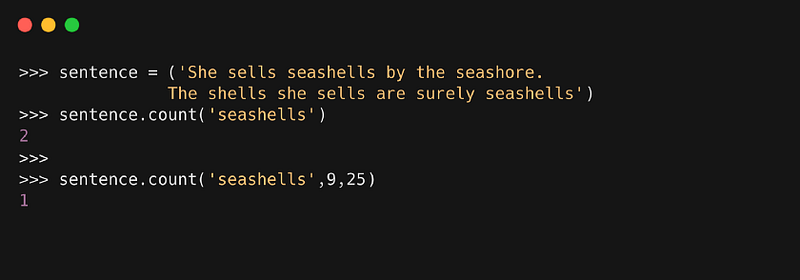
2. count( )
Метод возвращает счёт или число появлений в строке конкретного значения.
Синтаксис
, где:
- value — это подстрока, которая должна быть найдена в строке
- start — это начальное значение индекса в строке, где начинается поиск заданного значения
- end — это конечное значение индекса в строке, где завершается поиск заданного значения
Пример
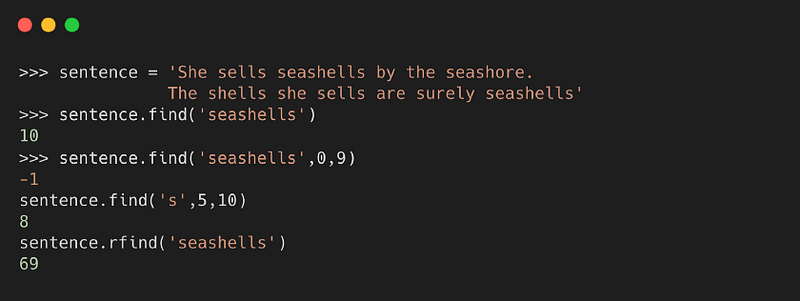
3. find( )
Метод возвращает наименьшее значение индекса конкретной подстроки в строке. Если подстрока не найдена, возвращается -1.
Синтаксис
, где:
- value или подстрока, которая должна быть найдена в строке
- start — это начальное значение индекса в строке, где начинается поиск заданного значения
- end — это конечное значение индекса в строке, где завершается поиск заданного значения
Пример
Метод возвращает копию строки, преобразуя все заглавные буквы в строчные, и наоборот.
Синтаксис
Пример

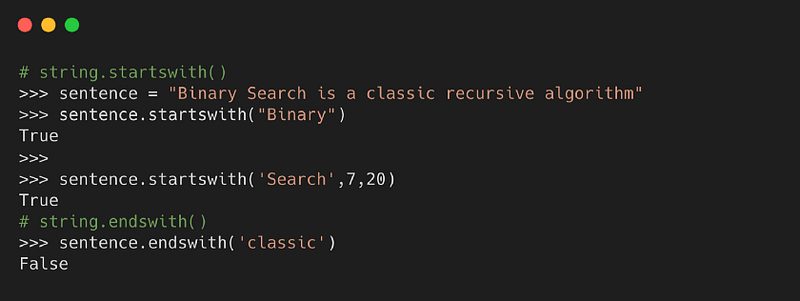
5. startswith( ) and endswith( )
Метод возвращает True, если строка начинается с заданного значения. В противном случае возвращает False.
С другой стороны, функция возвращает True, если строка заканчивается заданным значением. В противном случае возвращает False.
Синтаксис
- value — это искомая строка в строке
- start — это начальное значение индекса в строке, где начинается поиск заданного значения
- end — это конечное значение индекса в строке, где завершается поиск заданного значения
Пример
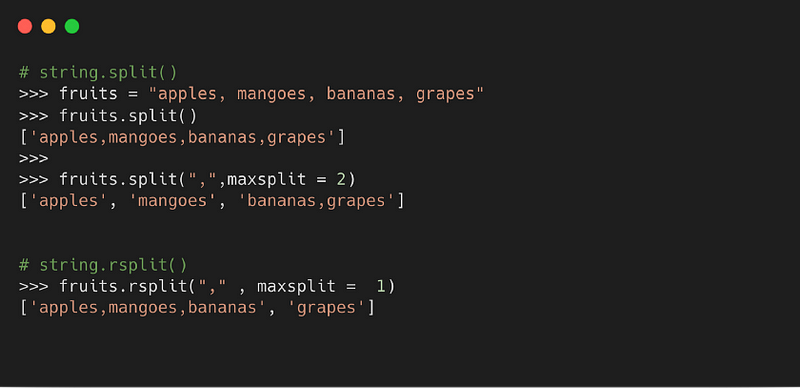
6. split( )
Метод возвращает список слов в строке, где разделителем по умолчанию является пробел.
Синтаксис
- sep: разделитель, используемый для разделения строки. Если не указано иное, разделителем по умолчанию является пробел
- maxsplit: обозначает количество разделений. Значение по умолчанию -1, что значит «все случаи»
Пример
7. Строка заглавными буквами
Синтаксис
Синтаксис
Синтаксис
Пример

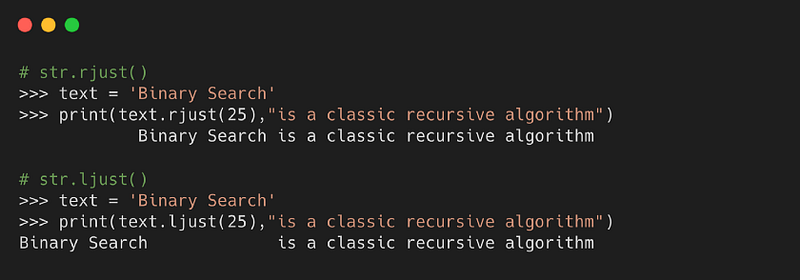
8. ljust( ) и rjust( )
С помощью заданного символа (по умолчанию пробел) метод возвращает вариант выбранной строки с левым выравниванием. Метод rjust() выравнивает строку вправо.
Синтаксис
- length: длина строки, которая должна быть возвращена
- character: символ для заполнения незанятого пространства, по умолчанию являющийся пробелом
Пример
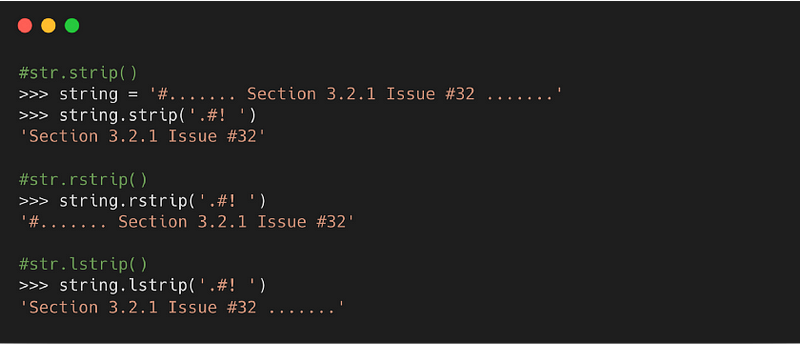
9. strip( )
Метод возвращает копию строки без первых и последних символов. Эти отсутствующие символы — по умолчанию пробелы.
Синтаксис
character: набор символов для удаления
- : удаляет символы с начала строки.
- : удаляет символы с конца строки.
10. zfill( )
Метод zfill() добавляет нули в начале строки. Длина возвращаемой строки зависит от заданной ширины.
Синтаксис
width: указывает длину возвращаемой строки. Нули не добавляются, если параметр ширины меньше длины первоначальной строки.
Пример

Заключение
В статье мы рассмотрели лишь некоторые встроенные строковые методы в Python. Есть и другие, не менее важные методы, с которыми при желании можно ознакомиться в соответствующей документации Python.
- PEG парсеры и Python
- Популярные лайфхаки для Python
- Овладей Python, создавая реальные приложения. Часть 1
Перевод статьи Parul PandeyUseful String Method
Ljust (): как оставить – обосновать строку в Python
Используйте покинуть – оправдать строку.
word = 'beach' number_spaces = 32 word_justified = word.ljust(number_spaces) print(word) #'beach' print(word_justified) #'beach '
Обратите внимание на пробелы во второй строке. Слово «Beach» имеет 5 символов, что дает 27 пространства для заполнения пустым пространством
Оригинал Переменная остается неизменным, поэтому нам нужно назначить возврат метода новой переменной, в таком случае.
Также принимает определенный символ в качестве параметра для заполнения оставшегося пространства.
word = 'beach' number_chars = 32 char = '$' word_justified = word.ljust(number_chars, char) print(word) #beach print(word_justified) #beach$$$$$$$$$$$$$$$$$$$$$$$$$$$
Похоже на первую ситуацию, у меня есть 27 Знаки, чтобы сделать его 32, когда я считаю 5 символов, содержащихся в словом «Beach».
Мир регулярных выражений
Иногда непросто очистить текст с помощью определенных символов или фраз. Вместо этого нам необходимо использовать некоторые шаблоны. И здесь нам на помощь приходят регулярные выражения и соответствующий модуль Python.
Мы не будем обсуждать всю мощь регулярных выражений, а сосредоточимся на их применении — например, на разделении и замене данных. Да, эти задачи были описаны выше, но вот более мощная альтернатива.
Разделение по шаблону:
import re
test_punctuation = " This &is example? {of} string. with.? punctuation!!!! "
re.split('\W+', test_punctuation)
Out:
Замена по шаблону:
import re
test_with_numbers = "This is 1 string with 10 words for 9 digits 2 example"
re.sub('\d', '*', test_with_numbers)
Out: 'This is * string with ** words for * digits * example'
Методы join(), split() и replace()
Методы str.join(), str.split() и str.replace() предлагают несколько дополнительных способов управления строками в Python.
Метод str.join() – один из методов конкатенации (слияния) двух строк в Python. Метод str.join(string) собирает строку string с разделителем str.
Чтобы понять, как это работает, создайте сроку:
Теперь попробуйте применить метод str.join(), где str – пробел:
Попробуйте вывести такую строку:
Чтобы вывести символы оригинальной строки в обратном порядке, введите:
Метод str.join() также может объединять список строк в одну новую строку.
Чтобы добавить пробелы и запятые после заданных строк, нужно просто переписать выражение и внеси запятую в качестве разделителя:
Метод str.split() позволяет делить строки:
Метод str.split() позволяет удалять части строк. К примеру, попробуйте удалить букву s:
Метод str.replace() может обновлять строку и заменять устаревшую версию строки новой.
Для примера попробуйте заменить слово is в строке “This is a dummy string.” cловом was.
В круглых скобках сначала указывается слово, которое нужно заменить, а затем слово, которое нужно использовать вместо первого. В результате получится:
This was a dummy string.
Методы для работы со строками
Кроме функций, для работы со строками есть немало методов:
- – возвращает индекс первого вхождения подстроки в s или -1 при отсутствии. Поиск идет в границах от до ;
- – аналогично, но возвращает индекс последнего вхождения;
- – меняет последовательность символов на новую подстроку ;
- – разбивает строку на подстроки при помощи выбранного разделителя x;
- – соединяет строки в одну при помощи выбранного разделителя x;
- – убирает пробелы с обеих сторон;
- – убирает пробелы только слева или справа;
- – перевод всех символов в нижний регистр;
- – перевод всех символов в верхний регистр;
- – перевод первой буквы в верхний регистр, остальных – в нижний.
Примеры использования:
Вводная информация о строках
Как и во многих других языках программирования, в Python есть большая коллекция функций, операторов и методов, позволяющих работать со строковым типом.
Литералы строк
Литерал – способ создания объектов, в случае строк Питон предлагает несколько основных вариантов:
Если внутри строки необходимо расположить двойные кавычки, и сама строка была создана с помощью двойных кавычек, можно сделать следующее:
Разницы между строками с одинарными и двойными кавычками нет – это одно и то же
Какие кавычки использовать – решать вам, соглашение PEP 8 не дает рекомендаций по использованию кавычек. Просто выберите один тип кавычек и придерживайтесь его. Однако если в стоке используются те же кавычки, что и в литерале строки, используйте разные типы кавычек – обратная косая черта в строке ухудшает читаемость кода.
Кодировка строк
В третьей версии языка программирования Python все строки представляют собой последовательность Unicode-символов.
В Python 3 кодировка по умолчанию исходного кода – UTF-8. Во второй версии по умолчанию использовалась ASCII. Если необходимо использовать другую кодировку, можно разместить специальное объявление на первой строке файла, к примеру:
Максимальная длина строки в Python
Максимальная длина строки зависит от платформы. Обычно это:
- 2**31 — 1 – для 32-битной платформы;
- 2**63 — 1 – для 64-битной платформы;
Константа , определенная в модуле
Конкатенация строк
Одна из самых распространенных операций со строками – их объединение (конкатенация). Для этого используется знак , в результате к концу первой строки будет дописана вторая:
При необходимости объединения строки с числом его предварительно нужно привести тоже к строке, используя функцию
Сравнение строк
При сравнении нескольких строк рассматриваются отдельные символы и их регистр:
- цифра условно меньше, чем любая буква из алфавита;
- алфавитная буква в верхнем регистре меньше, чем буква в нижнем регистре;
- чем раньше буква в алфавите, тем она меньше;
При этом сравниваются по очереди первые символы, затем – 2-е и так далее.
Далеко не всегда желательной является зависимость от регистра, в таком случае можно привести обе строки к одному и тому же регистру. Для этого используются функции – для приведения к нижнему и – к верхнему:
Как удалить строку в Python
Строки, как и некоторые другие типы данных в языке Python, являются неизменяемыми объектами. При задании нового значения строке просто создается новая, с заданным значением. Для удаления строки можно воспользоваться методом , заменив ее на пустую строку:
Или перезаписать переменную пустой строкой:
Обращение по индексу
Для выбора определенного символа из строки можно воспользоваться обращением по индексу, записав его в квадратных скобках:
Индекс начинается с 0
В Python предусмотрена возможность получить доступ и по отрицательному индексу. В таком случае отсчет будет вестись от конца строки:
Основы строки Python
Тип является одним из наиболее распространенных типов и часто называют строка Или, в Python, просто
my_city = "New York"
print(type(my_city))
#Single quotes have exactly
#the same use as double quotes
my_city = 'New York'
print(type(my_city))
#Setting the variable type explicitly
my_city = str("New York")
print(type(my_city))
Как объединять строки
Вы можете использовать Оператор к объединенным строкам.
ConcateNation – это когда у вас есть две или более строки, и вы хотите присоединиться к ним в один.
word1 = 'New ' word2 = 'York' print(word1 + word2)
New York
Как выбрать CHAR
Чтобы выбрать CHAR, используйте и укажите положение CHAR.
Положение 0 относится к первой позиции.
>>> word = "Rio de Janeiro" >>> char=word >>> print(char) R
Функция возвращает длину строки.
>>> len('Rio')
3
>>> len('Rio de Janeiro')
14
Как заменить часть строки
Способ заменяет часть строки другой. В качестве примера давайте заменим «Рио» на «Мар».
>>> 'Rio de Janeiro'.replace('Rio', 'Mar')
'Mar de Janeiro'
Рио означает реку на португальском и Мар означает море – просто так вы знаете, что я не выбрал эту замену так случайно.
Как считать
Укажите, что рассчитывать как аргумент.
В этом случае мы считаем, сколько пробелов существует в «Рио-де-Жанейро», который является 2.
>>> word = "Rio de Janeiro"
>>> print(word.count(' '))
2
Как повторить строку
Вы можете использовать Символ, чтобы повторить строку.
Здесь мы умножаем слово «Токио» на 3.
>>> words = "Tokyo" * 3 >>> print(words) TokyoTokyoTokyo
Методы строк
Строка является объектом в Python. Фактически, все, что есть в Python – является объектом. Если вы хотите узнать больше об Объектно-ориентированном программирование, мы рассмотрим это в другой статье «Классы в Python«. В данный момент достаточно знать, что строки содержат собственные встроенные методы. Например, допустим, у вас есть следующая строка:
Python
my_string = «This is a string!»
| 1 | my_string=»This is a string!» |
Теперь вам нужно сделать так, чтобы вся эта строка была в верхнем регистре. Чтобы сделать это, все, что вам нужно, это вызвать метод upper(), вот так:
Python
my_string.upper()
| 1 | my_string.upper() |
Если вы открыли ваш интерпретатор, вы также можете сделать то же самое:
Python
«This is a string!».upper()
| 1 | «This is a string!».upper() |
Существует великое множество других методов строк. Например, если вам нужно, что бы все было в нижнем регистре, вам нужно использовать метод lower(). Если вы хотите удалить все начальные и конечные пробелы, вам понадобится метод strip(). Для получения списка всех методов строк, впишите следующую команду в ваш интерпретатор:
Python
dir(my_string)
| 1 | dir(my_string) |
Вы увидите что-то на подобие этого:
Python
|
1 2 3 4 5 6 7 8 9 10 |
‘__add__’,‘__class__’,‘__contains__’,‘__delattr__’,‘__doc__’,‘__eq__’,‘__format__’, ‘__ge__’,‘__getattribute__’,‘__getitem__’,‘__getnewargs__’,‘__getslice__’,‘__gt__’, ‘__hash__’,‘__init__’,‘__le__’,‘__len__’,‘__lt__’,‘__mod__’,‘__mul__’,‘__ne__’, ‘__new__’,‘__reduce__’,‘__reduce_ex__’,‘__repr__’,‘__rmod__’,‘__rmul__’,‘__- setattr__’,‘__sizeof__’,‘__str__’,‘__subclasshook__’,‘_formatter_field_name_split’, ‘_formatter_parser’,‘capitalize’,‘center’,‘count’,‘decode’,‘encode’,‘endswith’,‘expandtabs’, ‘find’,‘format’,‘index’,‘isalnum’,‘isalpha’,‘isdigit’,‘islower’,‘isspace’, ‘istitle’,‘isupper’,‘join’,‘ljust’,‘lower’,‘lstrip’,‘partition’,‘replace’,‘rfind’,‘rindex’, ‘rjust’,‘rpartition’,‘rsplit’,‘rstrip’,‘split’,‘splitlines’,‘startswith’,‘strip’,‘swapcase’, ‘title’,‘translate’,‘upper’,‘zfill’ |
Вы можете спокойно игнорировать методы, которые начинаются и заканчиваются двойным подчеркиванием, например __add__. Они не используются в ежедневном программировании в Python
Лучше обратите внимание на другие. Если вы хотите узнать, что делает тот или иной метод, просто обратитесь к справке
Например, если вы хотите узнать, зачем вам capitalize, впишите следующее, чтобы узнать:
Python
help(my_string.capitalize)
| 1 | help(my_string.capitalize) |
Вы получите следующую информацию:
Python
Help on built-in function capitalize:
capitalize(…)
S.capitalize() -> string
Выдача копии строки S только с заглавной буквой.
|
1 2 3 4 5 6 |
Help on built-in function capitalize: capitalize(…) S.capitalize() -> string Выдача копии строки S только с заглавной буквой. |
Вы только что узнали кое-что о разделе, под названием интроспекция. Python может исследовать все свои объекты, что делает его очень легким в использовании. В основном, интроспекция позволяет вам спрашивать Python о нём. Вам моет быть интересно, как сказать о том, какой тип переменной был использован (другими словами int или string). Вы можете спросить об этом у Python!
Python
type(my_string) # <type ‘str’>
| 1 | type(my_string)# <type ‘str’> |
Как вы видите, тип переменной my_string является str!
