Как изменить кодировку текстового файла на utf-8 или windows 1251
Содержание:
- Введение
- 1.2 Чередующиеся сигналы
- Как сменить кодировку в консоли windows?
- Cворачивание регистра
- Сайты для перекодировки онлайн
- Консоль Внедренца v.3.6.2
- Как изменить кодировку символов в Microsoft Word?
- Групповая обработка прикрепленных файлов
- Зачем эта статья?
- Поднимет ли уникальность замена букв на символы иностранного алфавита
- Выбор кодировки при сохранении файла
- Работа с картами 1С 4 в 1: Яндекс, Google , 2ГИС, OpenStreetMap(OpenLayers) Промо
- Кодировка
- Поиск кодировок, доступных в Word
- Изменение кодировки в программе «Notepad ++»
- Заключение
Введение
С появлением первых устройств цифровой передачи информации и электронно-вычислительных машин возникла задача кодирования текстовых символов с помощью последовательностей единиц и нулей. Минимальная единица представления информации – байт. Исходя их этого в 1963 году в США разработана, стандартизована, а впоследствии расширена кодовая таблица ASCII (American standard code for information interchange), использовавшая 8 битную кодировку. В первую очередь с помощью этой таблицы предполагалось кодирование цифр и букв английского языка. Первые 128 символов таблицы представлены на рис.1:
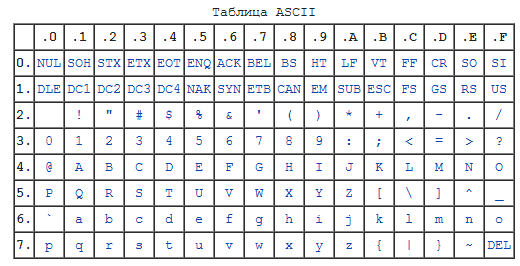 Рис.1. Первые 128 символов таблицы ASCII.
Рис.1. Первые 128 символов таблицы ASCII.
Номер ячейки в таблице (рис.1) является кодом символа. В качестве примера рассмотрим кодирование слова Hello. Номера ячеек таблицы ASCII, в которых размещены буквы: 72 (H), 101 (e), 108 (l), 111 (o). Код слова в бинарном представлении выглядит следующим образом:
00010010 (H) 10100110 (e) 00110110 (l) 00110110 (l) 11110110 (o) (старший бит справа).
Выделенные подчеркиванием и жирным коды в двоичном представлении соответствуют номерам ячеек в таблице (рис.1). Алгоритм формирования кода следующий:
1. Выделены жирным – биты управления кодированием (префикс). 010 – кодируется заглавная буква алфавита, 011 – строчная.
2. Выделены подчеркиванием – порядковые номера букв в английском алфавите.
Таким образом, с помощью первых 128 ячеек таблицы ASCII могли быть закодированы основные символы, цифры и буквы английского языка. Остальные 128 ячеек (8 битная кодировка позволяет закодировать 256 символов) могли использоваться для кодирования других языков. Однако, учитывая разнообразие символов и языков, 8 бит недостаточно.
1.2 Чередующиеся сигналы
 Индеец пингует
Индеец пингует
В примитивном виде кодирование чередующимися сигналами используется человечеством очень давно. В предыдущем разделе мы сказали про дым и огонь. Если между наблюдателем и источником огня ставить и убирать препятствие, то наблюдателю будет казаться, что он видит чередующиеся сигналы «включено/выключено». Меняя частоту таких включений мы можем выработать последовательность кодов, которая будет однозначно трактоваться принимающей стороной.
Наряду с сигнальными флажками на морских и речных судах, при появлении радио начали использовать код Морзе. И при всей кажущейся бинарности (представление кода двумя значениями), так как используются сигналы точка и тире, на самом деле это тернаный код, так как для разделения отдельных кодов-символов требуется пауза в передаче кода. То есть код Морзе кроме «точка-тире», что нам даёт букву «A» может звучать и так — «точка-пауза-тире» и тогда это уже две буквы «ET».

Как сменить кодировку в консоли windows?
Файл должен выводиться в utf-8, а в консоли – 866, в итоге в браузере отображаются ромбы.
После команды chcp 65001 ничего не поменялось.
Но у меня в CodePage таких файлов нет. Есть типы REG.SZ по умолчанию и 4 файла с номерами 932 936 949 950
Вариант постоянно изменять в консоли chcp не подходит, но и не работает. Lucida console подключен в консоли. Cygwin64 Terminal и Gitbash не запускает python server
Какие-то ещё есть варианты?
generate.py
horoscope.py
При запуске кода (python generate_all.py из командной строки или Ctrl B в саблайме) в этой же папке генерируется файл index.html, и, если поднять сервер в этой же директории (python -m http.server) из консоли win, то в браузере ромбы.
Cворачивание регистра
Сворачивание регистра — это попытка унифицировать текст любого представления к канонической форме. Например, приведение всего текста в нижний регистр. Также над текстом производятся некоторые преобразования (например, немецкая «эсцет» — «ß» — преобразуется в «ss»). В Python 3.3 появился метод , который как раз выполняет сворачивание регистра. Если текст содержит только символы кодировки , результат применения этого метода будет аналогичен методу .
И по классике приведём пример:
В результате применённый метод не только привёл весь текст к нижнему регистру, но и преобразовал специфический немецкий символ.
Важный поинт: привести текст можно не только методом , но и методом , который может выполнить дополнительные преобзования текста.
Сайты для перекодировки онлайн
Сегодня мы расскажем о самых популярных и действенных сайтах, которые помогут угадать кодировку и изменить ее на более понятную для вашего ПК. Чаще всего на таких сайтах работает автоматический алгоритм распознавания, однако в случае необходимости пользователь всегда может выбрать подходящую кодировку в ручном режиме.
Способ 1: Универсальный декодер
Декодер предлагает пользователям просто скопировать непонятный отрывок текста на сайт и в автоматическом режиме переводит кодировку на более понятную. К преимуществам можно отнести простоту ресурса, а также наличие дополнительных ручных настроек, которые предлагают самостоятельно выбрать нужный формат.
Работать можно только с текстом, размер которого не превышает 100 килобайт, кроме того, создатели ресурса не гарантируют, что перекодировка будет в 100% случаев успешной. Если ресурс не помог – просто попробуйте распознать текст с помощью других способов.
- Копируем текст, который нужно декодировать, в верхнее поле. Желательно, чтобы в первых словах уже содержались непонятные символы, особенно в случаях, когда выбрано автоматическое распознавание.
- Указываем дополнительные параметры. Если необходимо, чтобы кодировка была распознана и преобразована без вмешательства пользователя, в поле «Выберите кодировку» щелкаем на «Автоматически». В расширенном режиме можно выбрать начальную кодировку и формат, в который нужно преобразовать текст. После завершения настройки щелкаем на кнопку «ОК».
- Преобразованный текст отобразится в поле «Результат», оттуда его можно скопировать и вставить в документ для последующего редактирования.
Способ 2: Студия Артемия Лебедева
Еще один сайт для работы с кодировкой, в отличие от предыдущего ресурса имеет более приятный дизайн. Предлагает пользователям два режима работы, простой и расширенный, в первом случае после декодировки пользователь видит результат, во втором случае видна начальная и конечная кодировка.
- Выбираем режим декодировки на верхней панели. Мы будем работать с режимом «Сложно», чтобы сделать процесс более наглядным.
- Вставляем нужный для расшифровки текст в левое поле. Выбираем предполагаемую кодировку, желательно оставить автоматические настройки — так вероятность успешной дешифровки возрастет.
- Щелкаем на кнопку «Расшифровать».
- Результат появится в правом поле. Пользователь может самостоятельно выбрать конечную кодировку из ниспадающего списка.
С сайтом любая непонятная каша из символов быстро превращается в понятный русский текст. На данный момент работает ресурс со всеми известными кодировками.
Способ 3: Fox Tools
Fox Tools предназначен для универсальной декодировки непонятных символов в обычный русский текст. Пользователь может самостоятельно выбрать начальную и конечную кодировку, есть на сайте и автоматический режим.
Дизайн простой, без лишних наворотов и рекламы, которая мешает нормальной работе с ресурсом.
- Вводим исходный текст в верхнее поле.
- Выбираем начальную и конечную кодировку. Если данные параметры неизвестны, оставляем настройки по умолчанию.
- После завершения настроек нажимаем на кнопку «Отправить».
- Из списка под начальным текстом выбираем читабельный вариант и щелкаем на него.
- Вновь нажимаем на кнопку «Отправить».
- Преобразованный текст будет отображаться в поле «Результат».
Несмотря на то, что сайт якобы распознает кодировку в автоматическом режиме, пользователю все равно приходится выбирать понятный результат в ручном режиме. Из-за данной особенности куда проще воспользоваться описанными выше способами.
Рассмотренный сайты позволяют всего в несколько кликов преобразовать непонятный набор символов в читаемый текст. Самым практичным оказался ресурс Универсальный декодер — он безошибочно перевел большинство зашифрованных текстов.
Опишите, что у вас не получилось.
Наши специалисты постараются ответить максимально быстро.
Консоль Внедренца v.3.6.2
Идея данной обработки заключается в создании простого, функционального и универсального инструментария для внедренцев и программистов 1С, который будет работать как в толстом клиенте на обычных и на управляемых формах, так и в тонком клиенте. Интерфейс и логика работы максимально идентичны у обычных форм и управляемых. Инструментарий включает в себя: Консоль кода, Консоль запросов, Консоль отчетов (СКД), Универсальную обработку объектов, Средства для работы с таблицами базы данных 1С, Редактирование регистров сведений базы, Инструмент по работе с табличными документами — загрузка данных из табличного документа.
1 стартмани
Как изменить кодировку символов в Microsoft Word?
Каждый раз, когда вы открываете несовместимый документ, Word будет отображать диалог преобразования файла. Однако, если вы его не видите, эту опцию легко включить. Вы можете открыть любой документ Word, чтобы включить этот параметр, так как он будет применен ко всем документам.
Включение диалогового окна преобразования формата файла
- Откройте документ и перейдите в меню «Файл> Параметры».
- Щелкните раздел «Дополнительно» и прокрутите вниз до раздела «Общие» на правой панели.
- По умолчанию Word отключает параметр «Подтверждать преобразование формата файла при открытии».
- Установите флажок, чтобы включить эту опцию.
- Нажмите «ОК», чтобы применить изменения и закрыть все открытые документы.
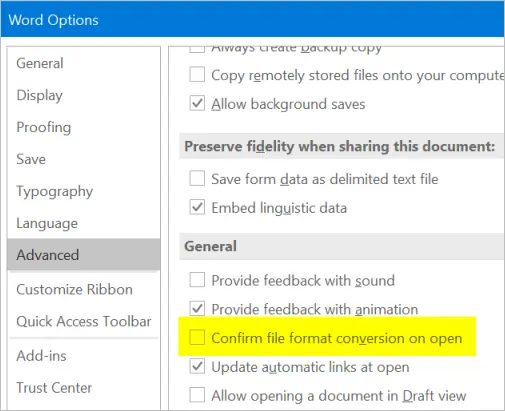
Подтвердить преобразование формата файла при открытии
Этот параметр поможет вам запускать диалоговое окно при открытии файлов в форматах, отличных от .doc или .docx. Например, если вы используете Word для открытия обычного текстового файла с расширением .txt, вы получите запрос на проверку формата файла.
Связанный: Как изменить имя встроенного файла в Word?
Изменить кодировку символов
Теперь откройте файл, в котором вы хотите изменить кодировку символов. Word покажет вам диалоговое окно «Преобразовать файл», как показано ниже.
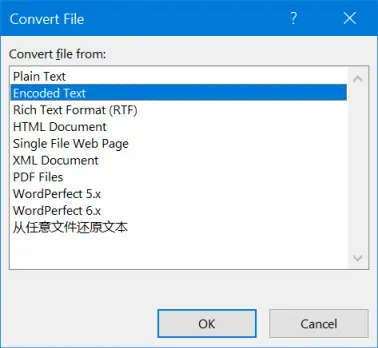
Конвертировать файл
Выберите формат файла, если вам нравится обычный текст или документ HTML. Если вам непонятно, выберите опцию «Закодированный текст» и нажмите кнопку «ОК». Затем вы увидите диалоговое окно «Преобразование файла». Как правило, «Windows (по умолчанию)» выбирает кодировку в зависимости от настроек локали. Это может создать проблемы при просмотре специальных символов и знаков.
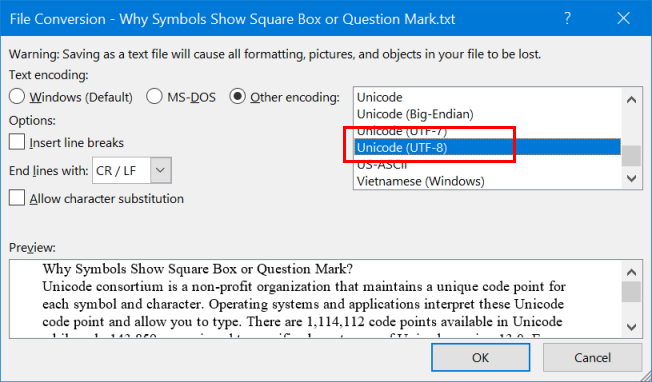
Преобразование файлов с изменением кодировки
Выберите «Другая кодировка», чтобы активировать список рядом. Вы увидите список доступных в списке вариантов кодировки и выберите формат «Unicode (UTF-8)». При необходимости выберите вставку разрывов строк и разрешите варианты замены символов. Нажмите «ОК», чтобы завершить процесс. Теперь вы успешно изменили кодировку символов файла на UTF-8.
Это поможет вам просматривать содержимое файла в удобочитаемом формате, так как UTF-8 должен поддерживать большинство символов.
Отключить преобразование файлов
После того, как вы закончите изменять кодировку символов файла, обязательно отключите опцию преобразования файла. Вернитесь в «Файл> Параметры» и измените настройки в разделе «Дополнительно». Это поможет вам в будущем отключить диалог преобразования файлов.
Групповая обработка прикрепленных файлов
Кому не знакомы авралы в бухгалтерии, когда налоговая требует представить копии всех документов за два-три года? Кто не получал сюрпризов в виде отсутствия документов, когда завтра их нужно уже представлять проверяющим? 1С предлагает прикрепление и хранение копий документов (в том числе со сканера) в базе, а данная обработка решает вопрос их быстрой подборки, сортировки и выгрузки, а также быстрого и эффективного контроля наличия или отсутствия документов в базе с формированием реестров как выгруженных, так и отсутствующих документов.
В настоящий момент обработка бесплатна, в дальнейшем планируется платная версия с расширенными возможностями.
Скажите решительное «Нет» авралам в бухгалтерии и штрафам за несвоевременное представление документов!
4 стартмани
Зачем эта статья?
Об обработке текстов на естественном языке сейчас знают все. Все хоть раз пробовали задавать вопрос Сири или Алисе, пользовались Grammarly (это не реклама), пробовали генераторы стихов, текстов… или просто вводили запрос в Google. Да, вот так просто. На самом деле Google понимает, что вы от него хотите, благодаря штукам, которые умеют обрабатывать и анализировать естественную речь в вашем запросе.
При анализе текста мы можем столкнуться с ситуациями, когда текст содержит специфические символы, которые необходимо проанализировать наравне с «простым текстом» (взять даже наши горячо любимые вставки на французском из «Война и мир») или формулы, например. В таком случае обработка текста может усложниться.
Вы можете заметить, что если ввести в поисковую строку запрос с символами с ударением (так называемый модифицирующий акут), к примеру «ó», поисковая система может показать результаты, содержащие слова из вашего запроса, символы с ударением уже выглядят как обычные символы.
Обратите внимание на следующий запрос:

Запрос содержит символ с модифицирующим акутом, однако во втором результате мы можем заметить, что выделено найденное слово из запроса, только вот оно не содержит вышеупомянутый символ, просто букву «о».
Конечно, уже есть много готовых инструментов, которые довольно неплохо справляются с обработкой текстов и могут делать разные крутые вещи, но я не об этом хочу вам поведать. Я не буду рассказывать про nltk, стемминг, лемматизацию и т.п. Я хочу опуститься на несколько ступенек ниже и обсудить некоторые тонкости кодировок, байтов, их обработки.
Поднимет ли уникальность замена букв на символы иностранного алфавита
Иногда пользователи, пишущие контент, повышают процент антиплагиата следующим способом. Они просто меняют часть символов на похожие латинские знаки. Например, вписывают вместо А, В, О, Р и т. д. одинаковые по написанию буквы английского алфавита.
Такие знаки легко можно увидеть и в Word. Если скопировать в него скачанный контент, то эти символы будут подчеркнуты красным или другим цветом.
Но большинство программ нацелено на проверку только английских букв в русскоязычных текстах. Поэтому если взять похожие знаки других стран с алфавитом, отличным от латинского, то система может не распознать подмены и процент окажется высоким.
 Программа может распознать замену некоторых символов латиницей.
Программа может распознать замену некоторых символов латиницей.
Выбор кодировки при сохранении файла
Если не выбрать кодировку при сохранении файла, будет использоваться Юникод. Как правило, рекомендуется применять Юникод, так как он поддерживает большинство символов большинства языков.
Если документ планируется открывать в программе, которая не поддерживает Юникод, вы можете выбрать нужную кодировку. Например, в операционной системе на английском языке можно создать документ на китайском (традиционное письмо) с использованием Юникода. Однако если такой документ будет открываться в программе, которая поддерживает китайский язык, но не поддерживает Юникод, файл можно сохранить в кодировке «Китайская традиционная (Big5)». В результате текст будет отображаться правильно при открытии документа в программе, поддерживающей китайский язык (традиционное письмо).
Примечание:
Так как Юникод — это наиболее полный стандарт, при сохранении текста в других кодировках некоторые знаки могут не отображаться. Предположим, например, что документ в Юникоде содержит текст на иврите и языке с кириллицей. Если сохранить файл в кодировке «Кириллица (Windows)», текст на иврите не отобразится, а если сохранить его в кодировке «Иврит (Windows)», то не будет отображаться кириллический текст.
Если выбрать стандарт кодировки, который не поддерживает некоторые символы в файле, Word пометит их красным. Вы можете просмотреть текст в выбранной кодировке перед сохранением файла.
При сохранении файла в виде кодированного текста из него удаляется текст, для которого выбран шрифт Symbol, а также коды полей.
https://youtube.com/watch?v=bpunJ3_Wncg
Работа с картами 1С 4 в 1: Яндекс, Google , 2ГИС, OpenStreetMap(OpenLayers) Промо
С каждым годом становится все очевидно, что использование онлайн-сервисов намного упрощает жизнь. К сожалению по картографическим сервисам условия пока жестковаты. Но, ориентируясь на будущее, я решил показать возможности API выше указанных сервисов:
Инициализация карты
Поиск адреса на карте с текстовым представлением
Геокодинг
Обратная поиск адреса по ее координатами
Взаимодействие с картами — прием координат установленного на карте метки
Построение маршрутов по указанным точками
Кластеризация меток на карте при увеличении масштаба
Теперь также поддержка тонкого и веб-клиента
1 стартмани
Кодировка
Думаю, это не будет сюрпризом, если я скажу, что любой символ, который заносится в память компьютера, хранится в виде числа, а не в виде литерала. Это число определяется как идентификатор или кодовая позиция символа. Кодировка определяет, какое именно число будет ассоциировано с символом.
Предположим, у нас есть некоторый файл с неизвестным содержимым, и нам нужно его прочитать, однако мы не знаем, какая у файла кодировка. Попробуем декодировать содержимое файла.
Посмотрим на результат:
Очень интересно, ничего непонятно. По умолчанию Python использует кодировку utf-8, но видимо запись в файл происходила не с её помощью. Здесь нам придёт на помощь дополнительный параметр функции open — параметр encoding, который позволяет указать конкретную кодировку, в которой следует прочитать файл (или записывать в него). Попробуем перебрать несколько кодировок и найти подходящую.
Результат:
Разные кодировки расшифровывают байты из файла по-разному, то есть разным кодовым позициям могут соотвествовать разные символы. Пример примитивный, несложно догадаться, что истинная кодировка файла — это utf-16.
Важный поинт: при записи и чтении из файлов следует указывать конкретную кодировку, это позволит избежать путаницы в дальнейшем.
Поиск кодировок, доступных в Word
Word распознает несколько кодировок и поддерживает кодировки, которые входят в состав системного программного обеспечения.
Ниже приведен список письменностей и связанных с ними кодировок (кодовых страниц).
|
Система письменности |
Кодировки |
Используемый шрифт |
|---|---|---|
|
Многоязычная |
Юникод (UCS-2 с прямым и обратным порядком байтов, UTF-8, UTF-7) |
Стандартный шрифт для стиля «Обычный» локализованной версии Word |
|
Арабская |
Windows 1256, ASMO 708 |
|
|
Китайская (упрощенное письмо) |
GB2312, GBK, EUC-CN, ISO-2022-CN, HZ |
|
|
Китайская (традиционное письмо) |
BIG5, EUC-TW, ISO-2022-TW |
|
|
Кириллица |
Windows 1251, KOI8-R, KOI8-RU, ISO8859-5, DOS 866 |
|
|
Английская, западноевропейская и другие, основанные на латинице |
Windows 1250, 1252-1254, 1257, ISO8859-x |
|
|
Греческая |
||
|
Японская |
Shift-JIS, ISO-2022-JP (JIS), EUC-JP |
|
|
Корейская |
Wansung, Johab, ISO-2022-KR, EUC-KR |
|
|
Вьетнамская |
||
|
Индийские: тамильская |
||
|
Индийские: непальская |
ISCII 57002 (деванагари) |
|
|
Индийские: конкани |
ISCII 57002 (деванагари) |
|
|
Индийские: хинди |
ISCII 57002 (деванагари) |
|
|
Индийские: ассамская |
||
|
Индийские: бенгальская |
||
|
Индийские: гуджарати |
||
|
Индийские: каннада |
||
|
Индийские: малаялам |
||
|
Индийские: ория |
||
|
Индийские: маратхи |
ISCII 57002 (деванагари) |
|
|
Индийские: панджаби |
||
|
Индийские: санскрит |
ISCII 57002 (деванагари) |
|
|
Индийские: телугу |
Для использования индийских языков необходима их поддержка в операционной системе и наличие соответствующих шрифтов OpenType.
Для непальского, ассамского, бенгальского, гуджарати, малаялам и ория доступна только ограниченная поддержка.
Иногда открыв файл, созданный при помощи Microsoft Word и присланный нам по почте, скайпу или другим способом, мы вместо привычных русских слов видим какие-то странные иероглифы. Мы недоумеваем, что же такое нам прислали, связываемся с отправителем, а он говорит, что у него все нормально открывается. Суть данной проблемы скорее всего состоит в том, что файл был сохранен не в той кодировке, что стоит по умолчанию в вашей программе. Чтобы исправить ситуацию необходимо всего лишь поменять кодировку файла и сейчас мы узнаем, как это сделать.
В данном примере будет использоваться Microsoft Word 2010 но принцип решения нашей задачи будет таким же и во всех остальных версиях программы. Итак, открываем наш «проблемный» документ, переходим в меню Файл
и нажимаем на пункте Параметры
.

Нажимаем Ок
и закрываем наш документ. Затем снова открываем его и перед нами должно появится окошко Преобразование файла
, в нем нам нужно выбрать пункт Кодированный текст
.

После этого появится другое окно, в котором нам нужно будет выбрать кодировку для своего файла. Ставим галочку на пункте Другая
и в поле выбора пробуем методом перебора различные кодировки, до тех пор пока не получим результат. В окне Результат
вы можете увидеть, как меняется текст в зависимости от выбранной вами кодировки.

Если вышеописанный метод не помог исправить проблему, то возможно она кроется не в неправильной кодировке, а в отсутствии на вашем компьютере шрифта, с использованием которого создавался данный документ. В таком случае вам придется уточнить у отправителя документа название шрифта и установить нужный шрифт на свой компьютер.
Остались вопросы? — Мы БЕСПЛАТНО ответим на них в
Каким образом компьютер способен воспринимать, разделять и распознавать всё множество команд? Все символы, которыми мы пользуемся, представляют собой набор чисел. Другими словами, каждая буква и любой другой знак имеет своё обозначение в виде числа. Так компьютерной системе гораздо легче и быстрее обрабатывать информацию. Но не стоит забывать о том, что в мире множество языков, а для обозначения команд используется всего 256 символов. Поэтому существуют различные кодировки.
Кодировка
— это способ сохранения информации, данных для последующего использования. Если на экране мы видим набор непонятных нам букв, это означает, что кодировка выбрана неправильно. И эти самые 256 цифр обозначают символы, записанные под их значениями, на иностранном языке. При возникновении этой проблемы компьютер при открытии файла предлагает изменить кодировку на другую, имеющуюся у него. Обычно кодировка определяется автоматически по выбранному языку (раскладке клавиатуры) на компьютере.
Изменение кодировки в программе «Notepad ++»
Подобное приложение используется многими программистами для создания сайтов, различных приложений и многого другого
Поэтому очень важно сохранять и создавать файлы, используя необходимую кодировку. Для того, чтобы настроить нужный вариант для пользователя, следует:
Шаг 1. Запустить программу и в верхнем контекстном меню выбрать вкладку «Кодировки».

Выбираем вкладку «Кодировки»
Шаг 2. В выпадающем списке пользователю требуется выбрать из списка необходимую для него кодировку и щелкнуть на нее.

Выбираем из списка необходимую кодировку, щелкаем на ней
Шаг 3
Правильность проведения процедуры легко проверить, обратив внимание на нижнюю панель программы, которая будет отображать только что измененную кодировку

В нижней панели программы можно увидеть измененную кодировку
Заключение
Вопрос смены кодировки в Вордовских документах перед рядовыми пользователями встаёт не так уж часто. Как правило, текстовый процессор может сам автоматически определить требуемый для корректного отображения набор символов и показать текст в читаемом виде. Но из любого правила есть исключения, так что нужно и полезно уметь сделать это самому, благо, реализован процесс в Word достаточно просто.
То, что мы рассмотрели, действительно и для других программ из пакета Office. В них также могут возникнуть проблемы из-за, скажем, несовместимости форматов сохранённых файлов. Здесь пользователю придётся выполнить всё те же действия, так что эта статья может помочь не только работающим в Ворде. Унификация правил настройки для всех программ офисного пакета Microsoft помогает не запутаться в них при работе с любым видом документов, будь то тексты, таблицы или презентации.
Напоследок нужно сказать, что не всегда стоит обвинять кодировку. Возможно, всё гораздо проще. Дело в том, что многие пользователи в погоне за «красивостями» забывают о стандартизации. Если такой автор выберет установленный у него шрифт, наберёт с его помощью документ и сохранит, у него текст будет отображаться корректно. Но когда этот документ попадёт к человеку, у которого такой шрифт не установлен, то на экране окажется нечитаемый набор символов. Это очень похоже на «слетевшую» кодировку, так что легко ошибиться. Поэтому перед тем как пытаться раскодировать текст в Word, сначала попробуйте просто сменить шрифт.
